Inspiration
Surgeons practice safely on cadavers. Scientists don't discover cures in the press release. Yet, a entrepreneur's startup get pushed straight to the production without live market and people's feedback.
In this AI era building a startup is the new trend but over 90% of startups fail, and the number one reason is that founders build things nobody actually wants. We fall in love with our own ideas, talk to our friends, get a bunch of polite "that sounds awesome!" compliments, and then waste six months and thousands of dollars building a massive static backlog of features.
We were tired of traditional startup planners that either give you a generic, non-actionable checklist or immediately overwhelm you with administrative bloat. We wanted to build a "flight simulator" for founders—a platform that forces you to ruthlessly de-risk your ideas, audit your customer discovery, and run highly detailed multi-agent market simulations to stress-test your business model before you ever write a single line of production code.
Core Features
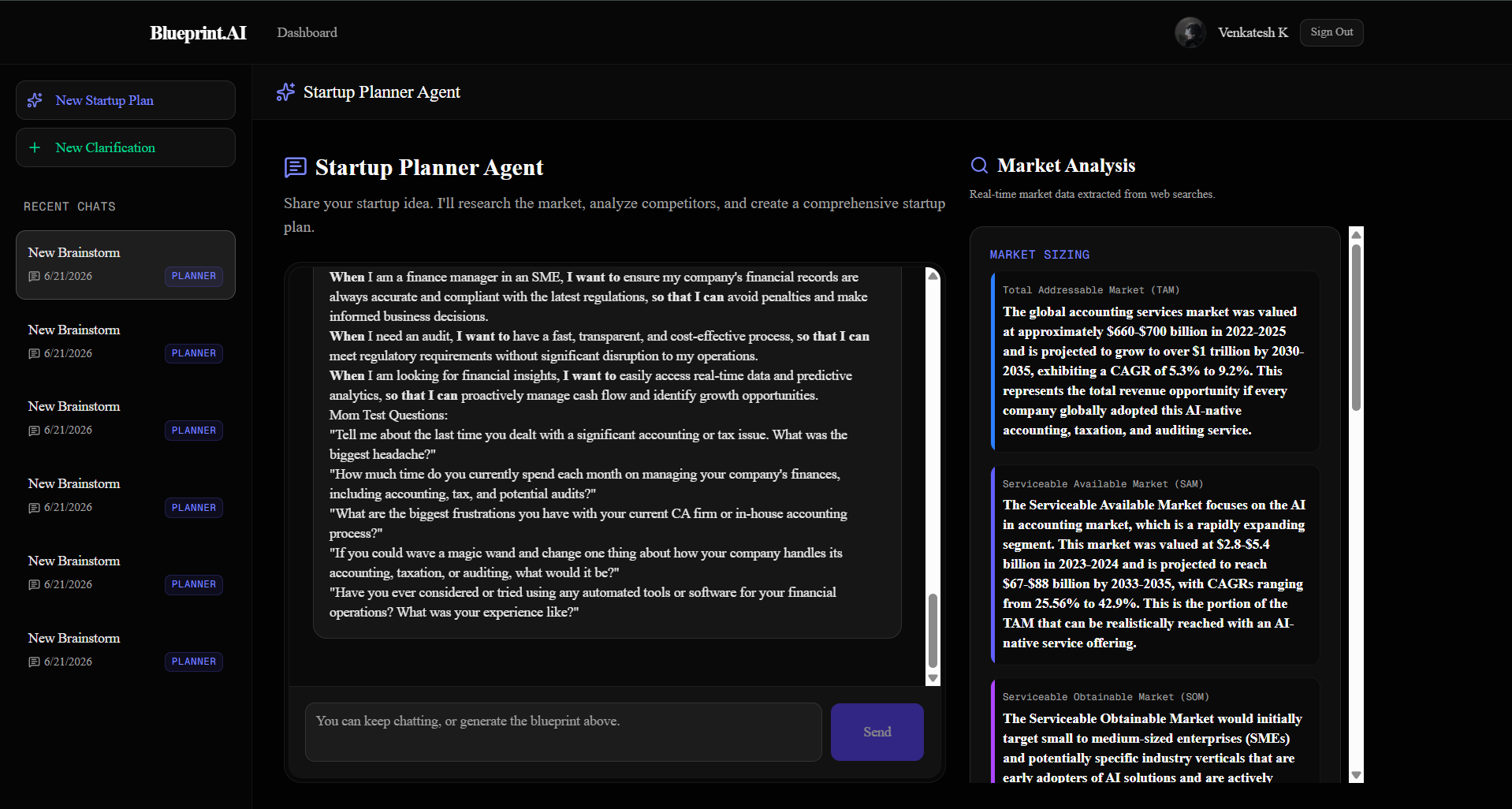
- Stateful Startup Planner Agent: A LangGraph-powered conversational agent that uses Tavily Search API to pull real-time market data (TAM, SAM, SOM) and competitor intelligence.
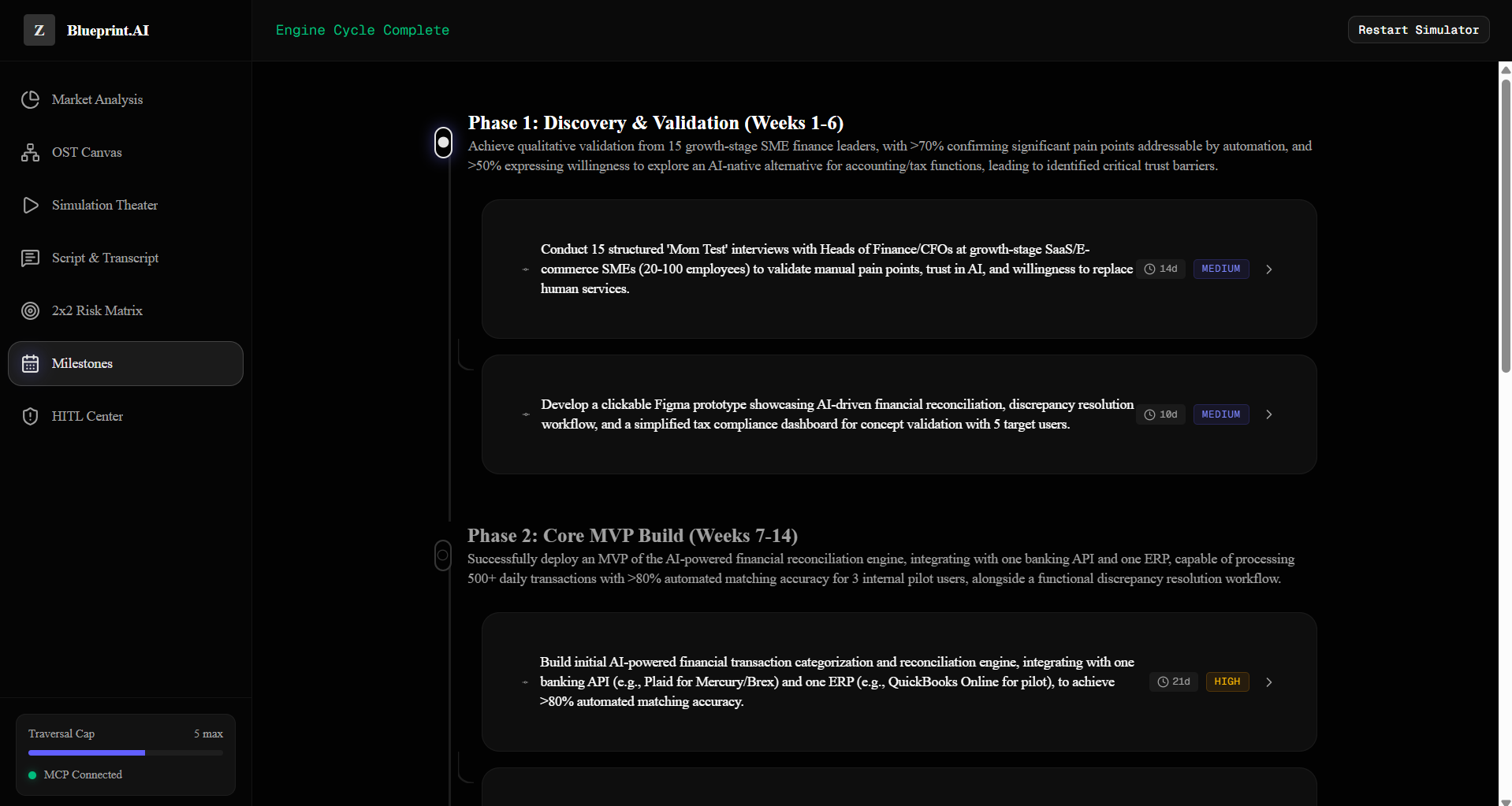
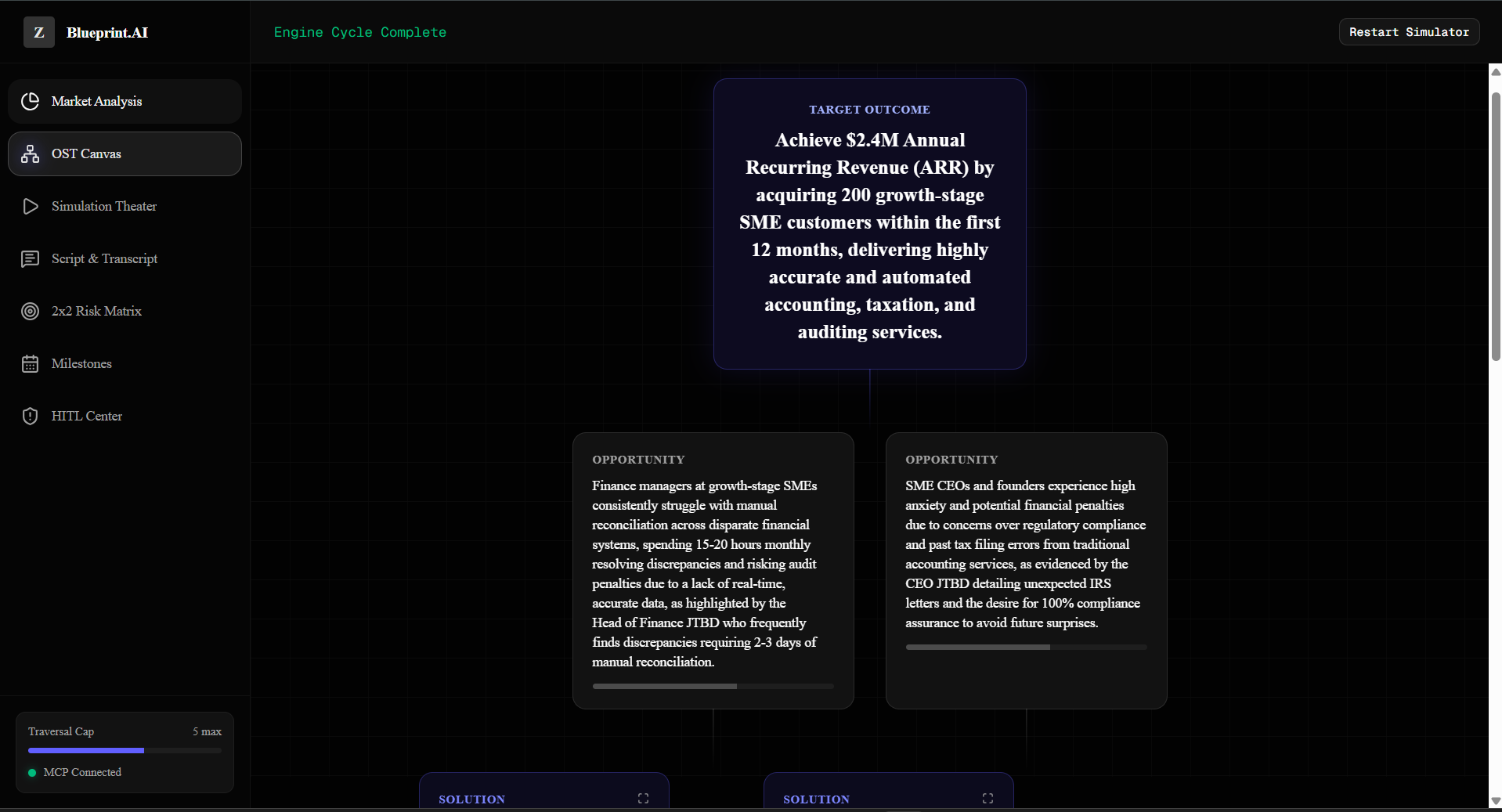
- 4-Phase Generation Pipeline: Dynamically generates a comprehensive execution plan spanning Market Analysis, Opportunity Solution Tree (OST), Mom Test Validation, and an Engineering Roadmap.
- Multi-Agent Simulation Engine: Automatically instantiates multiple distinct AI personas (e.g., CISO, Head of Finance, Early Adopter) to simulate parallel, multi-round adversarial stress tests of your startup idea.
- Mom Test Evaluator: An adversarial AI agent that grades real-world customer interview transcripts, penalizing hypothetical "future-tense" validation and compliment traps to ensure ground-truth signal.
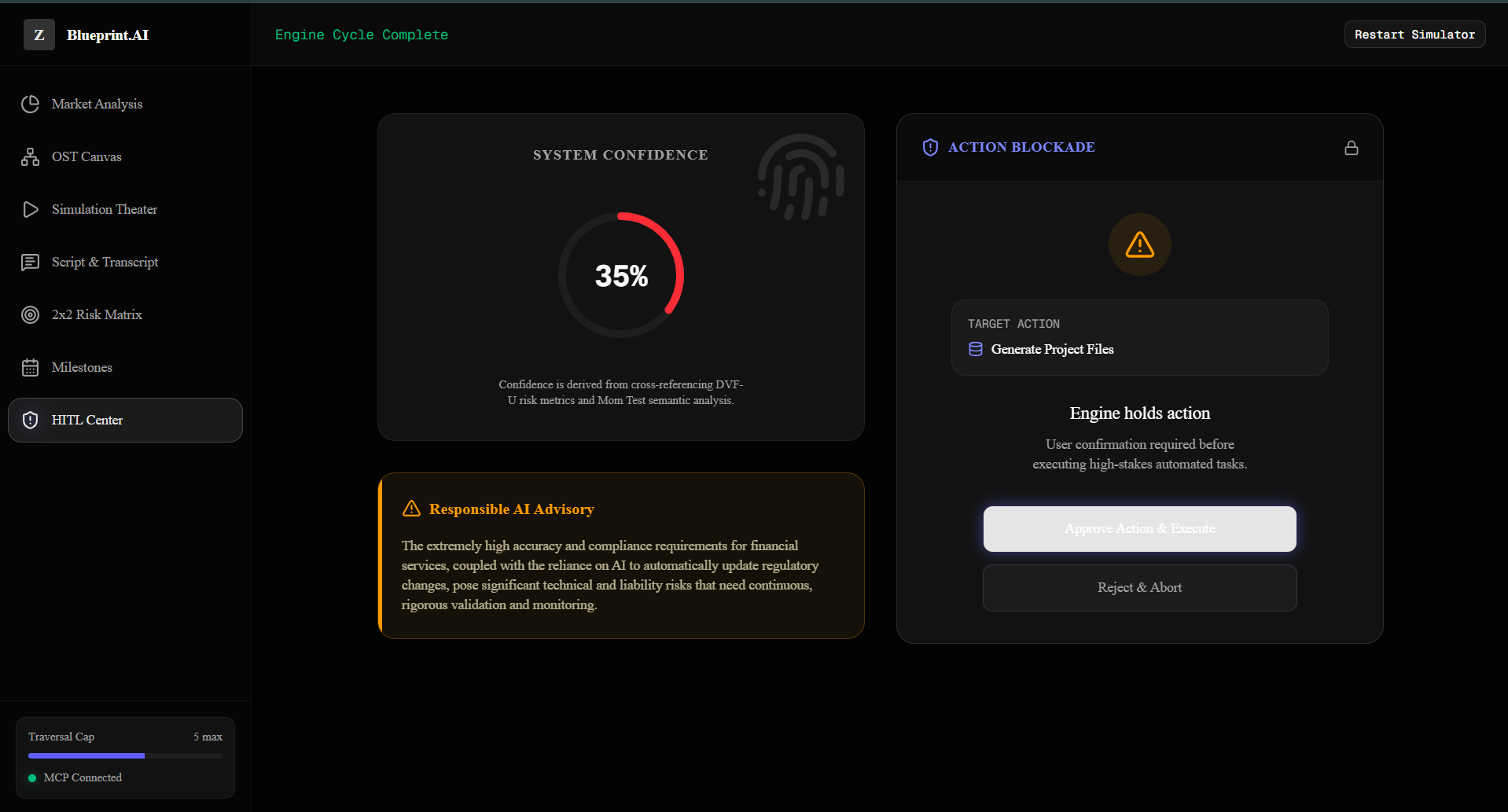
- Human-in-the-Loop (HITL) Governance: Strict stateful guardrails that block roadmap advancement until the founder provides empirical real-world validation data.
What it does
At its core, Blueprint.AI is a stateful, progressive product discovery and execution engine.
First, it takes your raw, messy, unstructured product concept and deconstructs it using Teresa Torres's Opportunity Solution Tree (OST) framework to tie features directly to target outcome metrics. Next, it acts as a ruthless validation coach. It helps you design unbiased discovery scripts based on The Mom Test principles, and features a transcript analyzer where you can paste raw customer interview logs. The system automatically strips out polite fluff, highlights hard empirical facts, and calculates an Interview Quality Score ($Q$) using the following formula:
$$Q=\frac{\text{Count of Empirical Facts}}{\text{Count of Empirical Facts}+\text{Count of Hypotheticals}+2\times\text{Count of Fluff}}$$
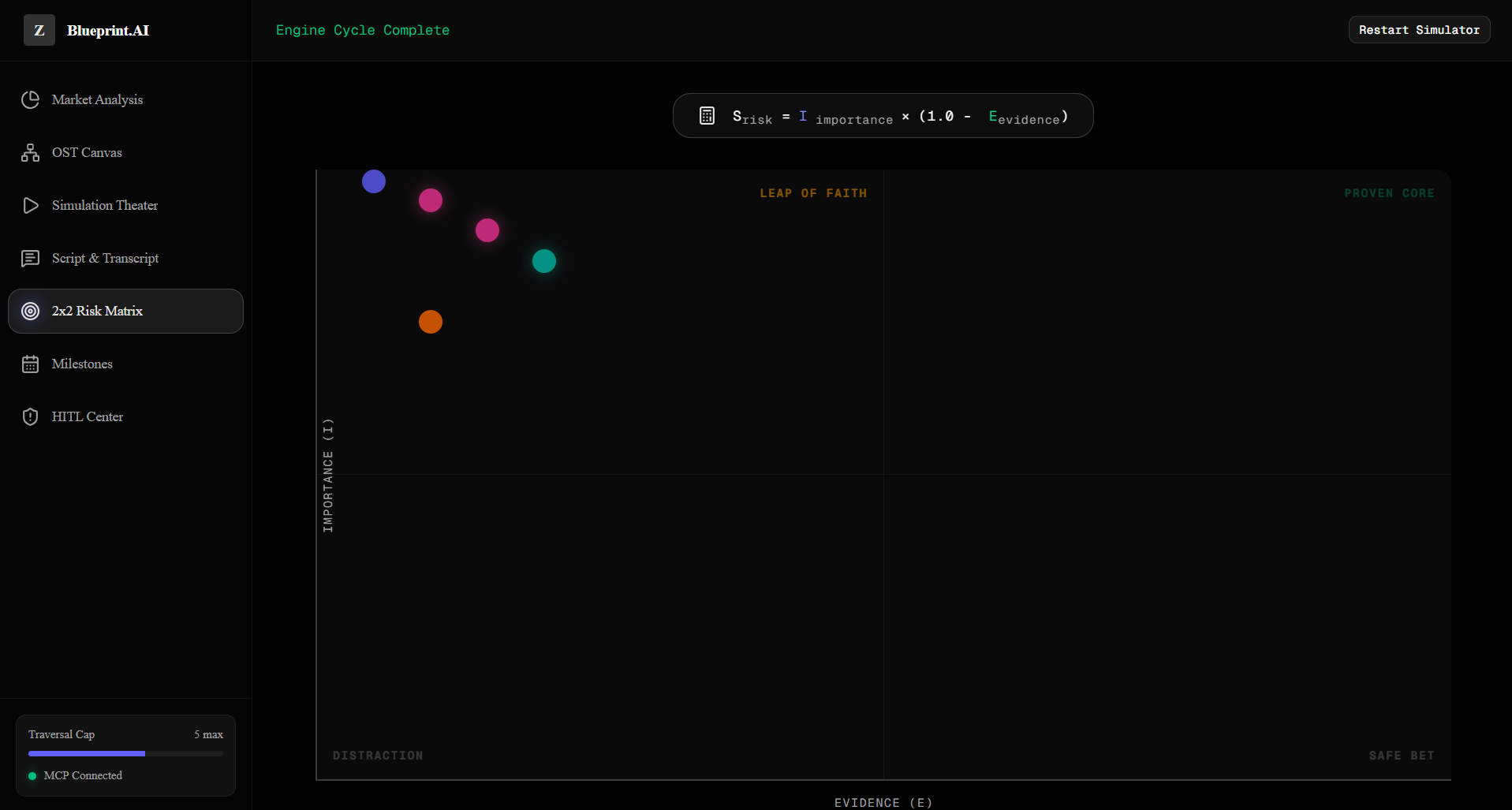
It then maps these assumptions across Desirability, Viability, Feasibility, and Usability (DVF-U) coordinates on an interactive 2x2 grid. High-importance, low-evidence assumptions are flagged in the top-left "Leap-of-Faith" zone using a calculated risk score :
$$S_{\text{risk}}=I_{\text{importance}}\times(1.0-E_{\text{evidence}})$$
Once you run recommended experiments to lower $S_{\text{risk}}$, it auto-generates a dependency-mapped, milestoned development timeline.
But the crown jewel we are incredibly excited about is our fully functional Scenario Simulation Engine. Imagine a flight simulator, but for your product. Instead of sending you straight out to pitch to real people, the engine spawns a synthetic society of AI agents—each with a distinct persona, memory, and agenda—and drops your startup idea right into their virtual world.[2] They react, talk to each other, raise pricing objections, spread viral word-of-mouth, or reject your pitch entirely. You get to watch the market dynamics unfold in real-time, extracting deep qualitative insights that no static business model canvas could ever give you.
Each simulated agent runs on a cognitive Memory $\rightarrow$ Reflection $\rightarrow$ Planning Loop inspired by the Stanford Generative Agents architecture :
- 🧠 Persona Seed: Instantiates demographics, psychographics, goals, budget limits, and technical stack preferences.
- 📝 Memory Stream: A long-term PostgreSQL table recording every observation, conversation, and action.[2]
- 🔍 Reflection: Periodically (every 3 rounds) synthesizes raw experiences into higher-level abstract insights.
- 📋 Planning: Maps out tactical actions (like
decide_to_buy,request_demo,raise_objection,spread_word, orcompare_competitor).[2] - 💬 Action: Executes the plan, which is logged back into the memories of all observing agents.
We ship with five pre-built templates ready to run with one click:
| Scenario | Agents | What It Tests | | "Launch Day" | 8 potential customers + 2 competitors + 1 tech journalist | PMF signals, word-of-mouth, competitive responses | | "Pricing Gauntlet" | 6 buyers at different budgets + 1 CFO + 1 procurement manager | Price sensitivity, deal-breaker thresholds | | "The Pitch" | 3 VC partners + 1 angel investor + 1 skeptical LP | Fundability, objection patterns, VC questions | | "Enterprise Sales" | CTO + CISO + procurement + end-user champion + blocker | B2B buying committee dynamics, security blockers | | "Community Reaction" | 10 Hacker News/Reddit personas with varying sentiment | Viral potential, internet criticism, community fit |
How we built it
System Architecture
The application relies on a modern, serverless AI stack utilizing Vercel's Node.js runtime to process complex, long-running agent workflows without timeouts.
Link
Execution Flow
We built Blueprint.AI using a modern, ultra-performant full-stack React and TypeScript architecture.
- Step 1: Users submit concepts or interventions through a responsive Next.js 15 Tailwind client which initializes the session state.
- Step 2: The client-driven state iterator calls our edge API routes to trigger single-timestep runs, staying well within Vercel's 30s timeout cap.
- Step 3: The Vercel AI SDK streams validated JSON token-by-token using
streamObjectpaired with theanthropic-betafine-grained tool streaming header. - Step 4: LangGraph orchestrates agent graph traversals server-side, enforcing a strict 5-step cap to prevent infinite token-draining loops.
- Step 5: Database queries execute through a secure Drizzle transaction wrapper that sets the session ID (
SET LOCAL app.user_id) to isolate tenant data at the SQL engine level. - Step 6: Simulated customer personas fetch contextually relevant memories by running cosine-similarity vector queries ($S_{\text{retrieval}}=\alpha\times S_{\text{rec}}+\beta\times S_{\text{imp}}+\gamma\times S_{\text{rel}}$) natively in PostgreSQL via
pgvector. - Step 7: An AWS RDS Proxy pools and consolidates database connections, protecting the Amazon Aurora Serverless v2 database from edge-compute concurrency spikes.
- Step 8: Human approval is strictly required through a Human-in-the-Loop gateway before executing high-stakes migrations or customer communications.
Tech Stack
- Frontend: Next.js 16 (App Router), React, Tailwind CSS, Framer Motion, Lucide Icons.
- AI Stack: Google Gemini (
gemini-2.5-flash), Vercel AI SDK (ai), LangChain Core, LangGraph. - Database: Neon Serverless Postgres, Drizzle ORM.
- Authentication: NextAuth (Auth.js) with Passkey support.
- Deployment: Vercel.
Challenges we ran into
Spawning 8 to 12 autonomous customer agents and running a 10-round interactive simulation sequentially would take several minutes, which instantly exceeds Vercel’s 30-second serverless edge request timeout.[10]
We solved this by architecting a client-driven API Tick Pattern.[13] Instead of running the entire simulation in a single HTTP request, the frontend client maintains the timestep state machine and triggers individual round updates to POST /api/simulation/tick. On the backend, we run the cognitive reasoning loops of all active agent personas concurrently using parallel Promise.all blocks. This ensures that every round tick resolves in under 3 seconds.
Another nightmare was preventing "agent spirals"—situations where a model gets stuck in a recursive tool-calling loop, confidently burning through our API credits.[13] We fixed this by setting up a strict Governor layer using LangGraph's stopWhen: stepCountIs(5) control loop constraints, coupled with structured dead-letter-lane fallbacks.[13, 14]
Accomplishments that we're proud of
We successfully designed and built a highly secure, type-safe multi-tenant RLS database structure on Amazon Aurora Serverless v2 and instrumented the entire flow with Langfuse and Sentry OpenTelemetry spans [15, 16] in less than a week!
The client experience of our Simulation Theater UI is incredibly satisfying. Watching your vague idea progressively stream into a visual Opportunity Tree, seeing connection vectors draw themselves on the canvas, and then seeing circular agent avatars light up with glowing red, yellow, or green "emotional status auras" during active market simulation is a massive UI/UX win.[9] It makes startup planning feel less like administrative homework and more like an immersive multiplayer game.
What we learned
We learned that TypeScript is an absolute lifesaver when building agentic software. When you have LLM agents interacting with schemas, generating data models, and performing database operations, end-to-end type safety is your only guardrail against total database corruption.
We also learned a lot about structured outputs. Treating Zod schemas as an uncompromised validation contract doesn't just ensure we get clean JSON [13]; the schema keys actually serve as a powerful second instruction channel that prevents hallucination and forces the model to reason more logically.[17, 18]
What's next for Blueprint.AI
We want to add real-time, bidirectional voice-to-voice interfaces to our Mom Test coaching panel using Next.js WebSockets and Google's Gemini Live API so founders can verbally practice handling objections.
We are also planning to build a deep integration with GitHub and Jira.[19] Once your 30-day milestone tasks are validated, our agents can automatically generate the initial database migration scripts and scaffold the Next.js routes, committing them straight to your repository as a starter pull request.
Built With
- ai-agents
- langgraph
- llm
- postgresql
- react
- tailwind
- tavile



Log in or sign up for Devpost to join the conversation.