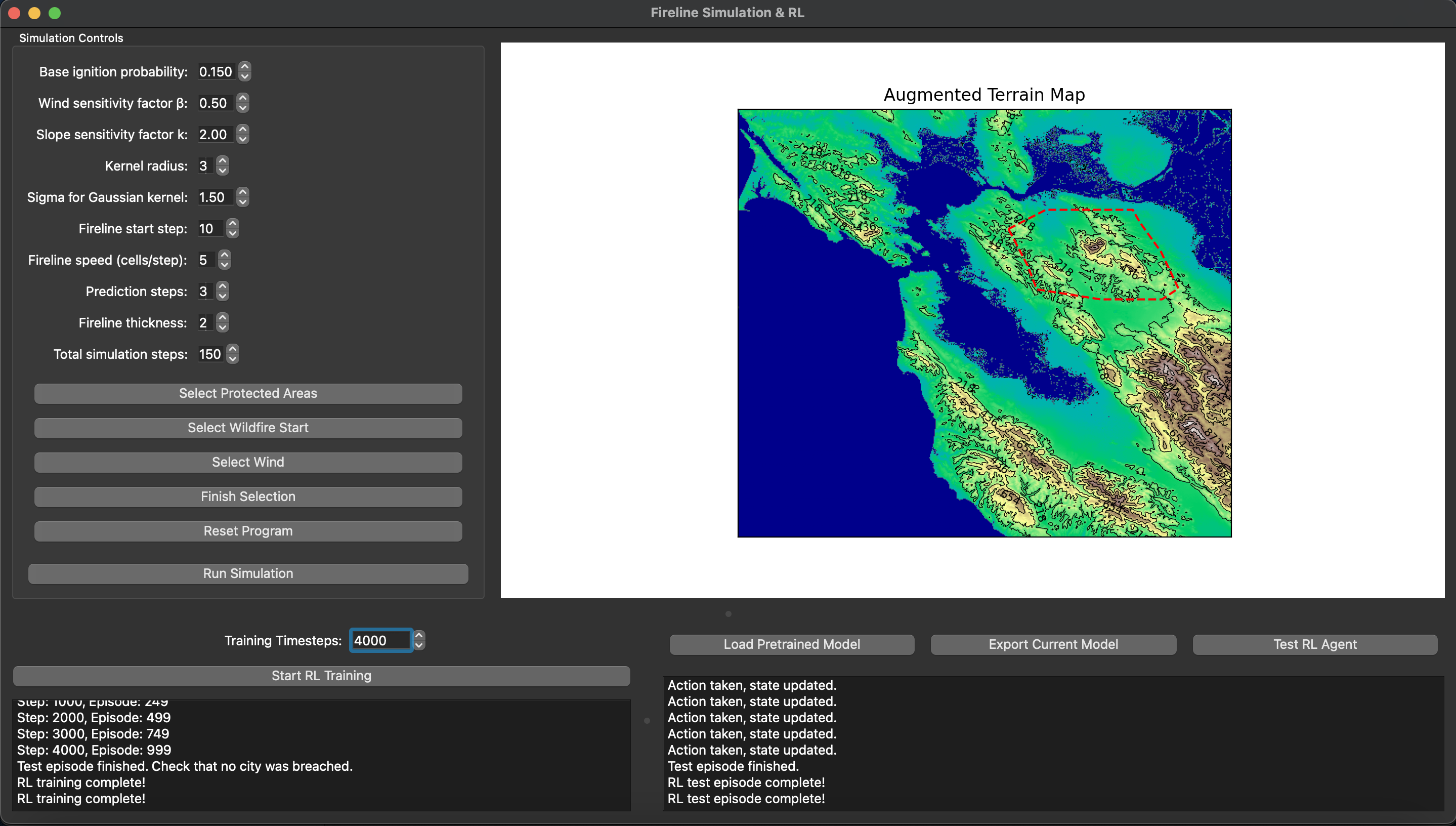
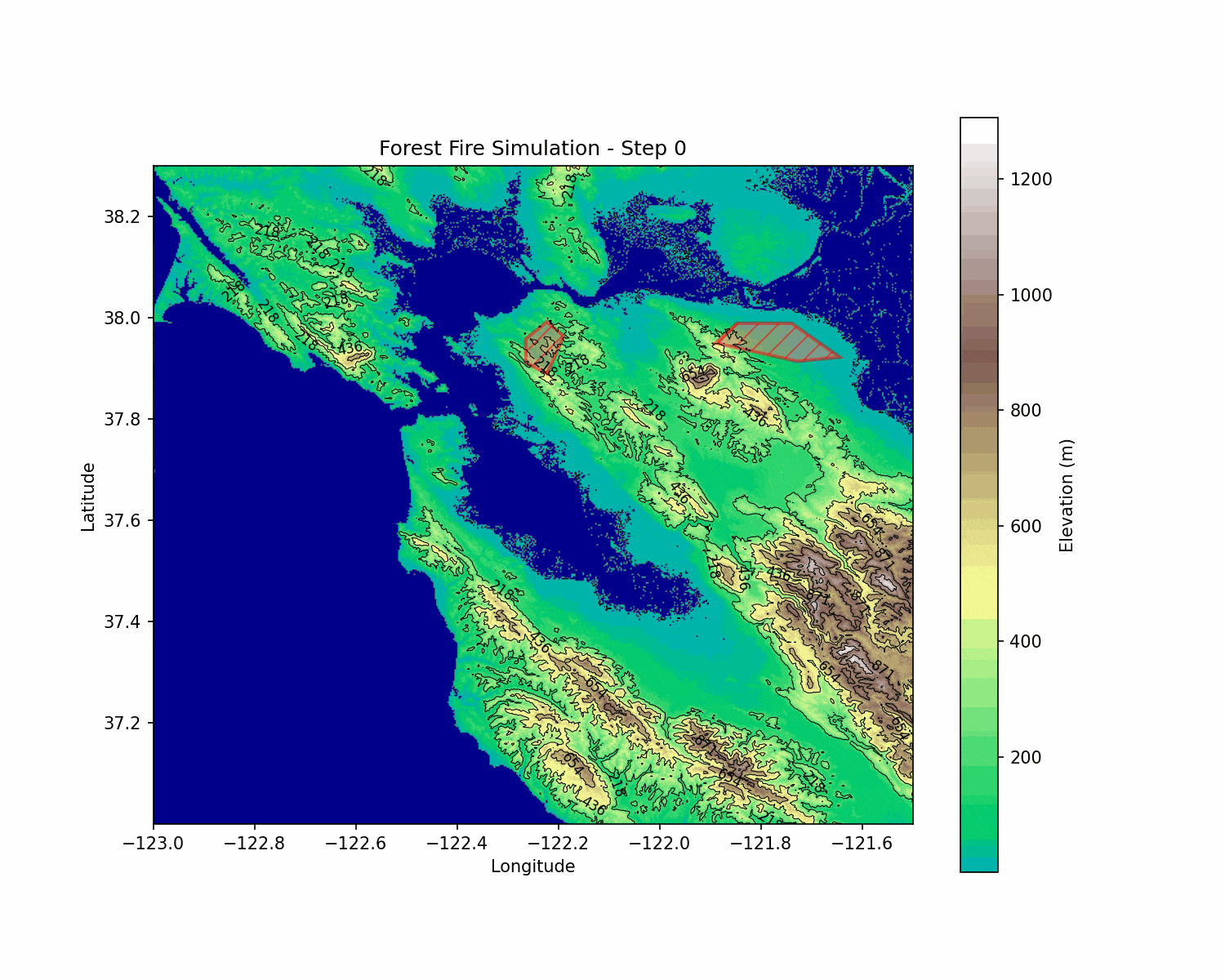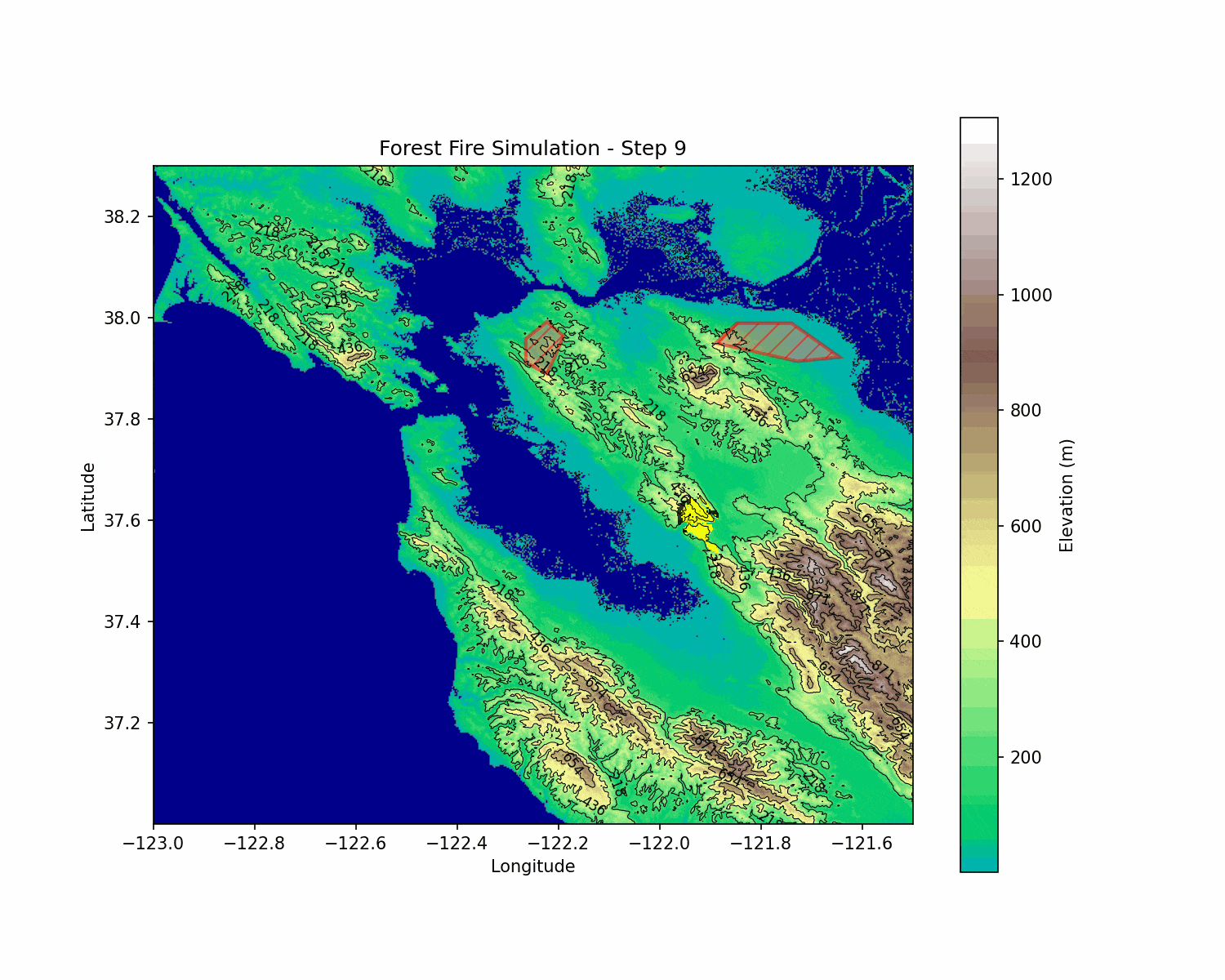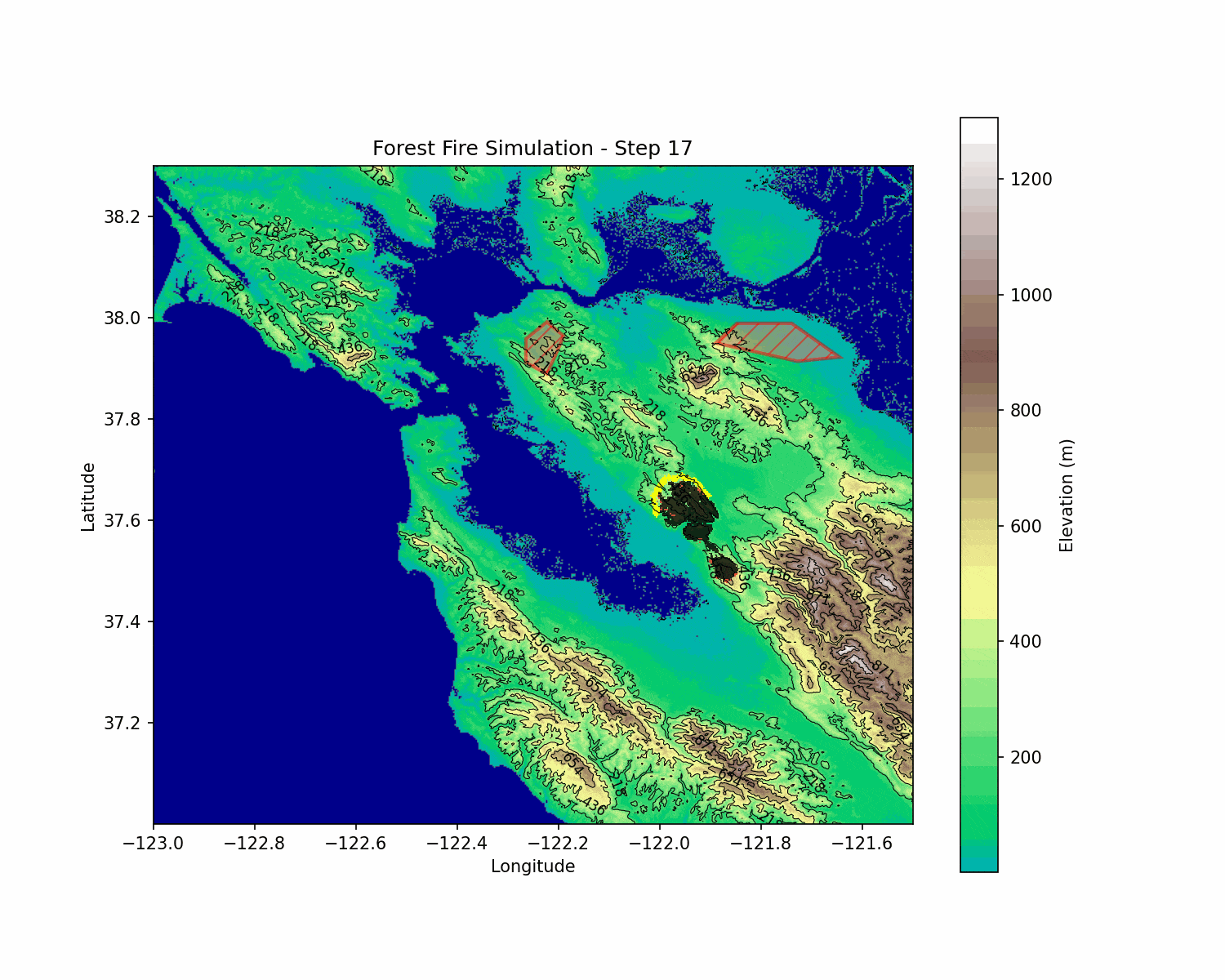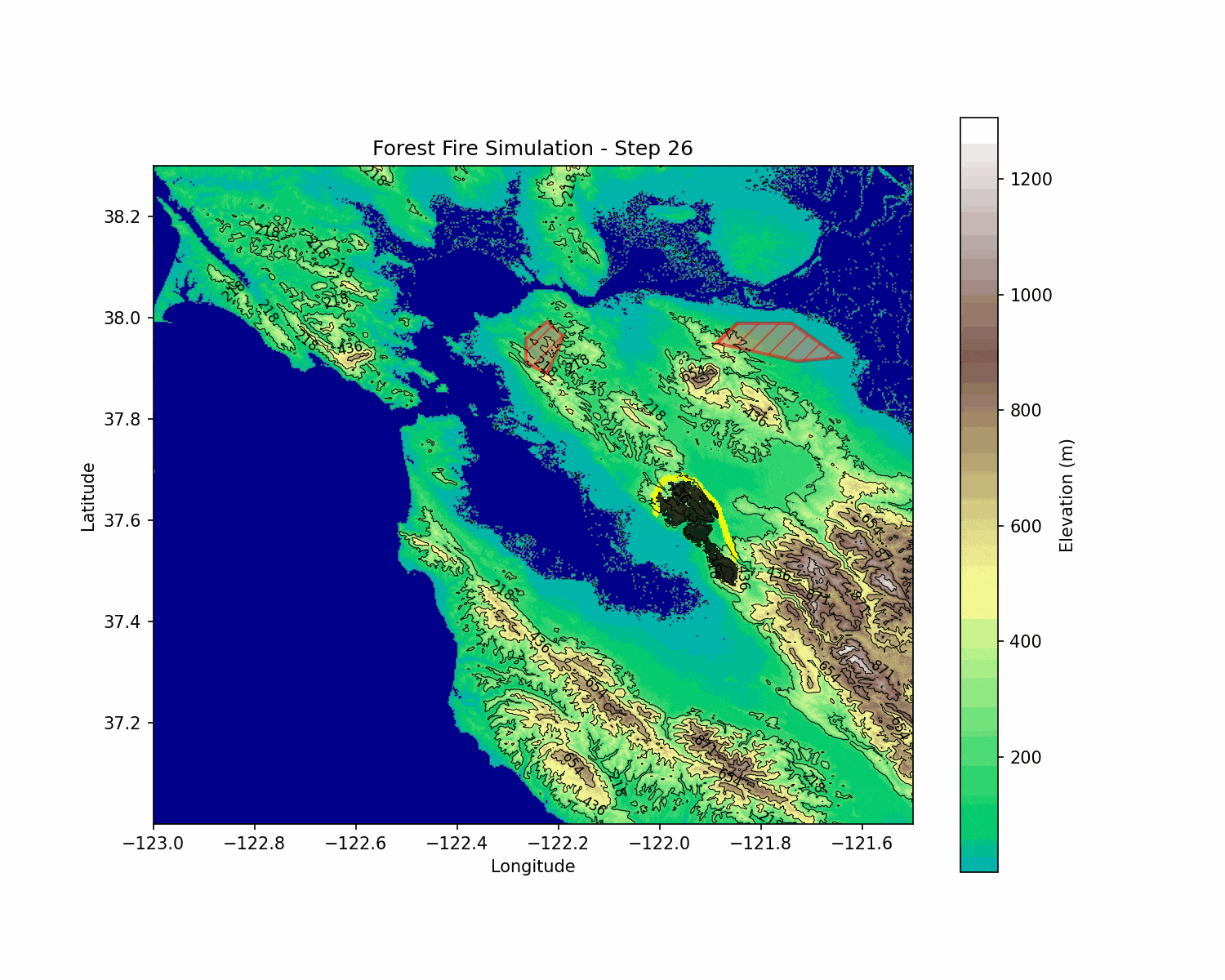
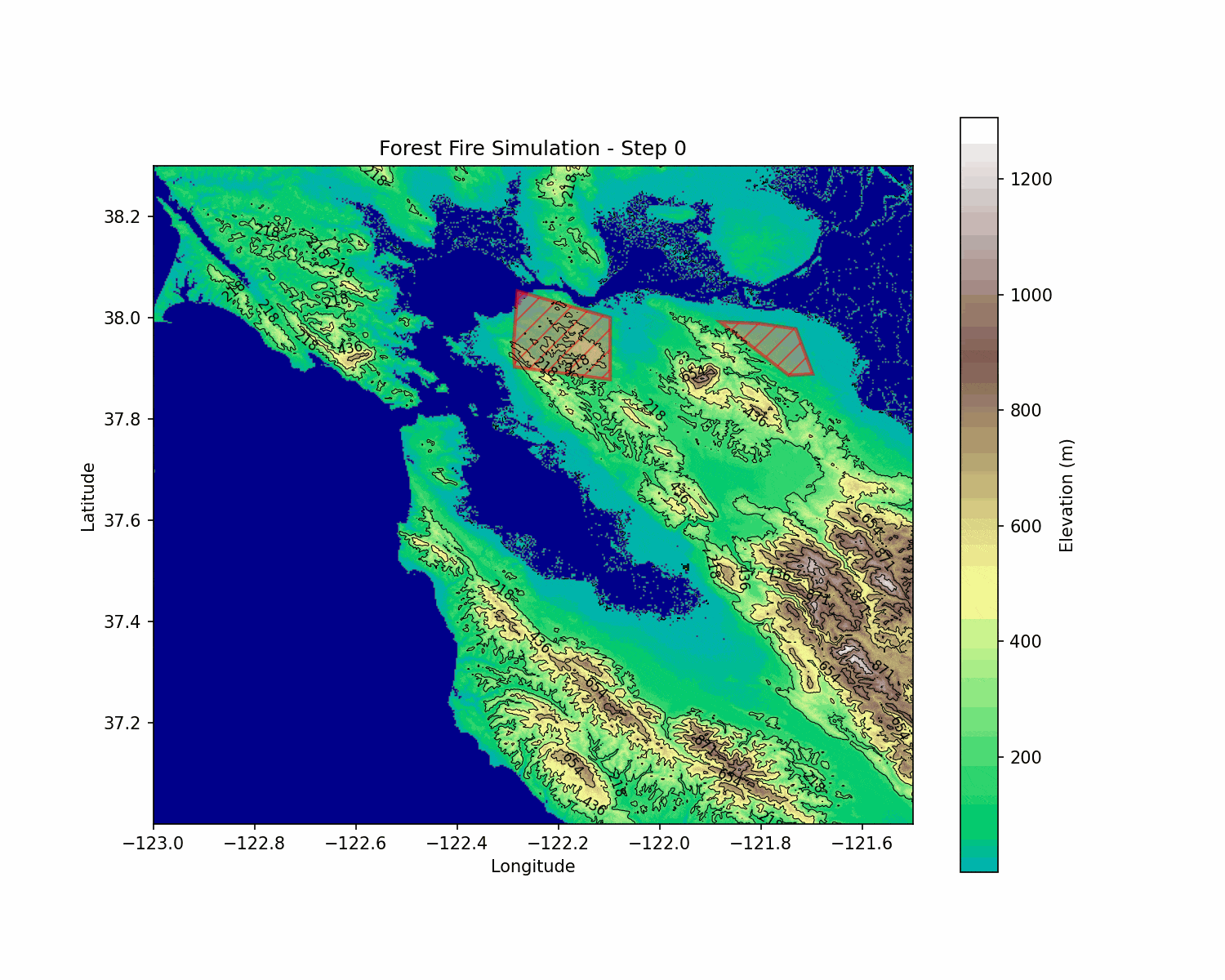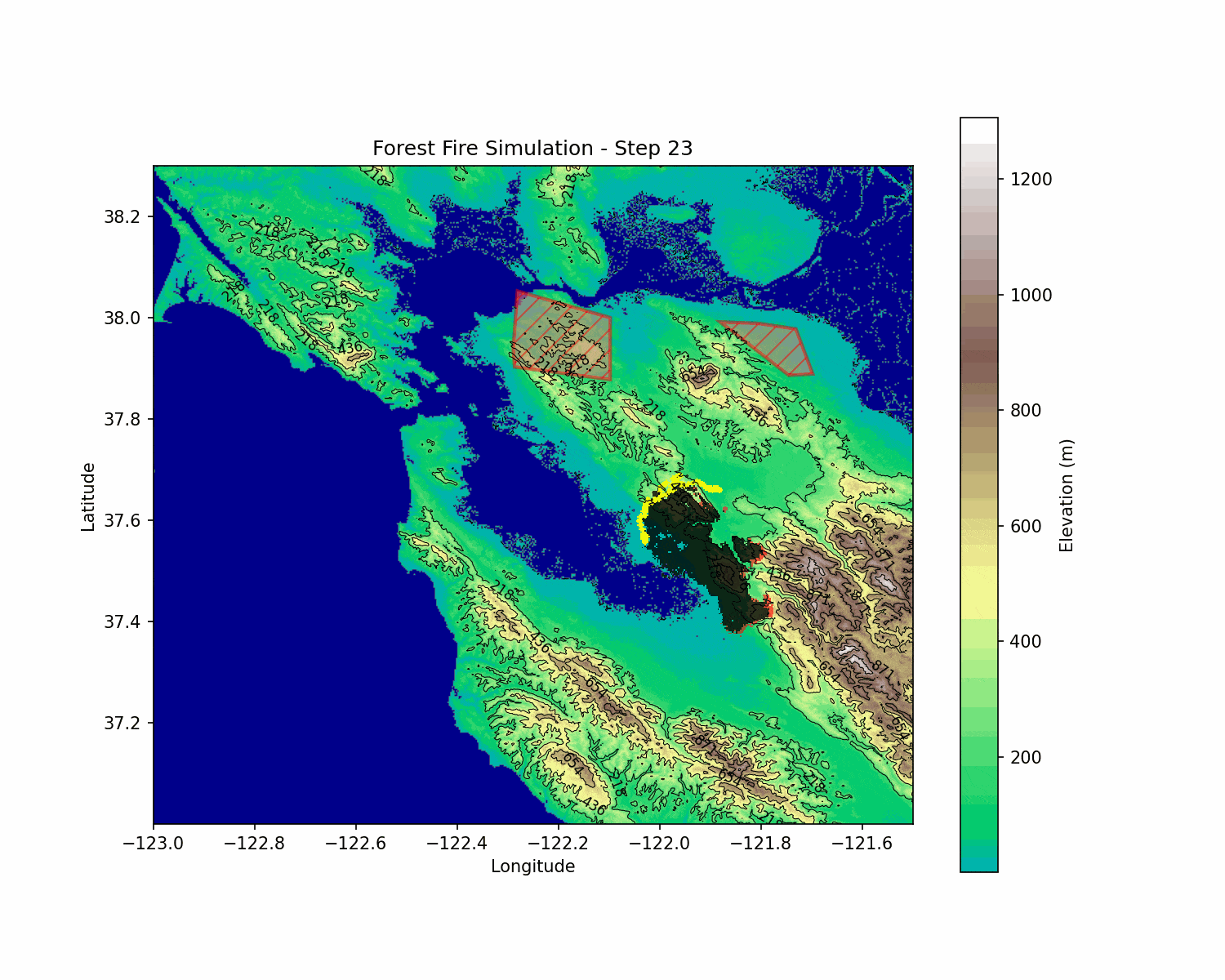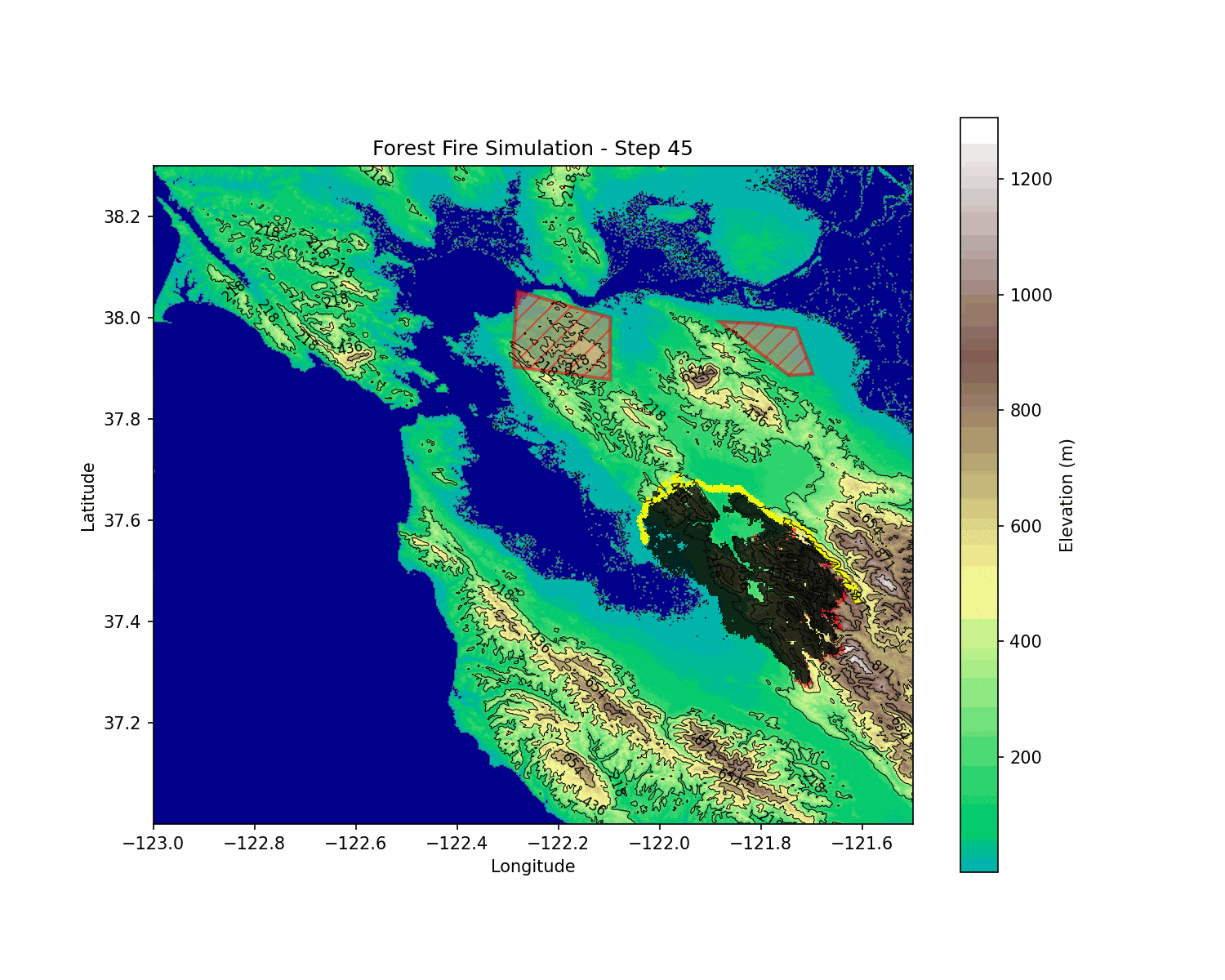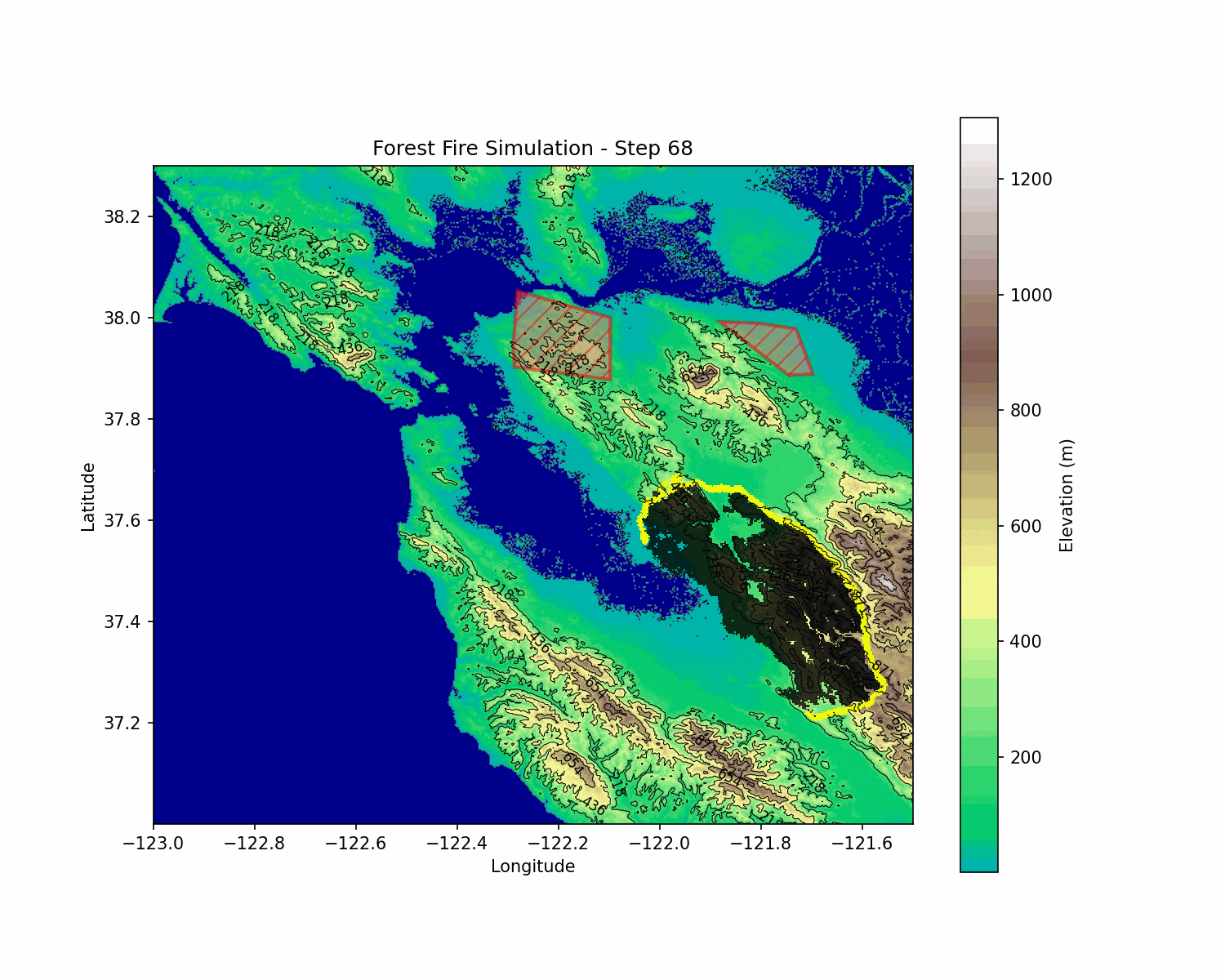
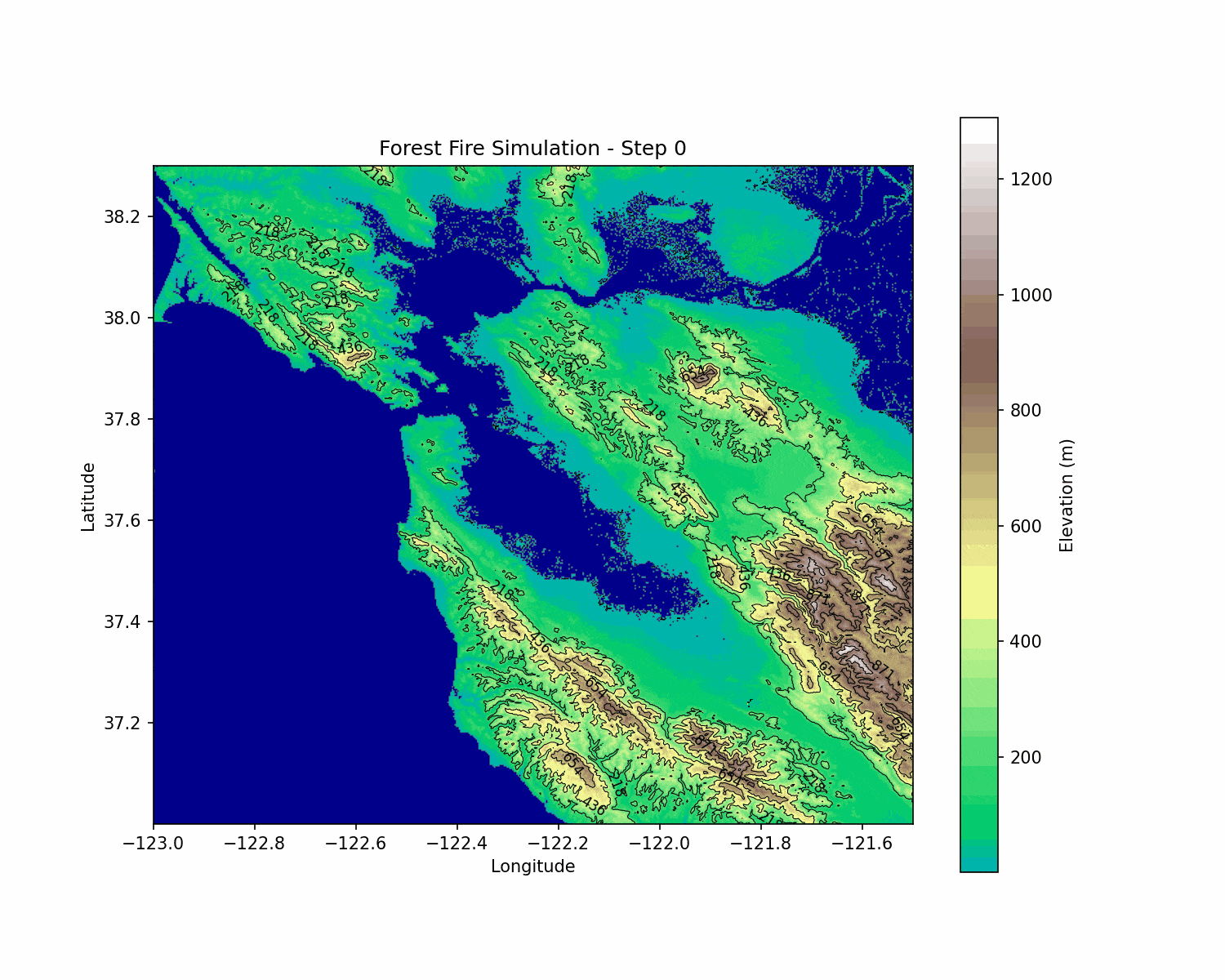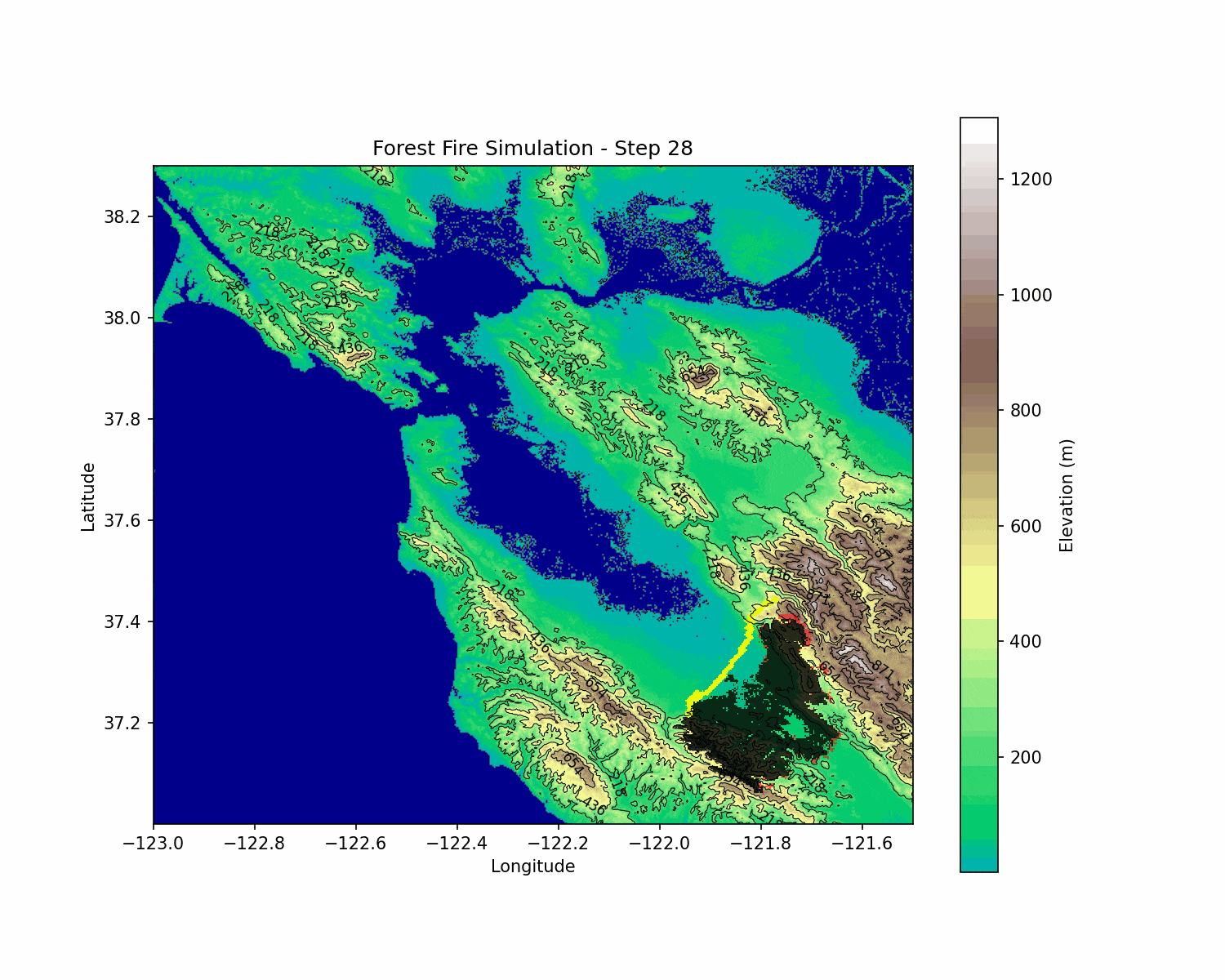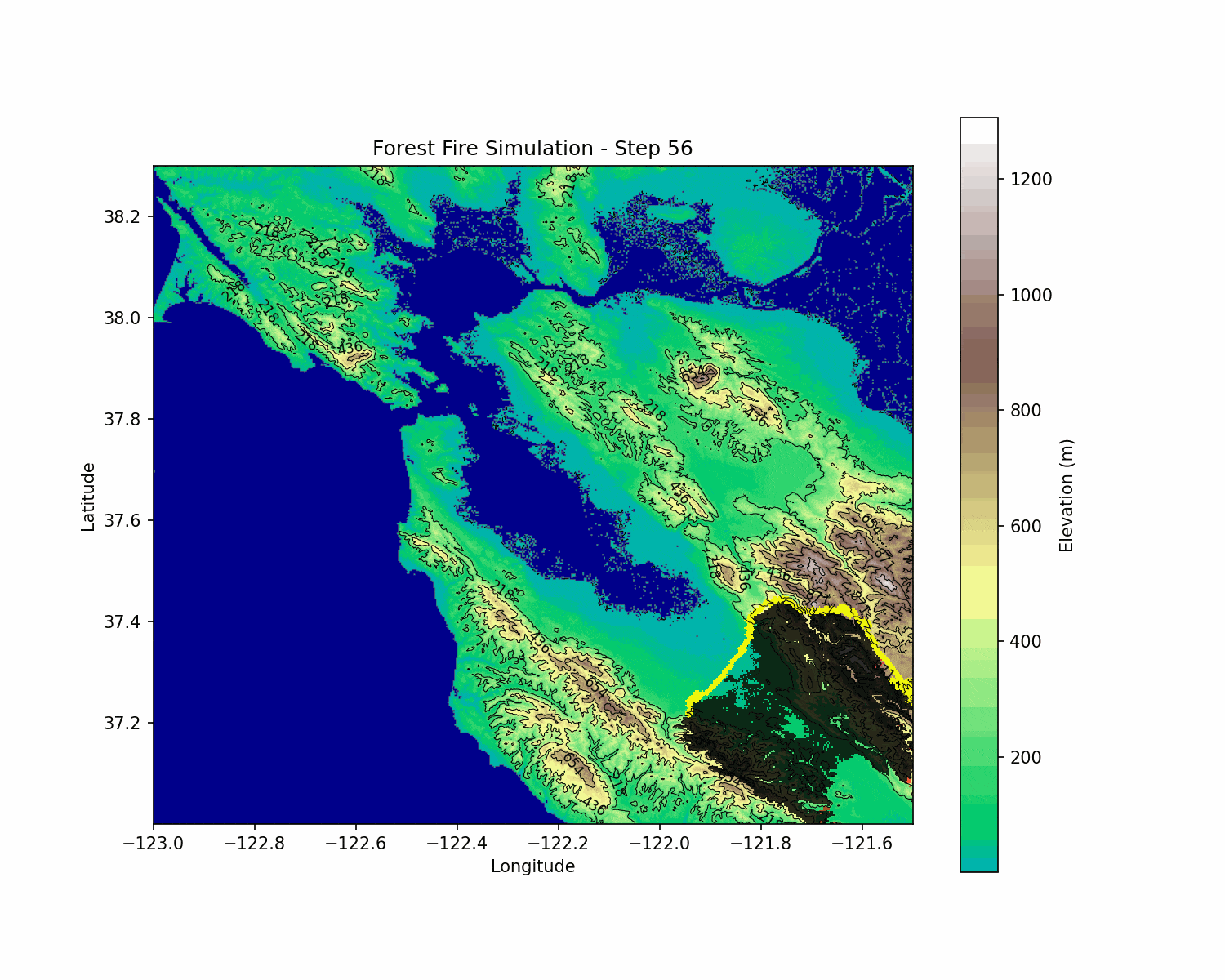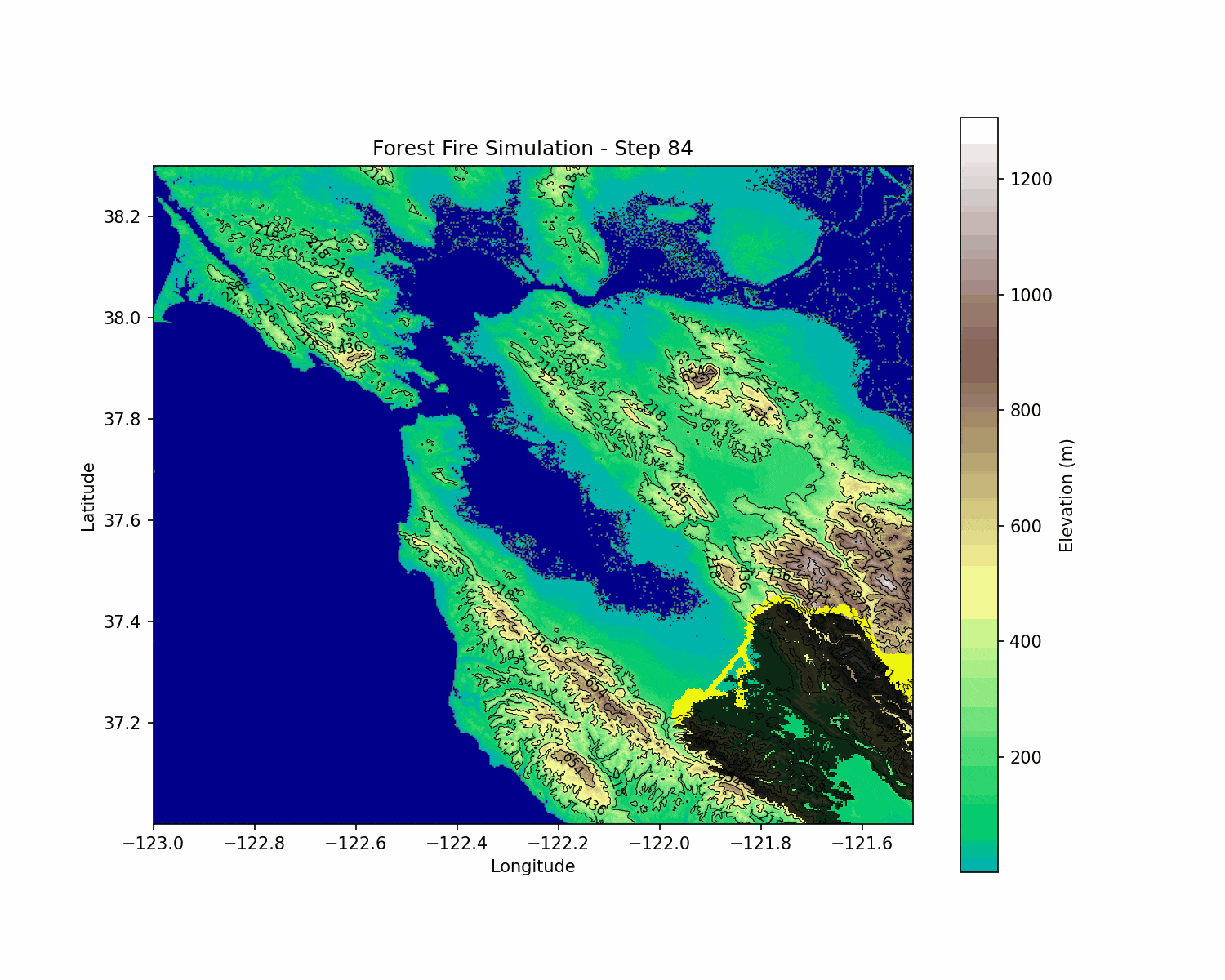
BlazeShield: Wildfire Defense & Strategy Simulator
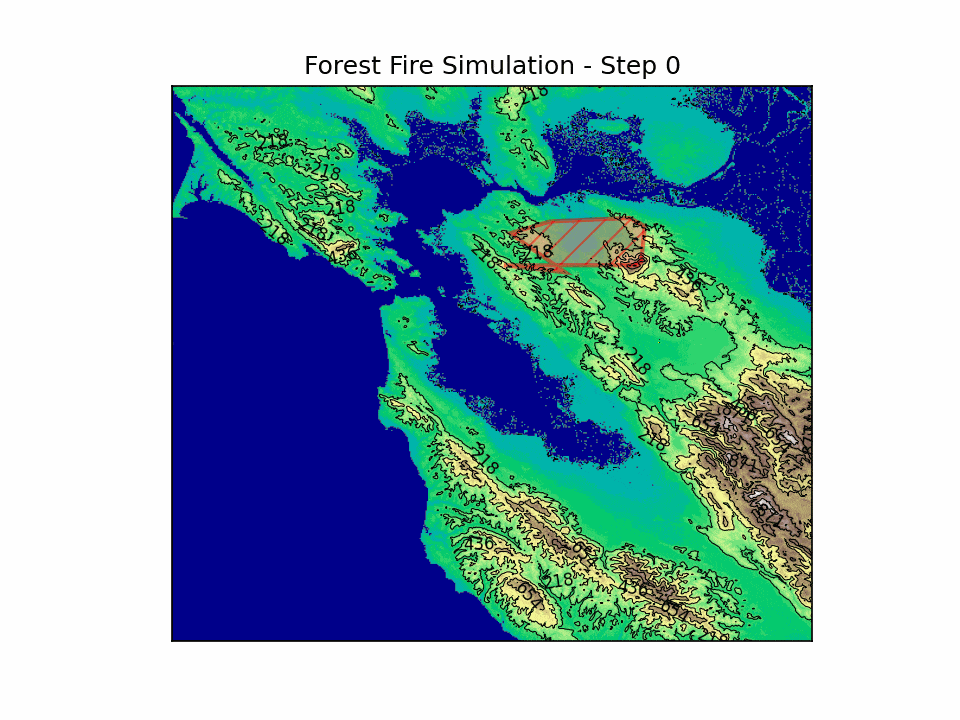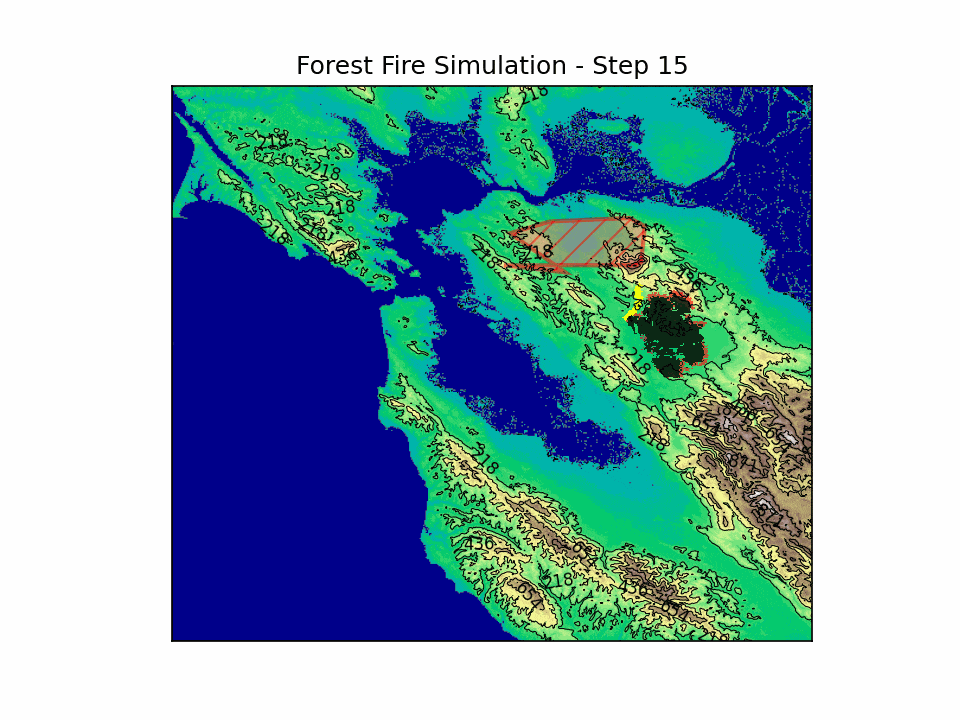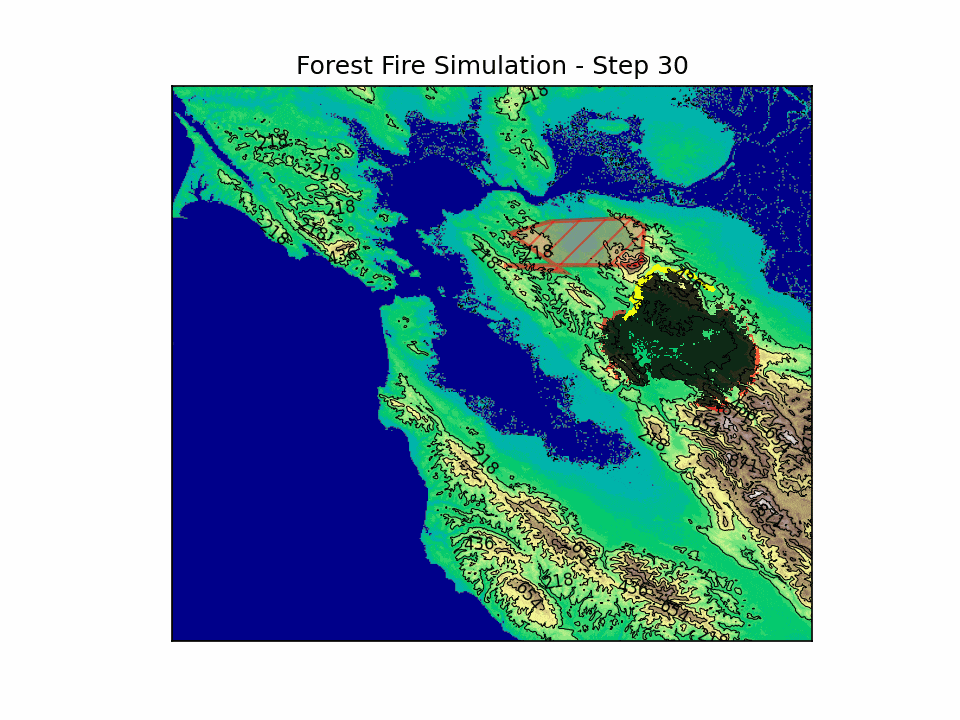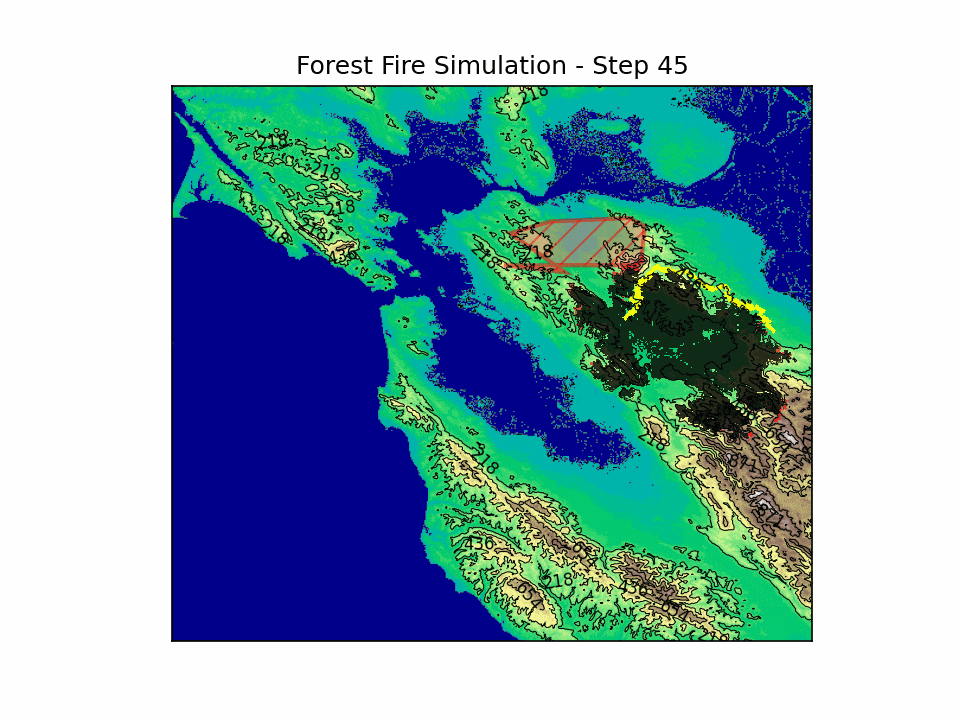
BlazeShield is a simulation framework designed to model wildfire propagation and optimize the placement of firelines using reinforcement learning. The inspiration for the project came while playing Pokemon Brick Bronze on Roblox.
1. Mathematical Modeling of Wildfire Spread
1.1. Cellular Automata Framework
The simulation is built on a grid-based cellular automata model. Each cell in the two-dimensional grid represents a patch of terrain with its state defined as follows:
- 0: Unburned (vegetation present)
- 1: Currently burning
- 2: Burned out
- 3: Fireline (protected area)
The state of the system is represented as S(i, j) for the cell at position (i, j).
1.2. Probabilistic Fire Spread
The ignition probability p₍ᵢⱼ₎ for an unburned cell (i, j) due to a neighboring burning cell is given by:
p₍ᵢⱼ₎ = p_base × W(d₍ᵢⱼ₎) × exp(β × V × cos(θ₍ᵢⱼ₎)) × exp(k × arctan(Δz₍ᵢⱼ₎))
Where:
p_base is the base ignition probability (a constant).
Gaussian Weight, W(d₍ᵢⱼ₎):
W(d₍ᵢⱼ₎) = exp( – (d₍ᵢⱼ₎²) / (2 × σ²) )
Here, d₍ᵢⱼ₎ is the Euclidean distance between the burning cell and the candidate cell, and σ is the spread parameter.Wind Influence:
exp( β × V × cos(θ₍ᵢⱼ₎) )
where β is the wind sensitivity factor, V is the wind speed, and θ₍ᵢⱼ₎ is the angle between the wind direction and the vector from the burning cell to (i, j).Slope Influence:
exp( k × arctan(Δz₍ᵢⱼ₎) )
where k is the slope sensitivity parameter, and Δz₍ᵢⱼ₎ is the elevation difference between the burning cell and the candidate cell.
1.3. Fireline Formation
To counter the wildfire, the simulation also models deliberate fireline placement using several geometric techniques:
Convex Hull Computation:
The set of burning cells { (x, y) such that S(x, y) is 1 or 2 } is used to compute the convex hull, which approximates the perimeter of the fire.Bresenham’s Line Algorithm:
The continuous convex hull boundary is discretized into grid-aligned cells using Bresenham’s algorithm, ensuring efficient and accurate line drawing.Neighborhood Connectivity:
A search over the eight-connected neighborhood (using breadth-first search if necessary) ensures that any candidate fireline cell remains connected to the existing fireline structure.
2. Reinforcement Learning Component
2.1. Environment Formulation
The RL environment is defined in accordance with the OpenAI Gym interface. The key characteristics are:
State Space:
A vector representation (placeholder in the current prototype) of the simulation's status.Action Space:
A discrete set corresponding to candidate cells along the grid perimeter where a fireline can be placed.
2.2. Reward Function
The reward is engineered to penalize:
- Breaches in protected areas (e.g., cities)
- Excessive loss of vegetation
Let:
- C₍city₎ be the cost for a breach in a protected area.
- C₍veg₎ be the cost for burned vegetation.
The overall reward R is defined as:
R = – ( λ₍city₎ × C₍city₎ + λ₍veg₎ × C₍veg₎ + δ × I{breach} )
Where:
- λ₍city₎ and λ₍veg₎ are weighting factors.
- I{breach} is an indicator function that equals 1 if any protected area is breached.
2.3. Deep Q-Network (DQN)
The RL agent employs the Deep Q-Network (DQN) algorithm, which estimates the optimal action-value function Q*(s, a) using a neural network. Key components include:
Experience Replay:
A replay buffer stores past transitions (s, a, r, s′) that are sampled randomly to reduce correlation.Target Network:
A separate network, updated periodically, helps stabilize training.Loss Function:
The DQN minimizes the temporal difference error given by:
L(θ) = E₍s,a,r,s′₎ [ (r + γ × max₍a′₎ Q_target(s′, a′; θ⁻) – Q(s, a; θ))² ]
where γ is the discount factor, θ represents current network parameters, and θ⁻ represents target network parameters.
3. Integration of Simulation and Reinforcement Learning
3.1. Coupling the Two Systems
The wildfire simulation evolves according to the probabilistic rules described above. The RL agent interacts with this environment by choosing fireline placement actions that affect the subsequent evolution of the fire. This coupling creates a challenging non-linear optimization problem under uncertainty.
3.2. Theoretical Considerations
Key theoretical aspects include:
Non-linear Dynamics:
The use of exponential functions to model wind and slope effects introduces strong non-linearities, requiring careful tuning of parameters (β, k, and σ).Stochastic Processes:
Random ignition events and varying environmental factors (such as wind and topography) imply that the model is inherently stochastic.Optimization under Uncertainty:
The RL agent must learn to make decisions that minimize cumulative penalties (from breaches and vegetation loss) in a probabilistic environment.Geometric Computations:
Techniques such as convex hull calculation and Bresenham’s line algorithm integrate geometric reasoning into the simulation, ensuring that fireline placements are spatially coherent and adaptive.
4. Conclusion
BlazeShield integrates mathematical modeling, geometric algorithms, and deep reinforcement learning to address wildfire spread and defense. By modeling fire spread with a probabilistic cellular automata approach—incorporating wind, slope, and spatial decay—and coupling it with an RL agent trained using DQN, BlazeShield explores strategic interventions in dynamic, uncertain environments.
This technical synthesis advances our understanding of wildfire dynamics and paves the way for developing robust, data-driven strategies for disaster mitigation.

Log in or sign up for Devpost to join the conversation.