Inspiration
Humanitarian funding doesn’t fail because the world lacks money. It fails because capital is misallocated.
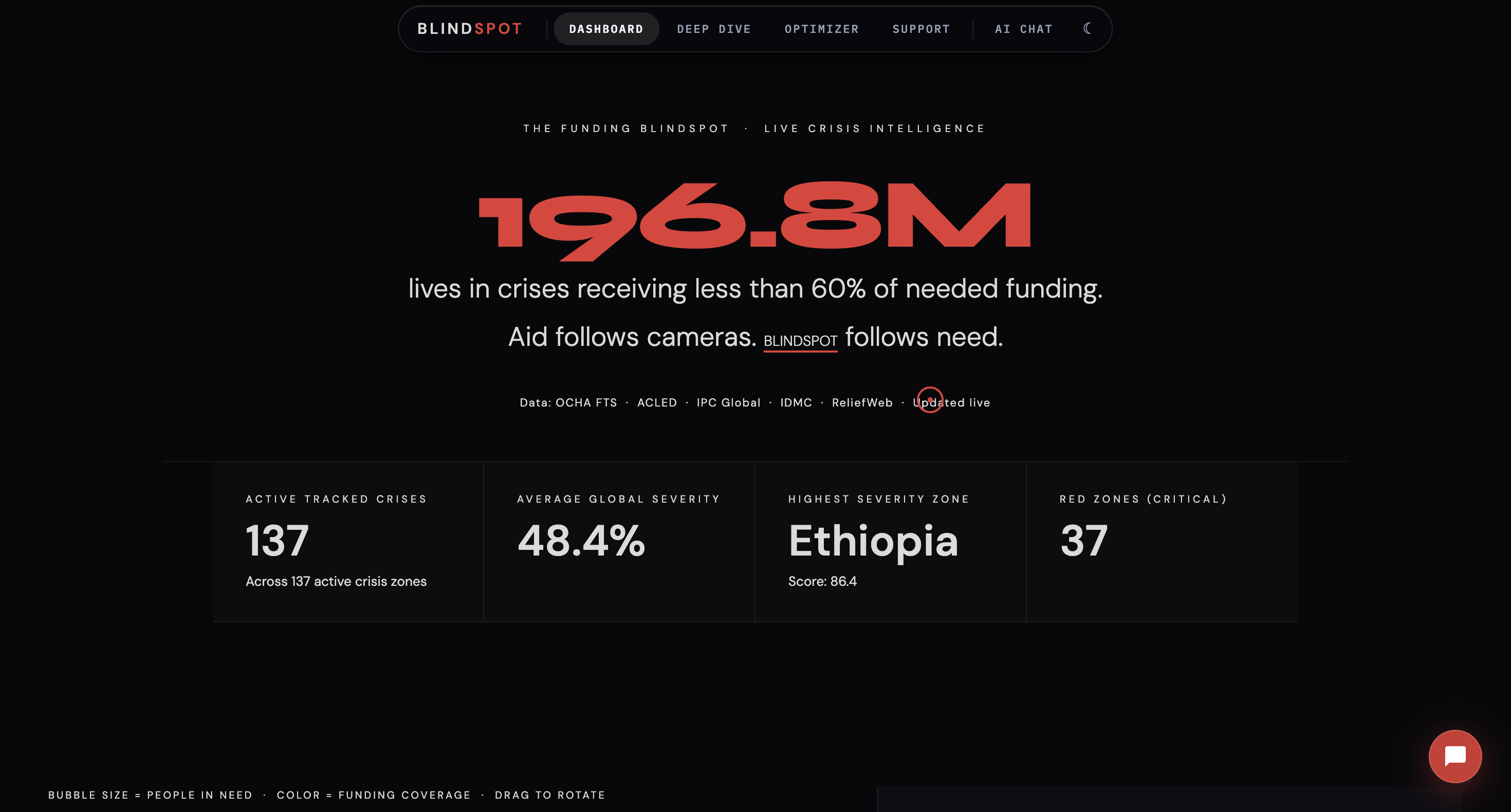
When a crisis dominates headlines, funding surges. When it doesn’t, it becomes a blind spot — regardless of severity. Some of the most severe crises on earth remain critically underfunded, not because they matter less, but because they are less visible.
We realized this isn’t just a humanitarian problem. It’s a capital allocation problem.
Capital isn’t distributed based on emotion — it’s allocated based on data, constraints, and expected outcomes.
Humanitarian funding, despite operating at multi-billion-dollar scale, rarely benefits from that same rigor.
"Funding follows headlines. Lives don't." BlindSpot exists to fix that.
What it does
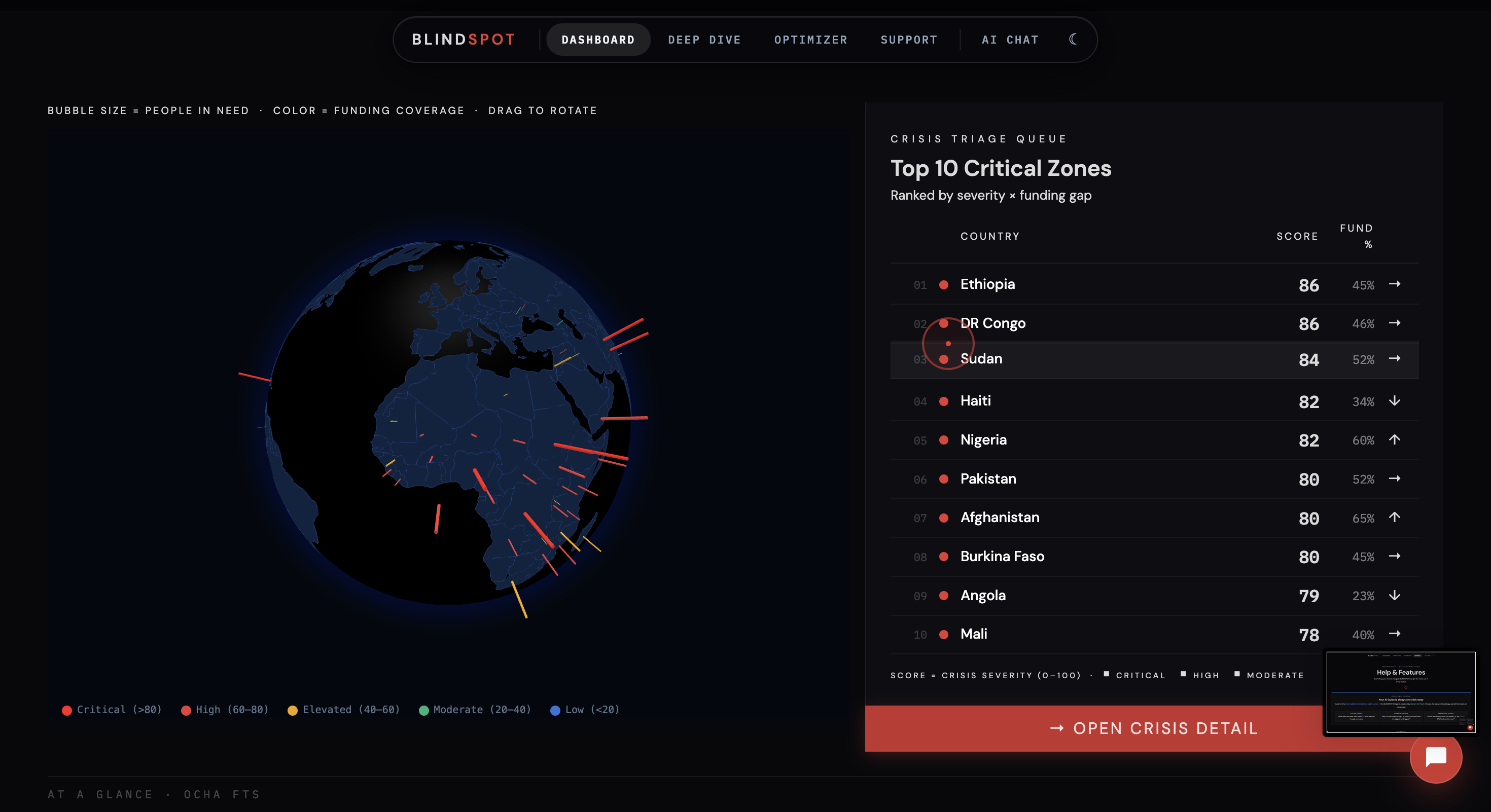
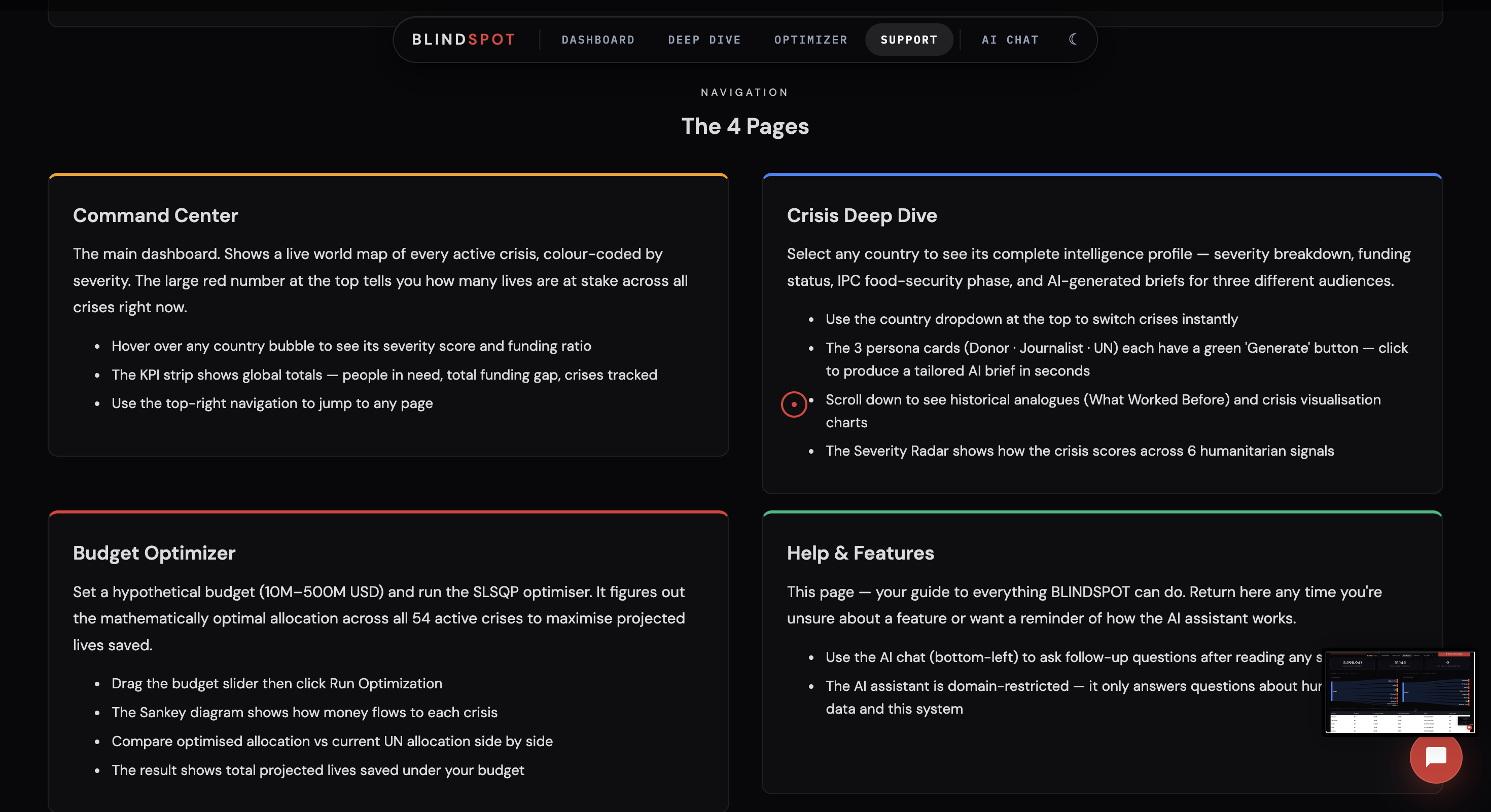
BlindSpot is a full-stack AI capital allocation engine for humanitarian crises. It ingests five authoritative UN datasets, scores every tracked country on a defensible Crisis Severity Score (0–100), and tells decision-makers exactly where to deploy capital — before the crisis peaks.
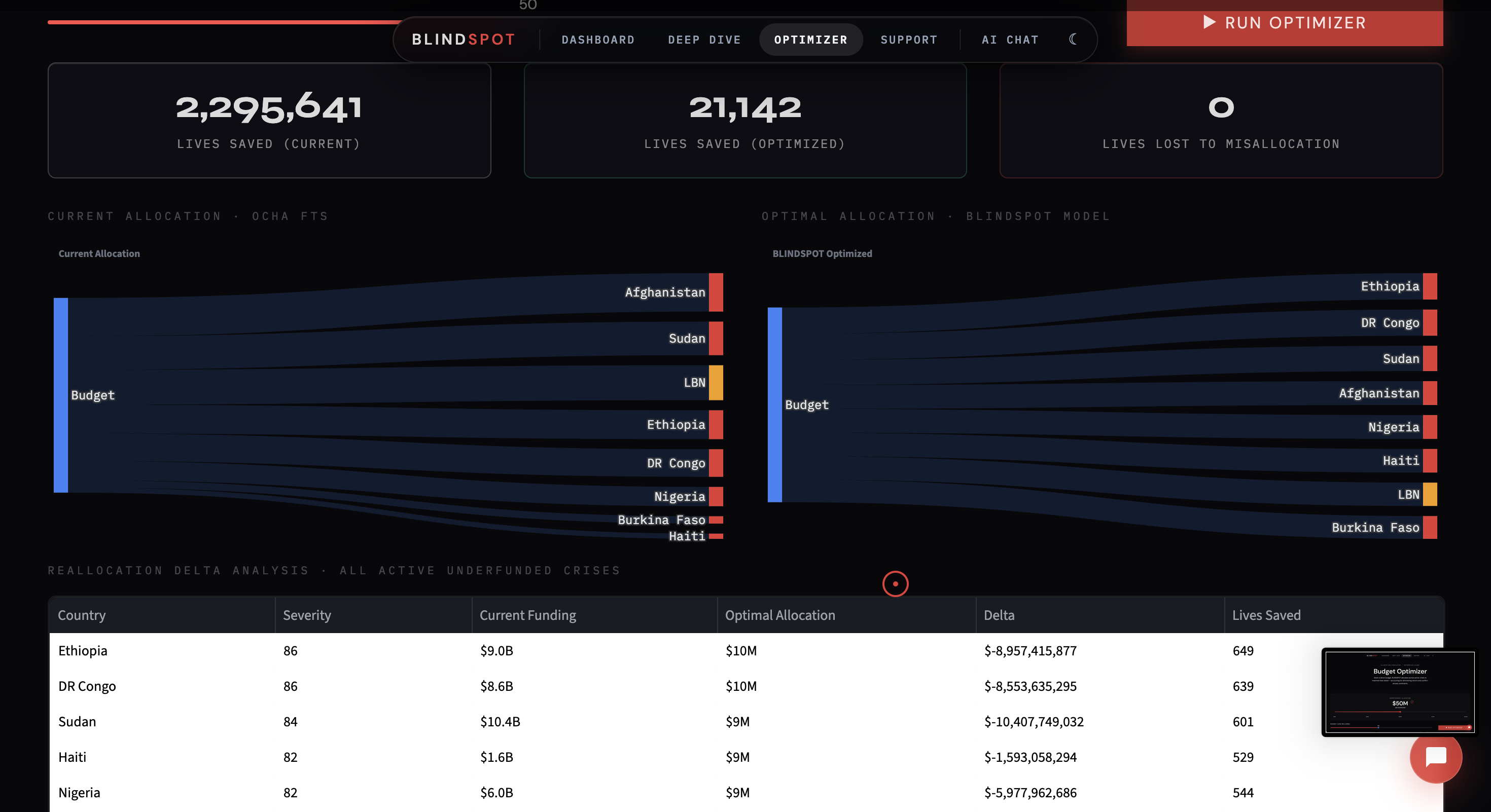
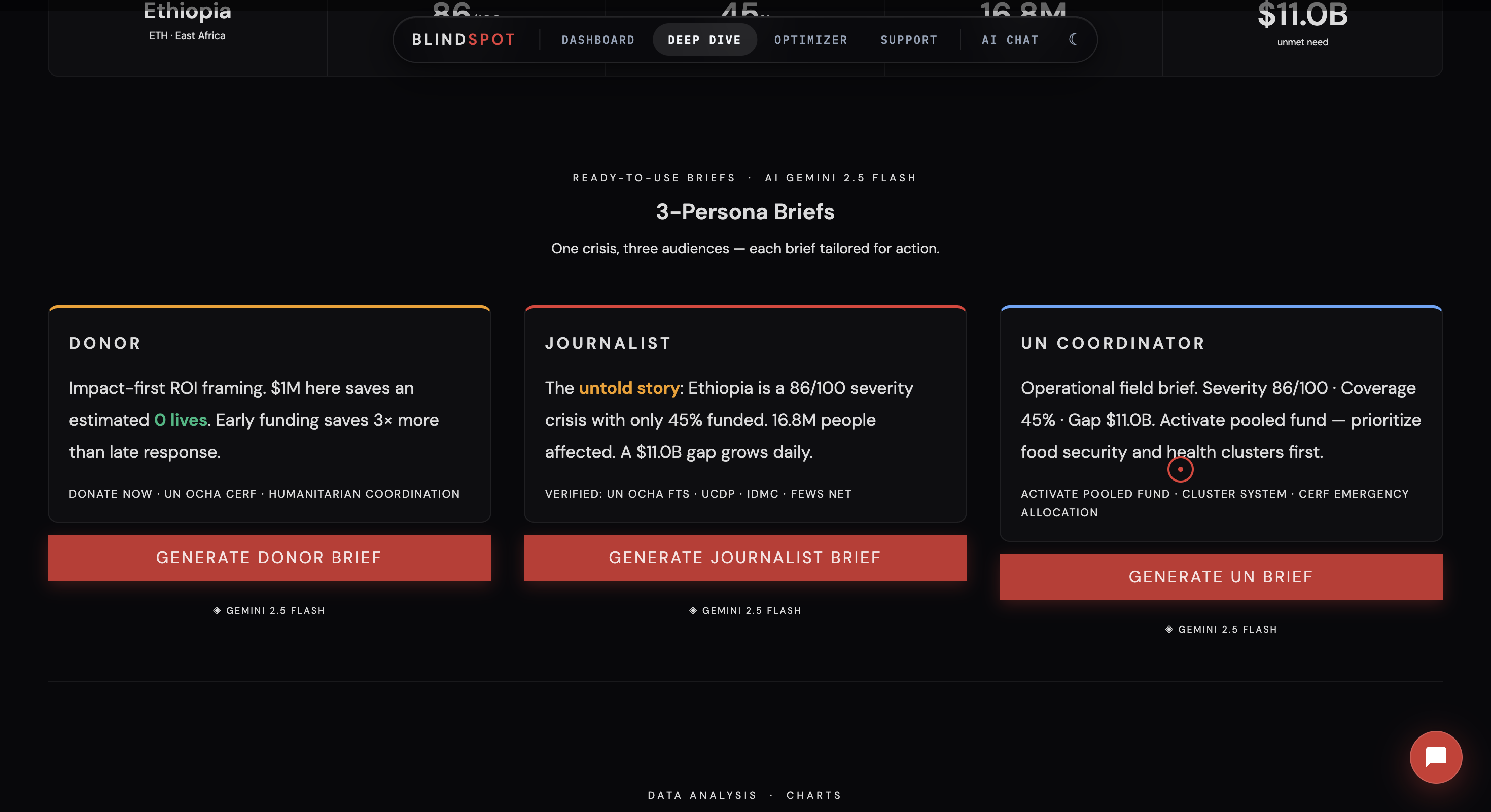
The dashboard opens with a single number: the estimated lives lost annually to humanitarian funding misallocation compared to data-driven optimal allocation. That number is calculated live from real UN data every time the dashboard loads.
Four layers of intelligence:
- Crisis Severity Scoring — PCA-based model across 5 crisis dimensions (conflict, displacement, food insecurity, funding gap, IDP population) produces a single normalized score per country
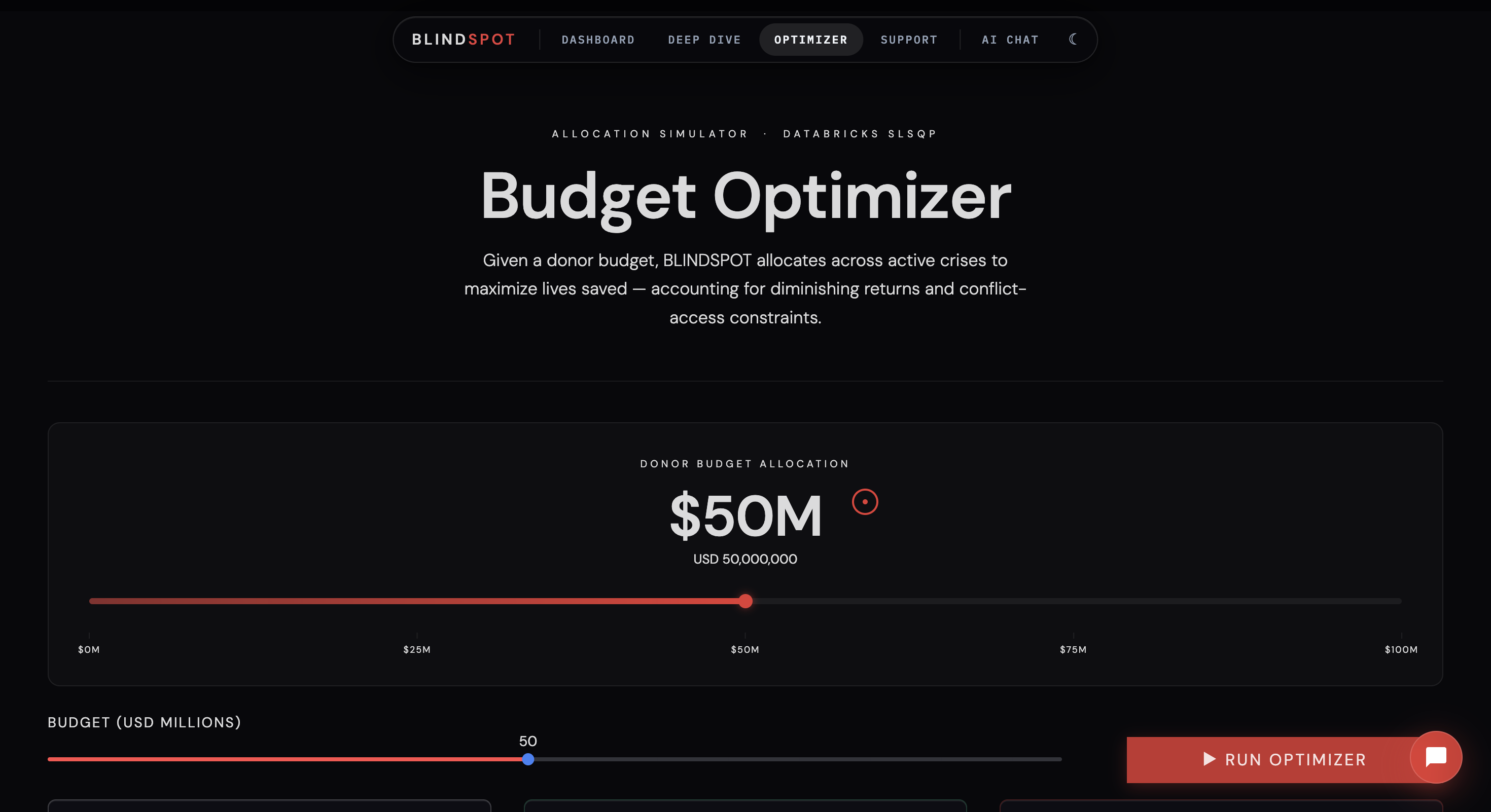
- AI Capital Allocation Engine — Enter a budget, get a ranked manifest of exactly which countries receive funds and how much, proportional to severity. Powered by SciPy SLSQP constrained optimization with diminishing returns modeling
- Intelligence Assistant using Gemini API — Domain-restricted AI grounded in live Databricks data, authorized only for humanitarian and capital allocation queries
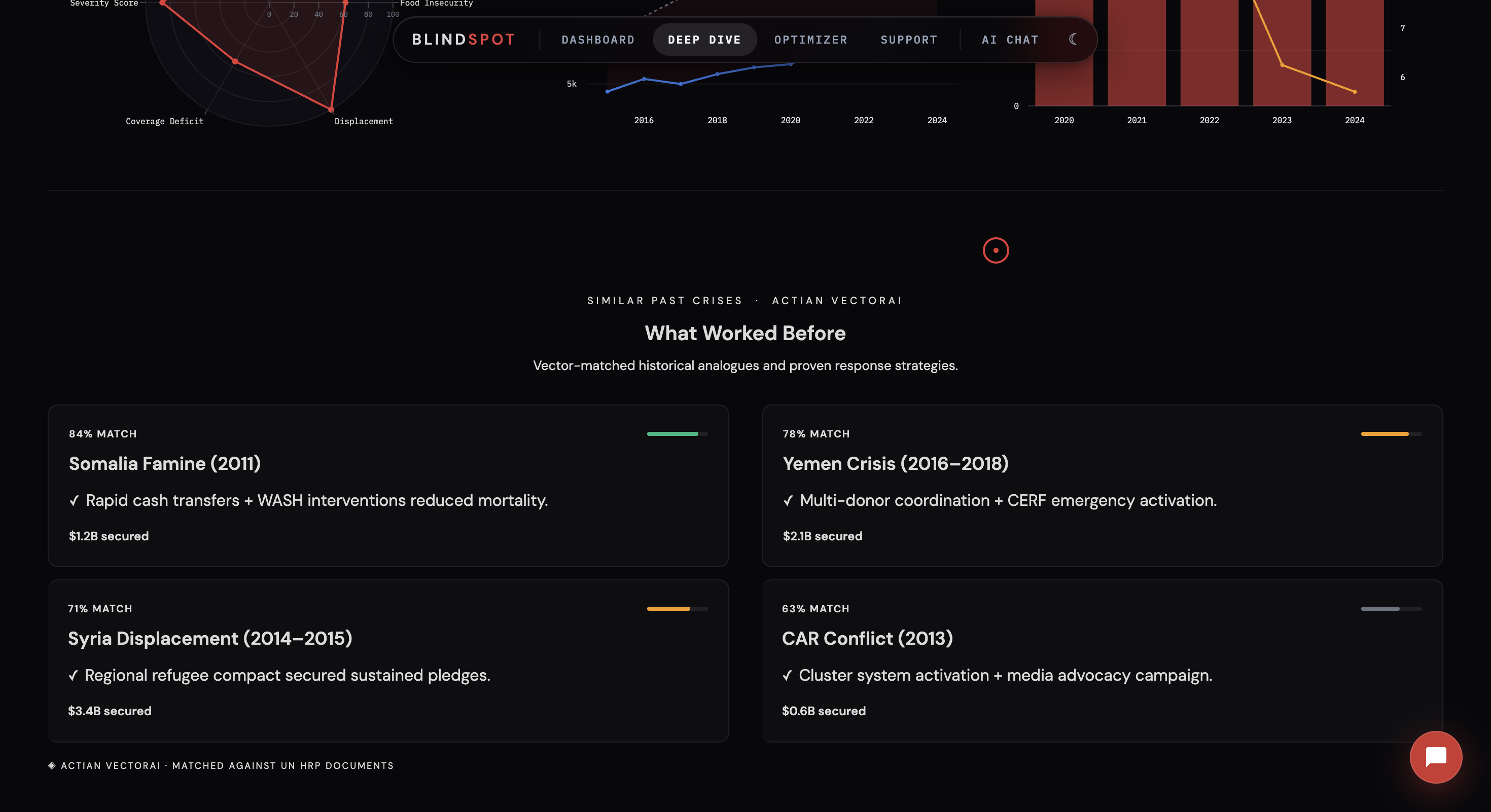
- Actian VectorAI RAG — 2,388 historical UN documents embedded and searched via cosine similarity, powering 3 persona-specific intelligence briefs: Donor, Journalist, and UN Coordinator — each with different motivational hooks pulled from real historical crisis data
How We Built It
We started by cleaning five UN datasets — FTS, UCDP GED, IDMC, IPC, and ReliefWeb — in Databricks using PySpark. Each dataset required careful handling: removing duplicates, filling missing values, filtering by year, standardizing columns, and normalizing numerical data. For example, IPC data was transformed into a food security score using weighted Phase 3+, Phase 4, and Phase 5 populations, then normalized to 0–100.
Next, we combined multiple crisis dimensions — conflict intensity, displacement, food insecurity, funding gaps, and IDP population — to produce a Crisis Severity Score. We used PCA (Scikit-learn) to reduce correlated features into a single interpretable score.
To enhance predictive insight, we built an XGBoost model trained on historical crisis data to predict future severity and funding gaps. Input features included prior-year severity scores, IDP trends, food insecurity, and funding metrics. We optimized the model using hyperparameter tuning (learning rate, max depth, number of trees) with cross-validation to prevent overfitting. This allowed us to anticipate emerging crises before they peak.
For capital allocation, we implemented a SciPy SLSQP optimizer, which takes a total budget and distributes funds proportionally to each country’s severity score, constrained by funding gaps and crisis priorities.
On the Gen AI side, we integrated Google Gemini 2.5 Flash as a domain-restricted assistant, connected to Databricks tables for real-time, factual answers on crisis metrics, country-specific severity, and funding recommendations.
For qualitative intelligence, we embedded 2,388 UN documents into Actian VectorAI. Using TF-IDF with bigrams and cosine similarity, we built persona-specific brief generators (Donor, Journalist, UN Coordinator) that produce actionable summaries from historical reports.
Finally, we built a Streamlit + Plotly dashboard that connects live to Databricks and visualizes:
- Country-level crisis severity scores
- Food insecurity metrics
- Funding gaps and recommended allocations
- XGBoost predicted risk scores
The dashboard also has a CSV fallback mode for offline use, ensuring uninterrupted access.
Pipeline summary:
- Data Cleaning & ETL: PySpark + Databricks → clean tables
- Scoring: PCA for multi-dimensional crisis severity
- Food Security: Weighted IPC Phase 3–5 scoring
- Prediction: XGBoost for future severity/funding gap predictions
- Allocation: SciPy SLSQP optimizer distributes funds proportionally
- AI Assistant: Gemini 2.5 Flash/ Actian VectorDB/Databricks answers crisis queries
- Vector Search: 2,388 UN docs in Actian VectorDB → persona-specific briefs
- Dashboard: Streamlit + Plotly visualizations, live and fallback modes
This architecture combines structured data, predictive ML, AI reasoning, optimization, and unstructured intelligence into one coherent humanitarian decision-support platform.
Challenges we ran into
Python 3.14 incompatibility — sentence-transformers and torch don't support Python 3.14. We pivoted to TF-IDF embeddings with bigrams, achieving meaningful semantic similarity without any neural model or GPU.
Databricks warehouse limits — Hit the free daily SQL warehouse limit mid-hackathon. Implemented a seamless CSV fallback so the dashboard never goes down even without live cluster access.
Data quality — FTS data includes $0 funding entries and values over 100% that skewed results. We filtered these and implemented a 4-category funding status system for more nuanced crisis matching.
Duplicate documents — Initial RAG results returned the same crisis 3 times. Traced to cross-source duplicates and implemented text-level deduplication, reducing the corpus from ~4,000 to 2,388 unique documents.
Accomplishments that we're proud of
- Built a fully working vector RAG system without torch or neural embeddings — proving you don't need GPUs to do meaningful semantic search
- Quantified the cost of media-driven funding bias — our optimizer shows exactly how many lives are lost to misallocation vs optimal allocation, live on the dashboard
- The 3-persona brief system (Donor, Journalist, UN Coordinator) is a genuinely novel interface pattern for humanitarian intelligence — same data, three completely different outputs tailored to what each audience actually needs to act
- Connected Databricks, Actian VectorAI, Gemini, and Streamlit into one coherent pipeline in under 48 hours
- Every number traces back to a real UN data source — zero hallucinated statistics
What we learned
- Vector databases are powerful even without neural embeddings — TF-IDF with bigrams achieves real semantic search over structured humanitarian data
- Actian VectorAI's cortex client is clean, fast, and production-grade
- Humanitarian data is messier than financial data but far more consequential
- The hardest part of any AI system is the data pipeline, not the model
- Audience-specific framing matters — the same crisis data lands completely differently when presented to a donor vs a journalist vs a UN coordinator
What's next for BlindSpot
- Replace TF-IDF with
all-MiniLM-L6-v2sentence embeddings once Python 3.14 support ships - Partner with UN OCHA to integrate live FTS API for real-time funding updates
- Expand to 50+ tracked crisis zones
- Deploy as a live tool for sovereign wealth fund analysts and UN field coordinators
- Add alert system that auto-generates briefs when a crisis score spikes above a danger threshold
- Present the misallocation cost calculation to institutional humanitarian donors as a capital deployment accountability tool





Log in or sign up for Devpost to join the conversation.