-
-
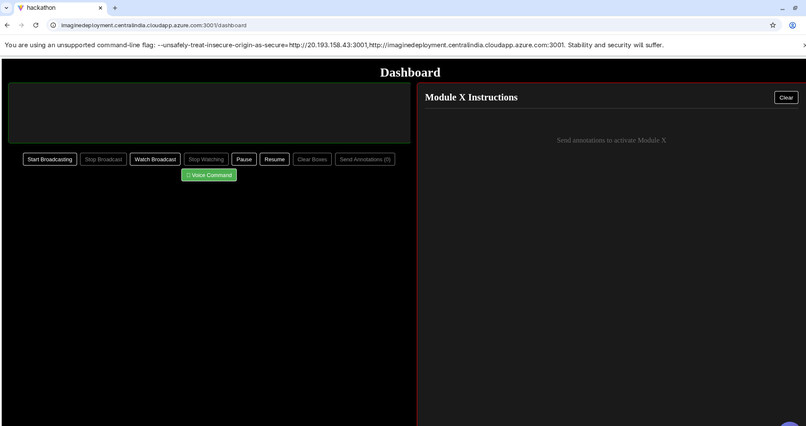
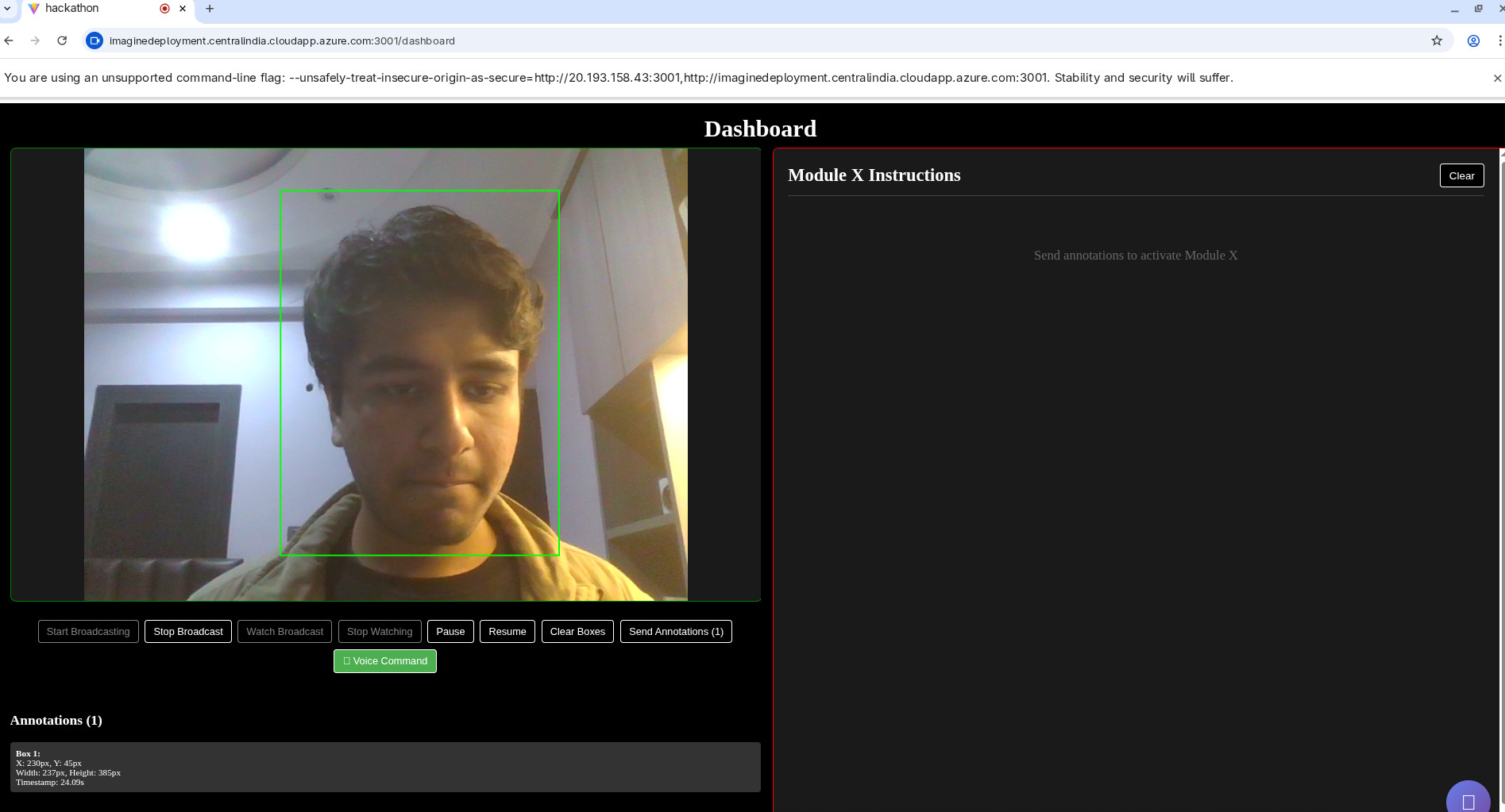
dashboard
-
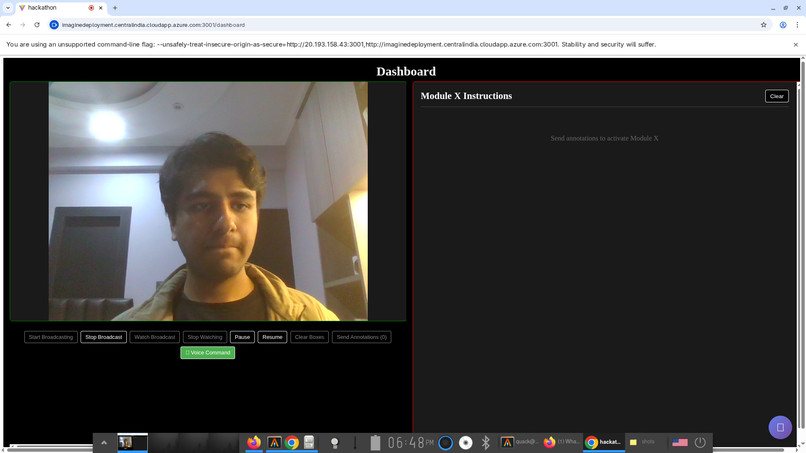
broadcast
-
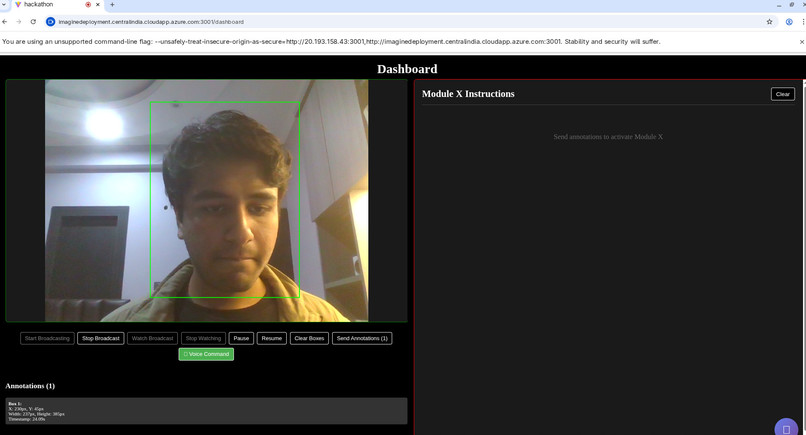
-
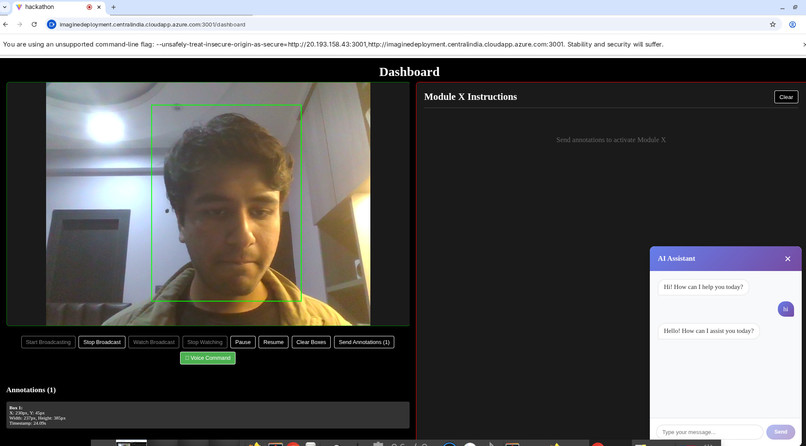
ai agent



Inspiration
For the 2.2 billion people with vision impairment globally, navigation often relies on traditional tools like white canes or guide dogs. While helpful, these tools have limitations in providing detailed environmental context or guiding users to specific, distant objects.
Login Details
username: admin password: 123456
We were inspired by the rapid advancement of multimodal AI and smart glasses. We wanted to bridge the gap between a remote human helper and an autonomous AI agent. Our goal was to create a "digital co-pilot" that doesn't just describe a scene, but actively helps a blind user navigate toward specific goals—leveraging real-time spatial data to provide precise instructions like "walk 1.5 meters forward" rather than vague directions.
What it does
Blinds Vision is a web-based prototype for future smart-glass navigational aids. It operates in two distinct modes to assist visually impaired users:
- Autonomous Navigation: The blind user can issue voice commands (e.g., "Find the exit," "What is in front of me?") using ElevenLabs' Speech-to-Text. The system captures the live video feed, analyzes the surroundings for objects and their precise depth/position, and uses an Agentic AI to provide audio instructions back to the user.
- Human-in-the-Loop Guidance: A sighted guide (friend or family member) can view the user's live video feed via a secure dashboard. If the user is confused, the guide doesn't need to constantly talk; they can simply click/annotate a specific object on the video stream. The system identifies this target and hands it over to the AI agent, which uses calculated depth and angle data to guide the user to that exact spot.
How we built it
We architected the solution using a modular, high-performance approach:
- Frontend Dashboard: Built with React, TypeScript, and Vite, providing a snappy, responsive interface for the guide to view the WebRTC stream and for the blind user to interact via voice.
- Observation Module (The "Eye"): Our backend is a high-speed FastAPI server powered by PyTorch.
- We utilize OpenCV for real-time video frame preprocessing and manipulation.
- For vision tasks, we implemented the Ultralytics YOLO11s-seg-pf (Small Segmentation) pretrained model. This provides pixel-perfect object masks rather than just bounding boxes.
- Crucially, to get 3D data from a 2D camera, we integrated a lightweight ONNX-based depth estimation model. This runs alongside YOLO to generate a depth map for every frame.
- This pipeline returns a JSON payload containing:
depth_m(e.g., 1.5m),direction, andangle_degfor every object.
- Agentic AI Module (The "Brain"): Powered by the newly released GPT-5.2 via Azure OpenAI Service. It ingests the user's goal and the precise telemetry from our FastAPI backend to generate highly accurate navigational commands without "hallucinating" spatial relationships.
- Voice Interface: We integrated ElevenLabs API for natural-sounding Text-to-Speech (TTS) and Speech-to-Text (STT), allowing hands-free operation.
Challenges we ran into
- Mapping 2D Video to 3D Space: Converting a simple 2D image into meaningful spatial instructions was difficult. We had to synchronize the Ultralytics YOLO11 output with our ONNX depth model to calculate the average depth within a specific object's segmentation mask, allowing the AI to say "Turn 20 degrees right" with confidence.
- Real-Time Latency: Running two heavy models (YOLO segmentation + Depth Estimation) on every frame introduced lag. We optimized this by using FastAPI's asynchronous capabilities and running the depth model via ONNX Runtime for faster inference compared to standard PyTorch.
- Prompt Engineering for Navigation: Even with GPT-5.2, we needed strict system prompting to interpret raw JSON data into safe human instructions without overwhelming the user.
Accomplishments that we're proud of
- Spatial Awareness: Successfully implementing a backend that fuses YOLO11 segmentation masks with ONNX depth maps. This elevates the project from a simple "image describer" to a true "navigational assistant."
- Tech Stack Harmony: Getting FastAPI, OpenCV, and WebRTC to stream and process video in near real-time.
- Seamless "Hand-off" Logic: The ability for a human guide to click a target and have the AI immediately take over the micro-navigation using the coordinate data.
What we learned
- Data Precision Matters: We learned that an AI agent is only as good as the data it observes. Providing raw JSON with depth and angles allowed the LLM to be significantly more useful than when we only provided text descriptions.
- The Power of ONNX: We discovered that exporting our depth models to ONNX significantly improved our inference speed, making the system viable for real-time usage.
- Hybrid Systems: We discovered that AI is powerful, but having a "Human in the Loop" for establishing ground truth (selecting the destination) makes the system significantly more reliable in complex environments.
What's next for Blinds Vision
- Hardware Integration: Moving from a web browser prototype to an app running on actual smart glasses (e.g., Vuzix or Ray-Ban Meta).
- Edge Computing: Migrating the YOLO model and a smaller LLM to run locally on the device to reduce latency and allow offline usage.
- Haptic Feedback: Integrating vibration feedback (e.g., buzz left to turn left) to complement the audio instructions.
- LiDAR Integration: Using hardware with actual LiDAR sensors to replace our software-based depth estimation for millimeter-level accuracy.



Log in or sign up for Devpost to join the conversation.