-

PNG
-

-

-
-

-
-

-
-









Inspiration
We were drawn to this project due to our desire to learn more about embeddings and their applications for large data sets.
What it does/How We Built it (Part 1)
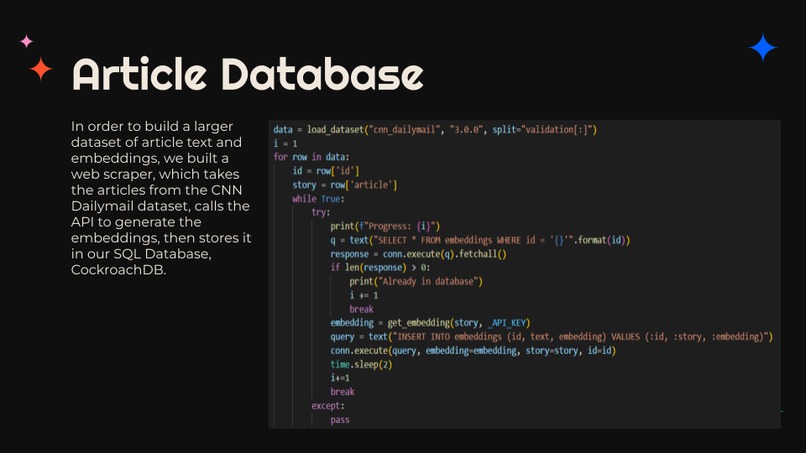
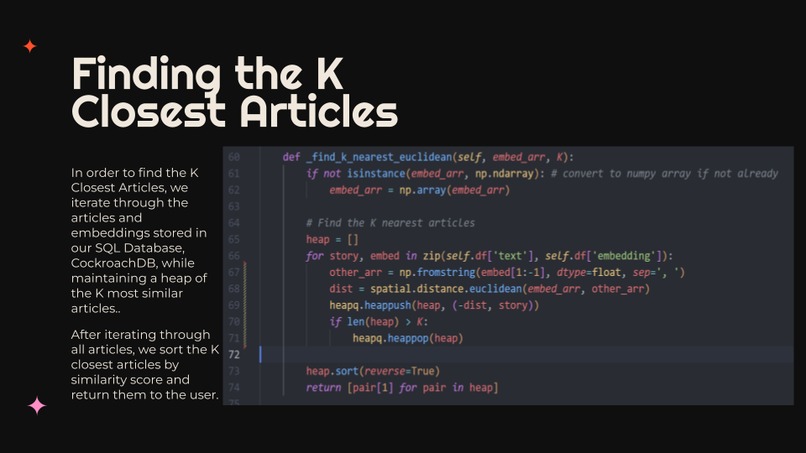
Our program uses the Bloomberg API to pull data from the CNN_dailymail dataset in order to have a continuous flow of data. We then call the Bloomberg API to embed the text articles and store that data in our CockroachDB which is constantly updated in order to for us to process the maximum amount of data points. We then take the 25,000 data points and use five different metrics to compare our embeddings (cosine, euclidean, manhattan, correlation, canberra ) to the given embeddings. We maintained a heap with the top K (set to 5) most similar articles for each challenge article and then sorted the output from most to least matched. We then displayed the text of the embeddings which displayed the highest accuracy and drew comparisons and common themes between the most similar texts to each challenge article using both manual inspection and the OpenAI GPT3 language model.
What it does/How We Built it (Part 2)
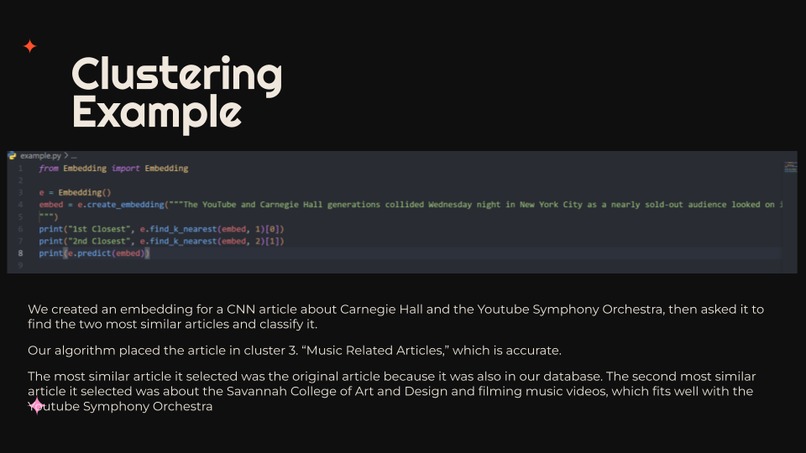
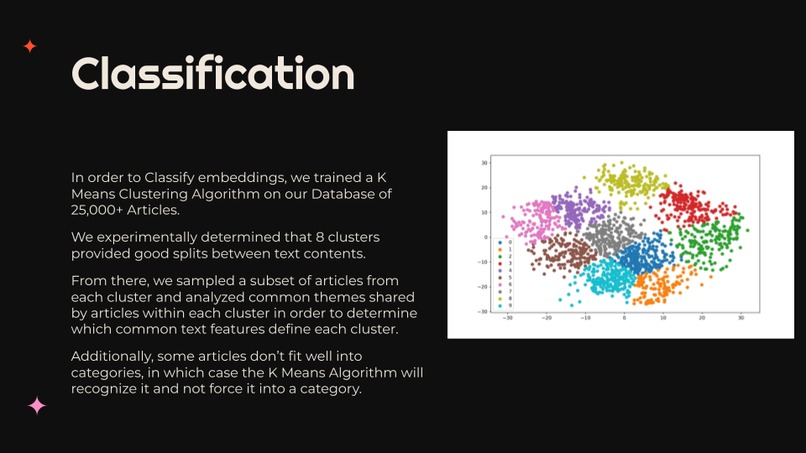
We queried all 25000+ news articles and text embeddings from our CockroachDB, then fit a K Means Clustering Algorithm with 8 clusters to find the most similar articles. We then sampled embeddings from each cluster, looked them up in our SQL database, and used our website, mailai.org, to determine the common characteristics of each group. We also created an Embeddings class in Python which allows users to handle embeddings. It has methods to generate embeddings from a piece of text, query our SQL database, classify an embedding using our K Means Clustering Algorithm, and look up the K most similar articles to a given embedding using heaps.
Challenges we ran into
Our main challenge was finding the right metrics to gauge the similarities between articles and determine what the mystery articles are about.
Accomplishments that we're proud of
We are proud of the strategy we implemented to sort through all the articles and produce the top K articles. We implemented a search over the SQL Database using heaps for optimal time complexity.
What we learned
We learned how to populate the CockroachDB database with live updates and we concluded the challenge with over 25,000 data points. We also learned how to implement a heap in order to efficiently find the K most similar articles to a given embedding at all times which worked perfectly in our scenario in which we had to filter through tens of thousands of data points.
What's next for Bloomberg INDG Challenge
In the future, the Bloomberg INDG Challenge could switch up the media and change from embedding articles to embedding pictures and then have to use metrics to detect and organize visual images. We also want to try to use the Cohere.ai API to generate classifications for text articles, then train a neural network to learn a mapping from the embedding to classification. We wanted to implement this,, but did not have enough time.



Log in or sign up for Devpost to join the conversation.