Inspiration
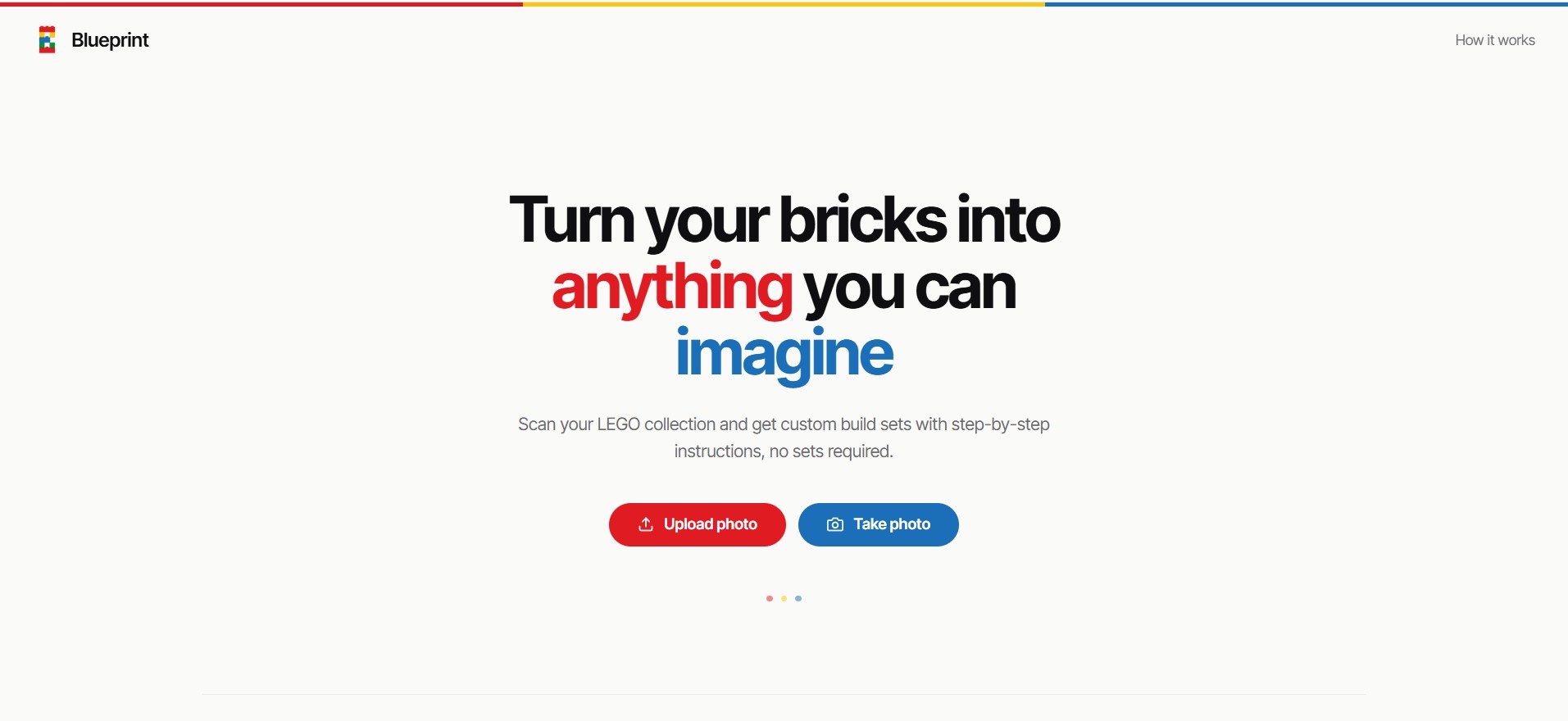
Growing up we always had bins full of spare LEGO pieces lying around that we never knew what to do with. We wanted a website where you could get a bunch of ideas on what to build with just the pieces you had spare. So for this hackathon we built Blueprint.
What it does
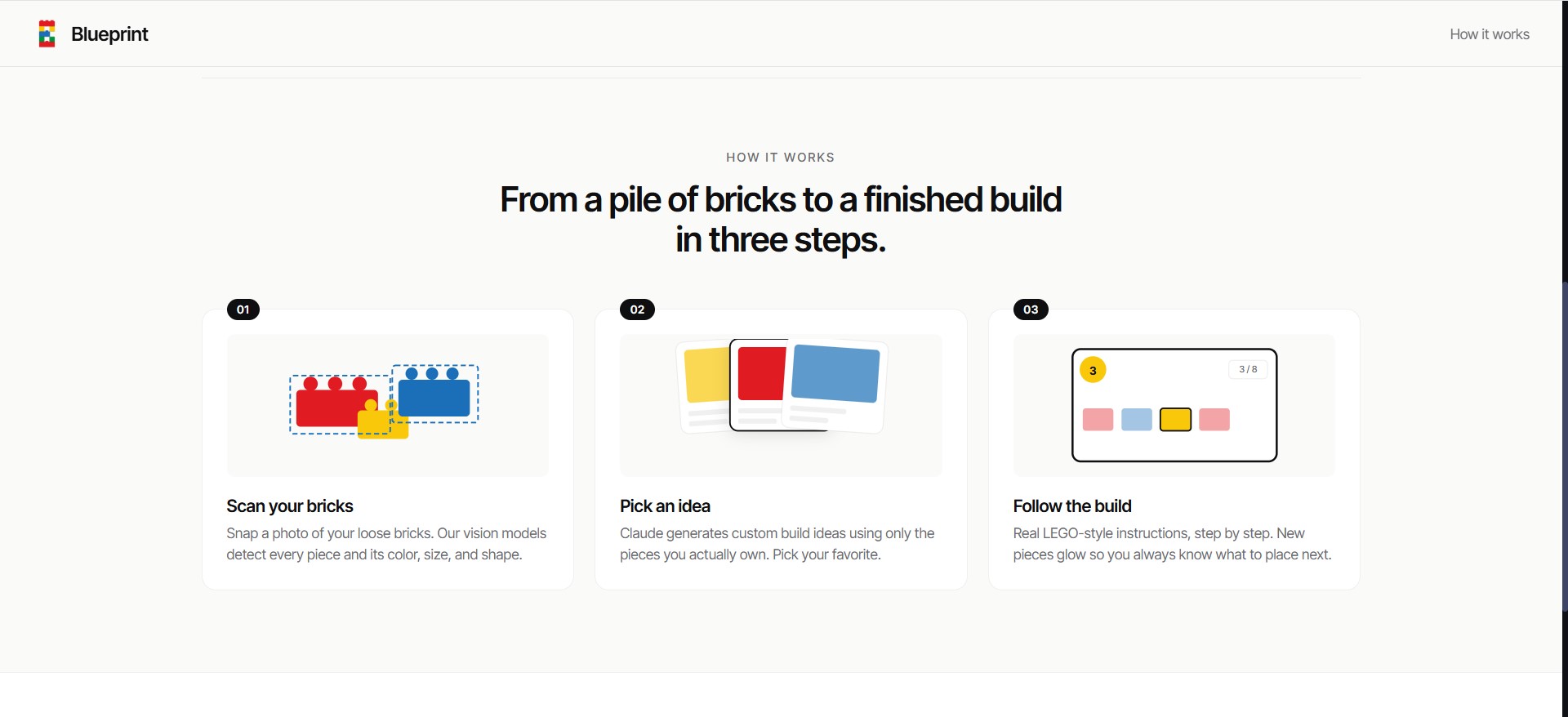
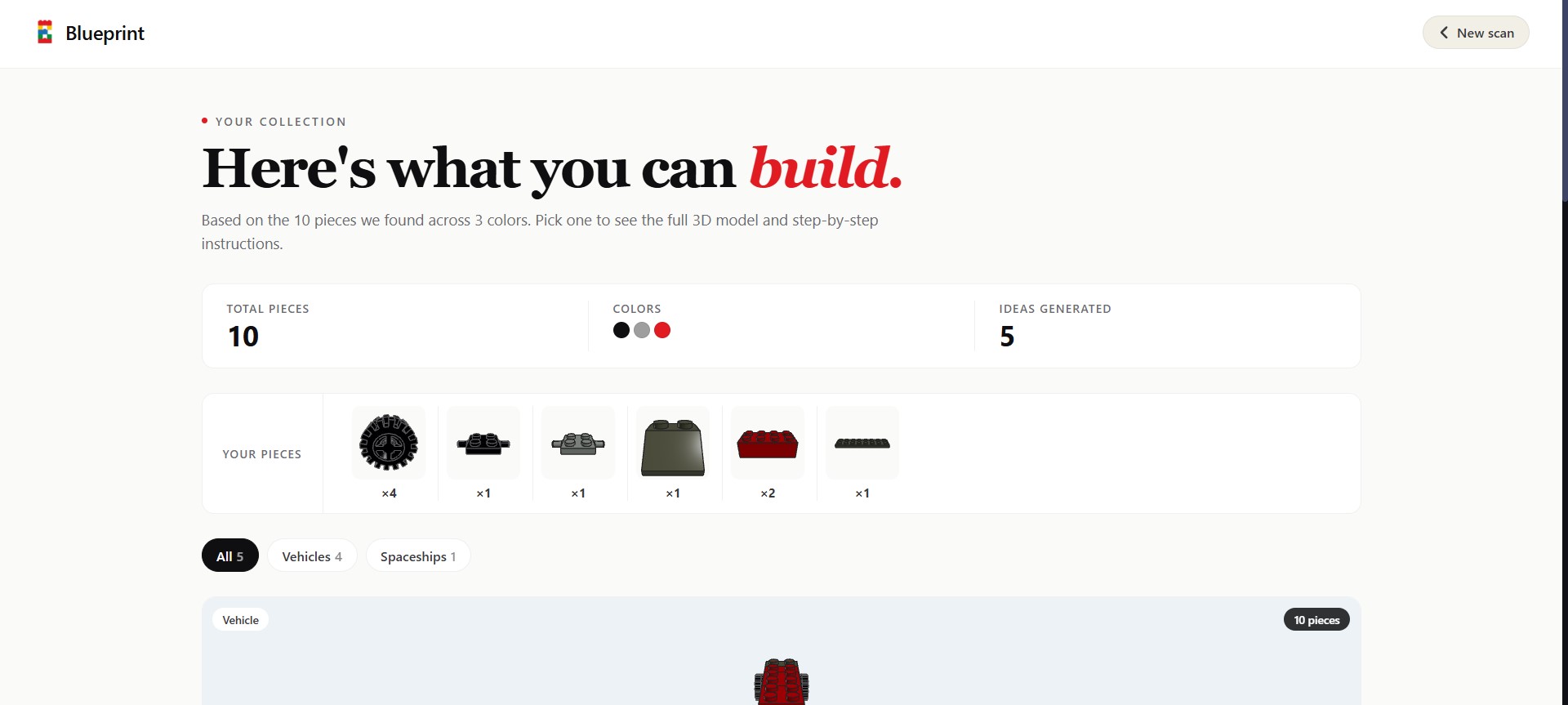
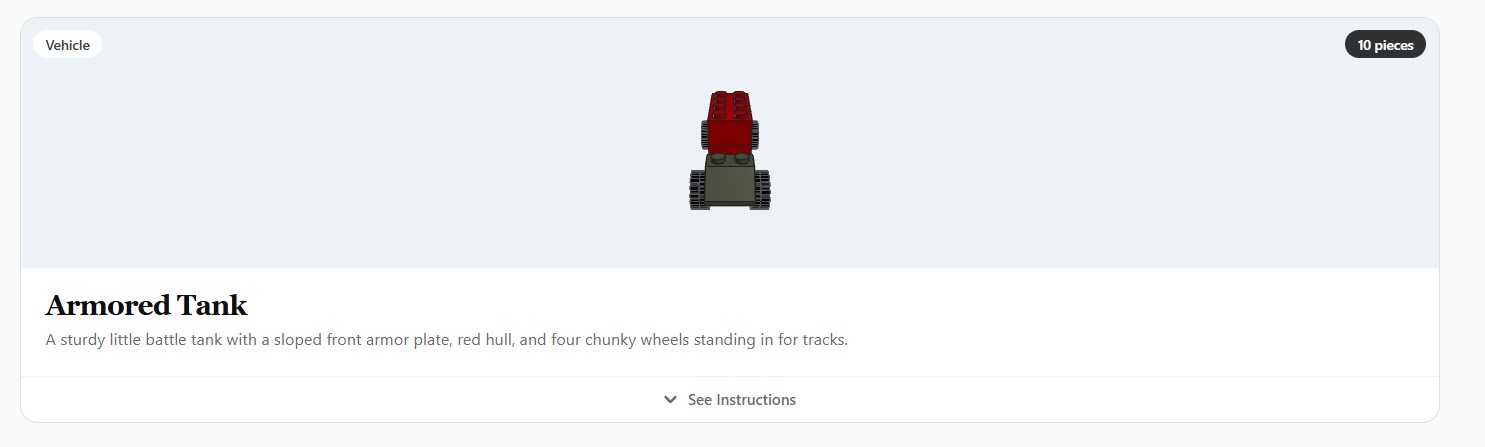
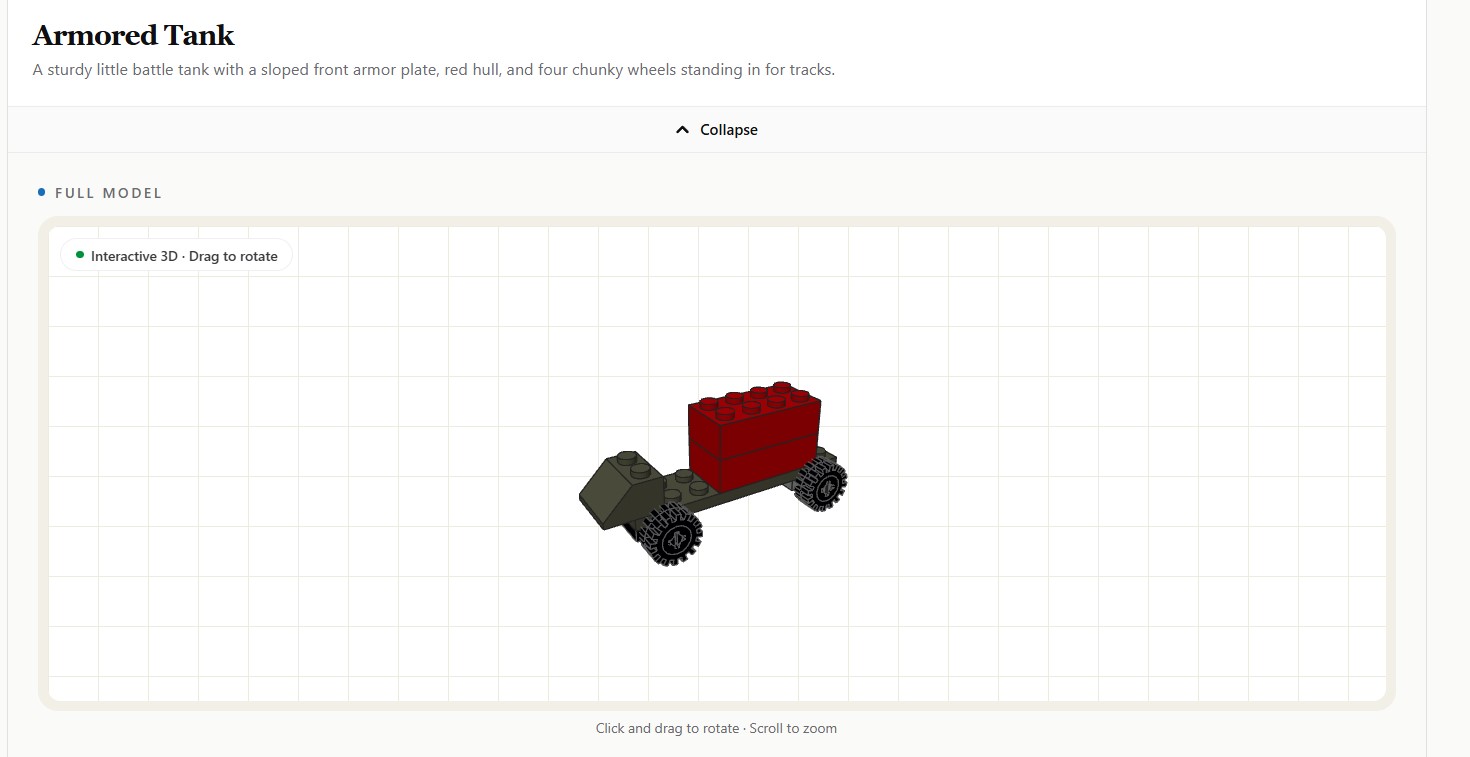
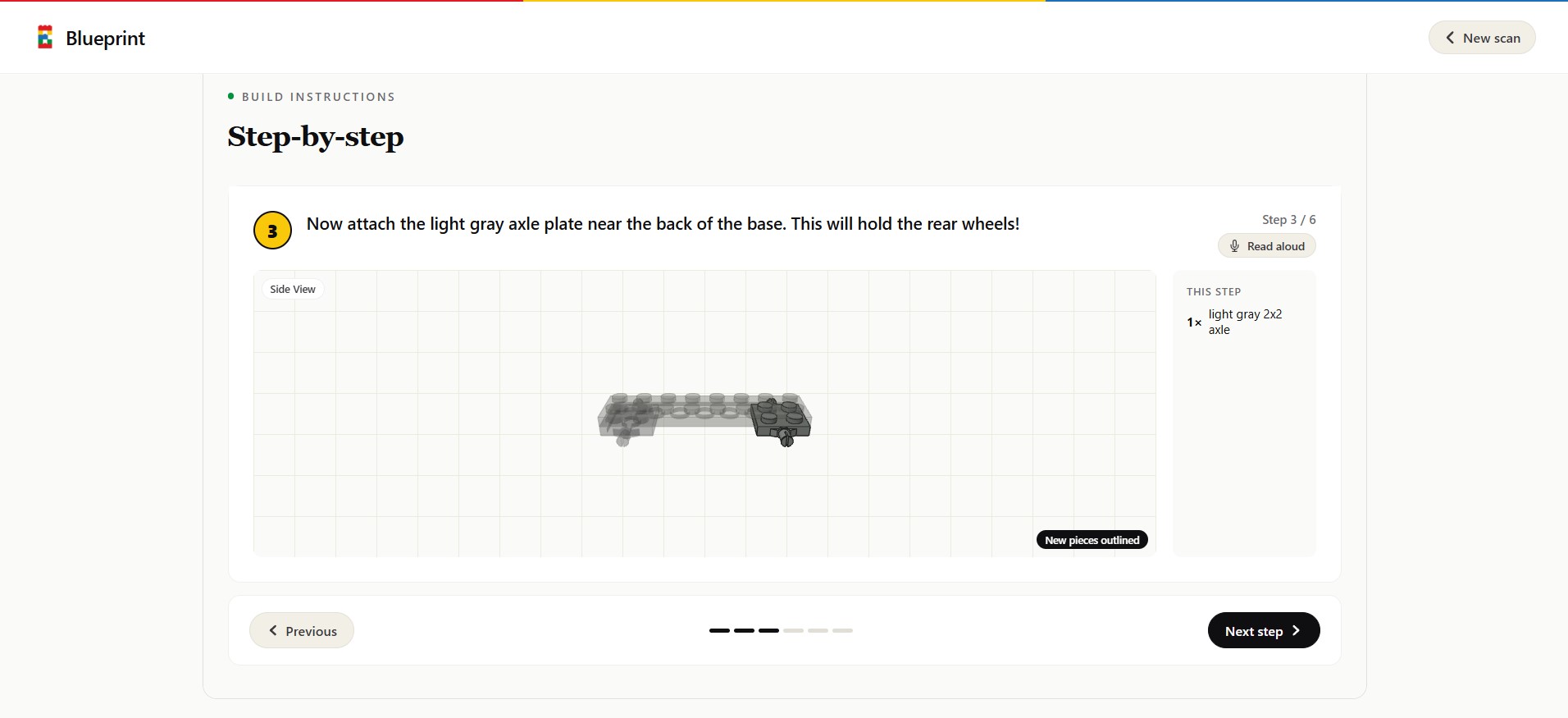
Blueprint analysis an image you took, extracts all the LEGO pieces from it and generates a ton of ideas of things you can build from it. For each idea, Blueprint creates a full 3d interactive model of the finished product, a list of all the pieces used, and coolest of all custom LEGO instructions on how to make it similar to actual LEGO booklets.
How we built it
For the frontend we used React as a framework, then Three.js and LDraw to draw the 3d models. For the backend we used Node.js for all the endpoints, and Google Cloud Vision API, Gemini Vision, and Claude API to extract the pieces and generate ideas/instructions.
Challenges we ran into
We tested a variety of LLMs to see which one could generate the best ideas/instructions and landed on Claude, specifically Anthropic's Sonnet 4.6 model, but Claude still had issues. When developing this product we figured out that LLMs don't seem to be very good yet at understanding spatial coordinates, and the fact that it had to do so in a way LDraw understood made it even worse. The main issues were pieces being clipped together or being placed in nonsensical orientations such that it did not produce a solid structure or made sense.
Accomplishments that we're proud of
We are proud of how much the quality of the image recognition and idea/instruction generation has progressed. Although it's not perfect it works better than I thought we'd get given the 36 hour constraint. Specifically the vision pipeline is what we are most proud of. We originally tried using just Gemini Vision to get the entire piece list, however Gemini Vision seemed to have trouble counting all the pieces, it would consistently overcount / undercount the number of pieces so we introduced Google Cloud Vision API to try and prevent this. We use Cloud Vision and run label detection + object localization to draw bounding boxes around each piece, then for each piece we crop the image to only include the piece and then send a separate call to Gemini Vision to classify it. Combining the results at the end for the complete piece list.
What we learned
We learned that computer vision, and trying to get LLMs to produce spatially correct/consistent ideas is hard. We managed to achieve roughly 90% accuracy for classifying each piece, and the model placed pieces in a way that made sense roughly 80% of the time, but it's still not perfect. We learned that creating a strict pipeline which leaves as little ambiguity possible tends to create the most consistent and correct outputs from the machine learning tools we used to create this.
What's next for Blueprint
What's next for Blueprint is giving users the option to list specific categories. Currently Claude is generating ideas and it decides the category of each idea. Giving users direct influence on what categories of sets get generated would allow users to get more personalized and tailored sets leading to an overall better experience.











Log in or sign up for Devpost to join the conversation.