-
-

Device
-
Whole Setup

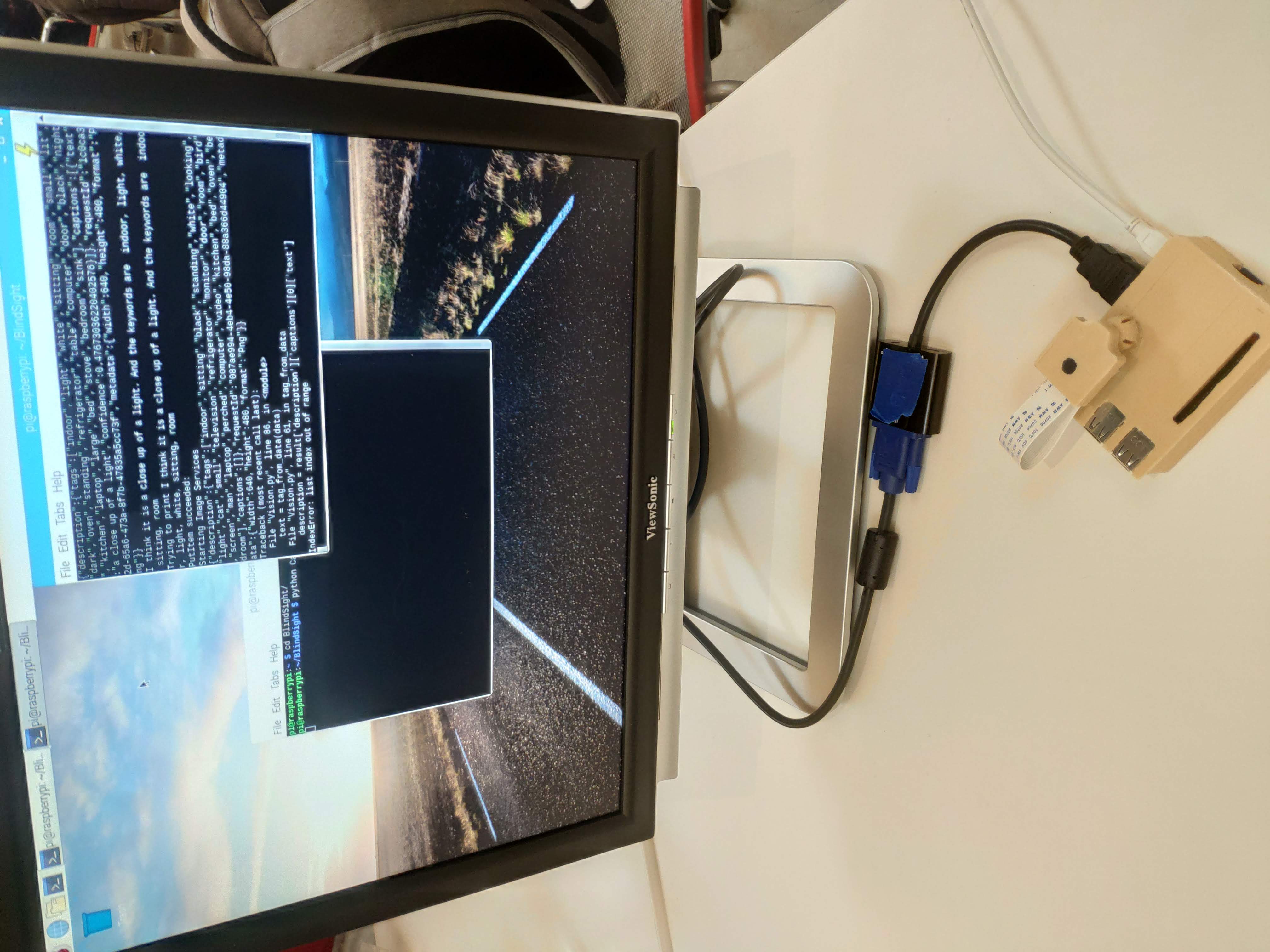
BlindSight
BlindSight is an tool for the visually impaired which narrates the description of scene by taking pictures from an embeded device.
Why:
There are about 300 million visually impaired people in the world. They are not able to experience the world the way we do, and BlindSight aims to provide this ability. The system uses advanced deep learning techniques from Microsoft for image classification, tagging and description.
What:
BlindSight aims bring the world as a 'narrative' to the visually impaired. The narrative is generated by converting the scene in front of them to text, via machine learning. The narration aims to describes the most important objects in the scene. Examples of text include 'A group of people playing a game of football', 'yellow truck parked next to the car', a bowl of salad kept on table'.
How:
The architecture of the system includes Amazon Echo, Dragonboard 410c/Raspberry Pi and online computer vision API's.
A webcam or PiCamera is connected to the Raspberry Pi. The function of the code is to capture the image from the webcam and send it to Microsoft API's for recognition task. The response is then inserted to DynamoDB. When the user asks Alexa to describe the scene, the Alexa Skills Kit triggers Amazon Lambda function to fetch the data from the database (DynamoDB). The correct text is the played as an audio on the Alexa device.
Breakdown of each Program
- Alexa.Json : This file stores the schema for the Alexa Skill used in the project. It contains the trigger words and phrases, along with the acceptable descriptors for the scene
- Camera.py : This program takes one photo every second to allow for semi realtime processing
- DynamoPush.py : This program takes the output from the Microsoft Vision API and processes and uploads it to AWS DynamoDB for processing and serving by Lambda and Alexa
- Lambda.py : This program is the main glue-logic for the project. It coordinates the data in DynamoDB and Alexa and provides the computation for Alexa. It is run on AWS Lambda
- Vision.py : This program queries the Microsoft Vision API by uploading the image to be analyzed and returns with the description and tags of the image.
Process to be followed for Dragonboard/Raspbery pi after getting linux OS up and running
Update the system
Get required libraries
sudo apt-get install python-pip libopencv-dev python-opencv
pip install matplotlib boto3 awscli
Configure for AWS
sudo aws configureand use the AccessKey and Secret AccessKey
Get your key for Microsoft Vision API's
Clone & Setup the code
Open Vision.py and paste the key that you got from previous section
Setup DynamoDB
Give table name (BlindSight) and Primary partition key as guid (String)
Setup Lambda
Copy the code given in 'Lambda.py' to your lambda function Change the table name(and/or region) in the code and the application id of the skill kit(get it from skills kit. it should look like amzn1.echo-sdk-ams.app.xxxx.xxxx)
Setup Alexa Skill
Create a skill and upload Alexa.json to set it up Setup the AWS Endpoint Resource
Install the Alexa app and BlindSight skill
Testing and Notes: "Alexa start BlindSight" (you should hear the response as: "Sure, You can ask me to describe the scene") "Alexa get my user ID" -> Copy the userId and paste it in DynamoPush.py file
Make sure you have python 2.7.9
- Run Camera.py:
python Camera.py
(You should see the images in the same folder) - Run Vision.py:
python Vision.py
(You should see the results in the terminal) - Run DynamoPut.py:
python DynamoPut.py
(Note: this might require sudo access depending on if you used sudo while doing aws configure. It will tell you if update item succedded for DynamoDB) - Speak to Alexa - "Alexa start BlindSight" "describe the scene". If everything went well, you should now hear some relevant to the image that was capture by the camera Example: 'I think it is a yellow truck going on the road and the keywords are road, car, trees, sky'



Log in or sign up for Devpost to join the conversation.