-
-

Real use-case from the Hong Kong protests
-

Test case from a previous hackathon
-
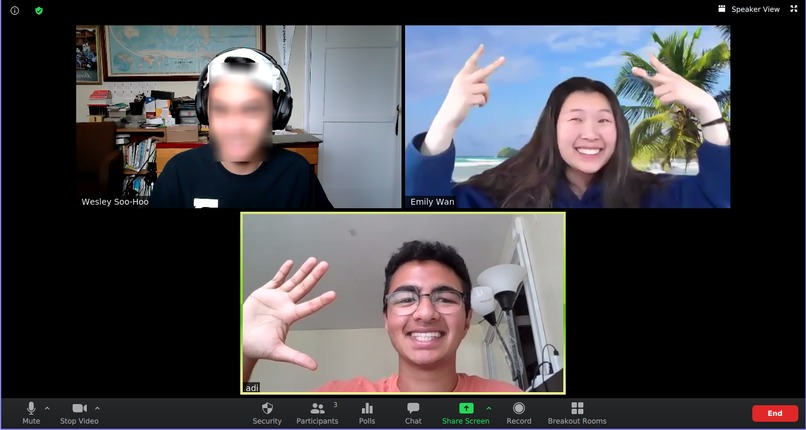
Running a blurred webcam capture on zoom


Inspiration
After watching a documentary of the Hong Kong protest and seeing the possible dangers of protesting online we realized that people's identity were at risk when they protested. The irony was that in many cases, the awareness the people were trying to bring by posting pictures and videos on social media were actually endangering the protesters on the front line more by exposing their faces. For example, in the case of Hong Kong protesters are extremely cautious of having their identity exposed, going so far as to cover their ears, back of the neck, tattoos, etc, anything they could be used against them in the face of the law. Though the media does sometimes censor the identity of protesters, when live footage is being streamed, it is often impossible to censor the identity of everyone in the background in real time.
What it does
Blurin8r is an app that processes a camera input and automatically blurs out faces. The output is then piped to a virtualized camera stream which can be used as a regular webcam for programs such as Zoom, Skype, or Facebook.

In addition, there is a web interface to edit the settings of the algorithm. The three settings we chose to be adjustible are the gaussian blur value, the blur sclaing factor, and the maximum size of the face. The gaussian blur value should be tuned to hide the identity of the face while still being smooth enough to see the background around the face. The blur scaling factor edits how big of an area around the face to blur, so the tops of the heads and necks can also be blurred out if necessary. Finally, the maximum size of the face can be used to isolate only the background faces for blurring. This is useful, for example, if the user would like their own face to be shown in the foreground while protecting the identity of those around him or her.
How I built it
The core algorithm has four main components: preprocessing, facial detection, blurring, and the virtual webcam.

Preprocessing
Before the image can be used, it must be preprocessed. To do this, it is first grabbed from an opencv video capture, then converted into a numpy array. The numpy array stores the pixel values in BGR format in a [X, Y, 3] array. Before running in the neural net, the image is then resized to a more manageable size and converted into grayscale. The resizing is necessary to reduce the number of necessary neurons on the input layer, therefore decreasing the overall size of the neural net and running faster.
Facial detection
The original method of facial detection that was attempted was using the stock haar cascade from opencv. While this worked on a few different use cases, it consistently missed faces. Any faces at an angle (profile view or tilted) or wearing sunglasses or a hat were not detected. Here is an example of a picture of my friends in Boston depicting a few missing detections:

While most of the faces are detected, there are a few missing. In our use case, we need consistent face blurring, as in a video, if one frame is missed, the privacy is lost.
To combat this, we used a neural network with the YOLO architecture. Here is the same image run through the trained neural network.

Originally, a YOLOv3 neural network was used, which resulted in a huge performance decrease (3FPS). After some research, we switched to a YOLOv3-tiny neural network, which had a near real time performance (20FPS).
The neural network weights were taken from this Github repository.
One thing to note about the facial detection is that this algorithm does not run facial recognition. This means that we do not identify who is in the background, we just identify that there is a face in that location. In addition, the original images are not stored, so the faces of those in the background stay hidden.
Blurring
Once the faces were found, a mask is created in the locations of the faces. The gaussian blur of the entire image is then merged with the original image using the np.where function, giving the effect of blurred out faces.


Virtual Webcam
Finally, to output the final image, a virtual webcam is created. We did this by using v4l2loopback, a dynamic kernel module which creates a virtualized camera capture source in /dev/video20. Then, from the python application, the final RGB values are piped into that source.
The reason why a virtual webcam had to be created was to allow compatibility with stock apps, such as Zoom, Skype, Twitch.tv, Youtube, or any other app that uses a webcam.

Challenges I ran into
We ran into a number of optimization issues with the YOLO neural network for face detection and blurring that prevent us from being able to stream real time video. However after performing some GPU optimizations and cutting the size of the neural network we were able to reduce lag significantly. We also had trouble getting the server and neural network code to run simultaneously - after learning about threading, processes, and how they were implemented in python, we integrated a Queue and Processes into our main python code and got the server up and working.
Accomplishments that I'm proud of
We are proud to say that there was an great amount of learning done by all team members.
Personally I had little to no website development experience before this hackathon , so I came into this project with the goal of having a deeper understanding of HTML, CSS and Java Script and how they all worked together. I went through numerous iterations of the website design and going from a basic black text to the website we have now is really rewarding.
We took this hackathon as an experience to learn as much as possible in a short amount of time. We learned a lot about web development, neural network optimization, creating webcam streams and writing over them, and how to enable and work with multiprocessing and multi-threading within python programs.
What's next for Blurin8r
We completed a MVP demo of the core algorithm during the hackathon, but there are many steps going forward. The first and most obvious is to implement some form or GPU hardware acceleration. The current code runs at about 20FPS on my laptop using the yolov3-tiny neural net. Running with hardware acceleration such as CUDA, there is an expected performance increase of 300%.
In addition, running the demo on a laptop is not near the final application of this algorithm. A more useful application would be on cell phones, especially as it is the most common camera source. Finally, we can extend this to run on the original intended platform: news cameras.
Read more
See our slide deck here: https://docs.google.com/presentation/d/1vpuOZA1IcWGVWcdjG47TVGtR2mzEhbXLzh_SPM77LDw/edit?usp=sharing




Log in or sign up for Devpost to join the conversation.