
Inspiration
Text Mining is something new to me, and we found the challenge of word embedding fascinating and intriguing at the same time, more so after realizing how essential it has become for today's natural language processing models!
What it does
Basically, it converts text documents into numerical vector representation, thereby converting big sparse matrices into condensed low dimensional representation.
How we built it
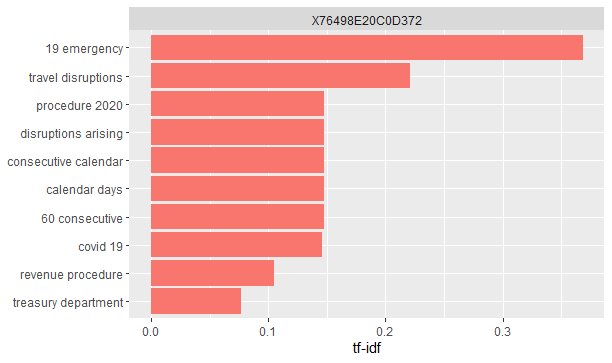
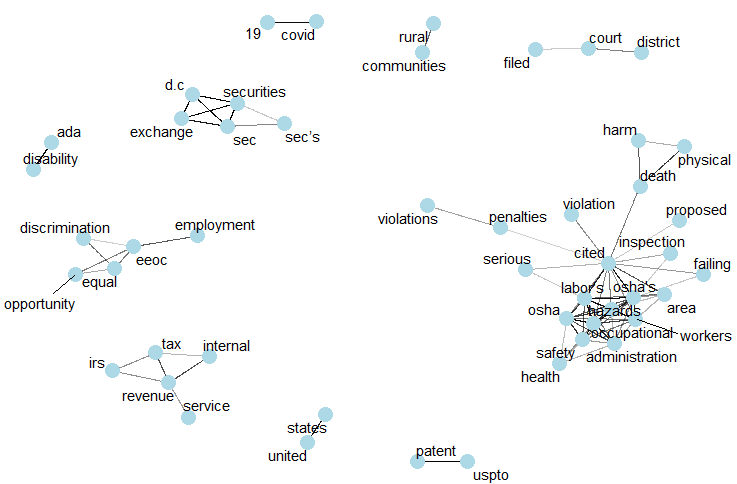
We used R language for writing our codes, and utilized important libraries primarily used for text mining. First we tokenized the provided datasets text column into separate word columns. Then we applied term frequency - inverse document frequency (it_idf) to check for most essential words, bigrams, and trigrams. This inherently removed most used English filler words such as 'and', 'the', 'it', etc. We verified our findings by plotting correlation diagrams for visualizing words that occur together > 70% of the times. Then we joined these derived datasets with the original dataset using id as the key, and applied random forest classifier.
Challenges we ran into
The biggest challenge was handling the size of data for training purposes. As the vector size was > 100 GB, we tried to condense it and re-run the ML model.
Accomplishments that we're proud of
We are very proud that we took up this challenge even though it is not related to our core discipline, and we learnt a lot of new concepts in a single day, and simultaneously applied it and arrived at decent results.
What we learned
We learnt about basics of word embedding, how word2vec works, the intricacies behind it-idf algorithm, slider window sampling, and n grams and the importance of context in prediction of new words/vectors.
What's next for Bloomberg Industry Group 2022 Datathon Challenge
Although the project submission deadline is nearing its end, we will try to finish the challenge later on and share our codes of the completed work soon.

Log in or sign up for Devpost to join the conversation.