Inspiration
This is a project that aims to combat the spread of fake news and misinformation in the financial sector. The World Economic Forum has identified the spread of fake news as one of the top global risks, with an estimated cost of $78 billion per year to the global economy. In particular, the financial sector is particularly vulnerable to the effects of fake news, with a single incident has caused a $300 billion loss in the stock market. Our research estimates that fake news could potentially result in a loss of up to 0.05% of stock market value.
Fake news not only has direct costs, but also indirect effects on individuals, communities, and society. These indirect costs can include an impact on quality of life, increased fear, or changes in behaviour. To address this issue, we have developed an API that uses an innovative Graph Neural Network (GNN) approach to detect fake news. This approach utilizes both intrinsic features extracted from the news article and extrinsic features such as the user propagation graph of the article to determine its validity. This is a unique approach compared to traditional Machine Learning and Deep Learning models that only use intrinsic features. By utilizing this innovative approach, we hope to effectively combat the spread of fake news in the financial sector and minimize the potential losses caused by misinformation.
What it does
Our web-based application was created to address the issue of fake news in the financial sector. It uses a two-pronged approach to determine the veracity of a news article URL. This method incorporates user data and Twitter propagation graphs, as well as cutting-edge technology like Graphical Convolutional Networks (GCN), a type of deep learning algorithm. Using user data and Twitter propagation graphs, our application can identify patterns and connections that traditional methods may miss. This enables us to detect fake news and misinformation more effectively. The application is simple to use; simply enter the URL of the news article and the application will determine the veracity of the news.
How we built it
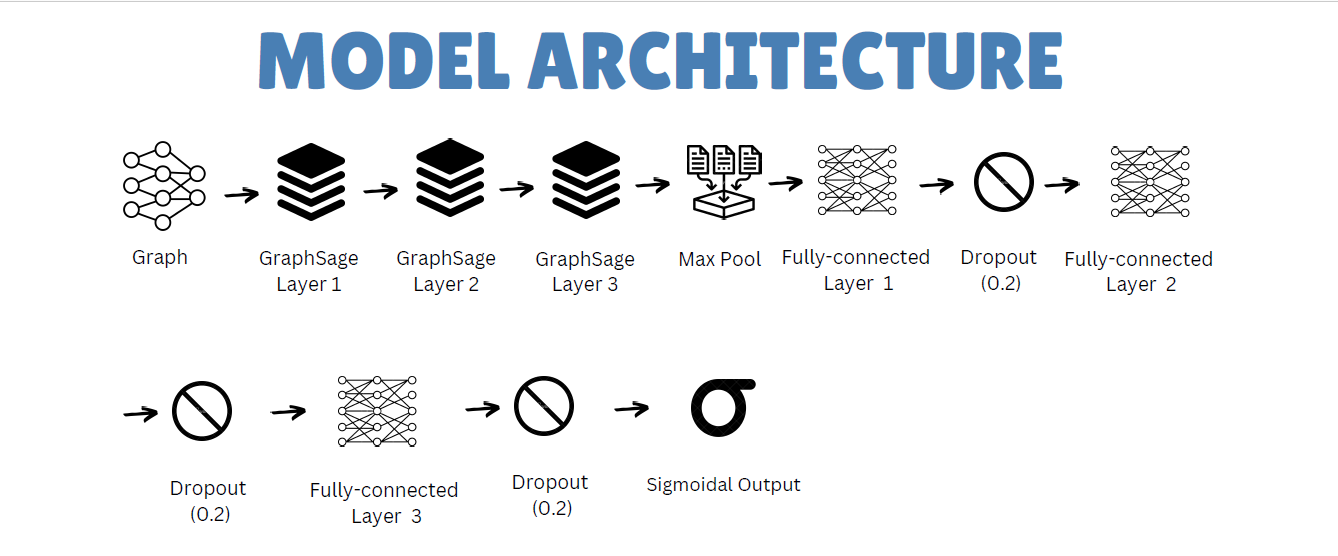
Our application was developed using a variety of open-source tools and libraries, including Twitter-API and Python libraries such as PyTorch, PyTorch-geometric, NetworkX, BeautifulSoup, NLTK, and Scikit-Learn. PyTorch is a powerful deep learning library that allows us to train and deploy neural networks, while PyTorch-geometric is a library developed and maintained by Standford University that is specifically designed for graph data and deep learning on graphs. NetworkX is a library for the creation, manipulation, and study of the structure, dynamics, and functions of complex networks. BeautifulSoup is a library for pulling data out of HTML and XML files, while NLTK is a library for natural language processing. Scikit-Learn is a library for machine learning in Python.
The website is built with the Django framework, which allows us to easily create and manage web pages and serves as an API endpoint. To integrate endogenous and exogenous information, we use Graph Neural Networks (GNN) with vector representations of news and users as node features. GNN are a type of deep learning algorithm that can process and analyze graph-structured data. This allows us to effectively detect fake news by identifying patterns and connections that may not be apparent with traditional methods. Overall, the combination of these libraries and frameworks allows us to create an application that is efficient, reliable, and user-friendly, and can effectively detect fake news in the financial sector.
Challenges we ran into
The Twitter-API has a limitation of 15 calls every 15 minutes, which can be a problem for our application. To overcome this limitation and make our application more efficient and user-friendly, we have developed custom web-scraping algorithms for data wrangling and scheduling. These algorithms allow us to collect large amounts of data in a short period, without hitting the API's call limit.
Another issue that we encountered was encoding users' tweet histories using word embeddings and feature vectors of their respective user profiles. Word embeddings are a method used to represent words and phrases in a numerical format, making it easy to process using machine learning algorithms. However, with a large number of tweets, the process of encoding these tweets can be time-consuming and resource-intensive. To overcome this, we have developed a strategy for efficiently encoding users' tweet histories, using a combination of word embeddings and the feature vector of their respective user profiles. This allows us to quickly and accurately analyze a user's tweets, without overwhelming our resources.
In summary, our application has been designed to tackle the problem of fake news in the financial sector by using a two-pronged approach that incorporates user data and Twitter propagation graphs, in addition to cutting-edge technology such as Graphical Convolutional Networks (GCN). To overcome the limitation of the Twitter-API, we have developed custom web-scraping algorithms for data wrangling and scheduling, and a strategy for efficiently encoding users' tweet histories.
Accomplishments that we're proud of
Our application utilizes a two-fold approach to effectively detect fake news in the financial sector. The first prong is to model the user's endogenous preference by encoding news content and user historical posts using various text representation learning techniques. This includes methods such as word embeddings, which allow us to represent text data in a numerical format, making it easy to process using machine learning algorithms. The second prong is to obtain the user's exogenous context by building a tree-structured propagation graph for each news based on its sharing cascading on social media. This allows us to identify patterns and connections that may not be apparent with traditional methods.
By using this two-pronged approach, we have been able to beat the State-of-the-Art models and their benchmarks. Our application outperforms existing solutions in detecting fake news, with a higher accuracy and precision rate. Additionally, our application is user-friendly and easy to use, allowing users to quickly and easily determine the veracity of a news article. With this application, we hope to help combat the spread of fake news and misinformation in the financial sector and minimize the potential losses caused by misinformation.
What we learned
We learned several valuable lessons while developing this application. When detecting fake news, one of the most important lessons we learned was the importance of incorporating both endogenous and exogenous information. We were able to identify patterns and connections that were not apparent with traditional methods by encoding news content and user historical posts using text representation learning techniques and building a tree-structured propagation graph for each news based on its sharing cascading on social media.
We also learned how to detect fake news using cutting-edge technology such as Graph Neural Networks (GNN). GNNs are a type of deep learning algorithm that can process and analyze graph-structured data, allowing us to identify patterns and connections that traditional methods may miss. Finally, we discovered that detecting fake news is a difficult task that necessitates the use of a variety of techniques such as text representation, deep learning, and data wrangling. We discovered that a combination of intrinsic and extrinsic information is required to create an efficient and accurate fake news detection model.
What's next for Blazers
There are several additional features that we can add to the application in the future to make it even more effective in detecting fake news in the financial sector. One of the most important features we can add is the integration of stock indices. By incorporating stock indices, we can analyze the potential impact of a news article on the stock market and provide users with real-time information about the potential impact of a news article on the stock market. This can help users make more informed decisions about their investments and can help minimize the potential losses caused by misinformation.
Another feature we can add is the integration of real-time financial data. By incorporating real-time financial data, we can provide users with up-to-date information about the financial market and help them make more informed decisions about their investments. This can include information about stock prices, market trends, and other important financial data.
Additionally, we can add a feature that allows users to flag or report fake news articles, this can help us to improve the accuracy of our application by allowing users to report articles they believe to be false. This feature can be integrated with social media platforms such as Twitter and Facebook, allowing users to report fake news articles directly from these platforms.
Constraints
As this project relies on the Twitter API during the Graph Generation phase, it is important to keep the following points in mind during use to prevent any crashes due to exceeding the API limits provided by the free tier.
- The API only allows 300 Tweet Lookup requests per 15-minute window. Keeping this in mind we request sending not more than 3 requests to our API every 15 mins.
- Similarly, the API limit consequently limits the size of the graph we can generate within a 15-minute window. Sending a very popular article would require a rather long time to construct the propagation graph (as the API would take 15 minutes for every 300 nodes).
API
We provide a user-friendly API endpoint that allows users to easily detect fake news in the financial sector.
The API is easy to use, all you need to do is to insert the URL of the news article and the API will give you the result of the veracity of the news.
The API is available below, and it can be integrated into other platforms or applications. With this API, we hope to help combat the spread of fake news and misinformation in the financial sector and minimize the potential losses caused by misinformation.
http://redemption-paybackdelphi.pythonanywhere.com/predict/api
Built With
- beautiful-soup
- django
- networkx
- nltk
- numpy
- python
- pytorch
- pytorch-geometric
- scikit-learn
- scipy






Log in or sign up for Devpost to join the conversation.