-
-
1
-
2
-
3
Inspiration
Banks and regulators stress-test portfolios by replaying the 2008 crisis. Every institution runs the same generic scenarios regardless of what they actually hold. The next crisis won't look like 2008, and a scenario that's catastrophic for one balance sheet may be irrelevant for another.
We asked a simple question: what if AI could search for the crisis that would hurt YOUR specific portfolio the most?
What it does
BlackScenario inverts the stress-testing workflow. Instead of a human guessing a scenario and measuring the impact, the system uses an LLM as an adversarial search engine to discover dangerous scenarios automatically.
You upload a portfolio. The AI generates crisis narratives with structured macro shock vectors. A trained plausibility classifier filters out nonsense. Monte Carlo simulation computes losses through a 6-factor risk model with regime-mixed covariance. The worst scenarios get fed back to the AI to produce even more severe variants. You get a ranked list of tail risks with exact loss numbers, hedge recommendations, and a regulatory-compliant PDF report — all backed by a tamper-evident audit trail.
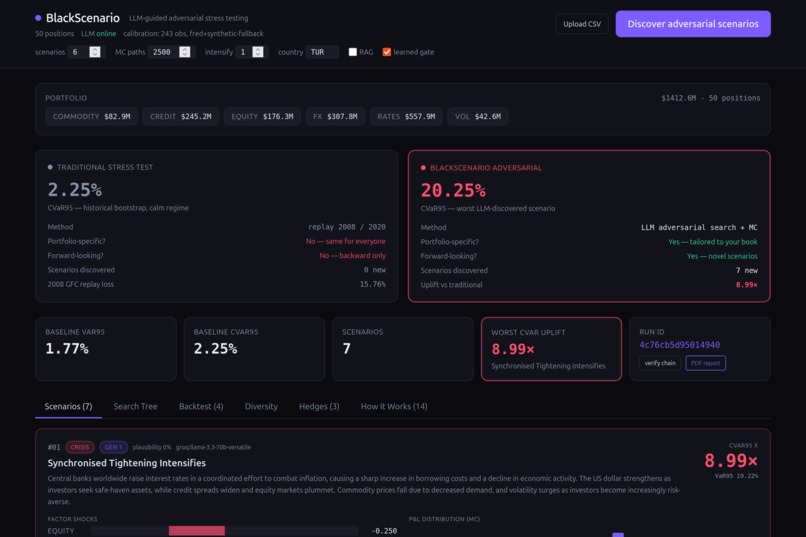
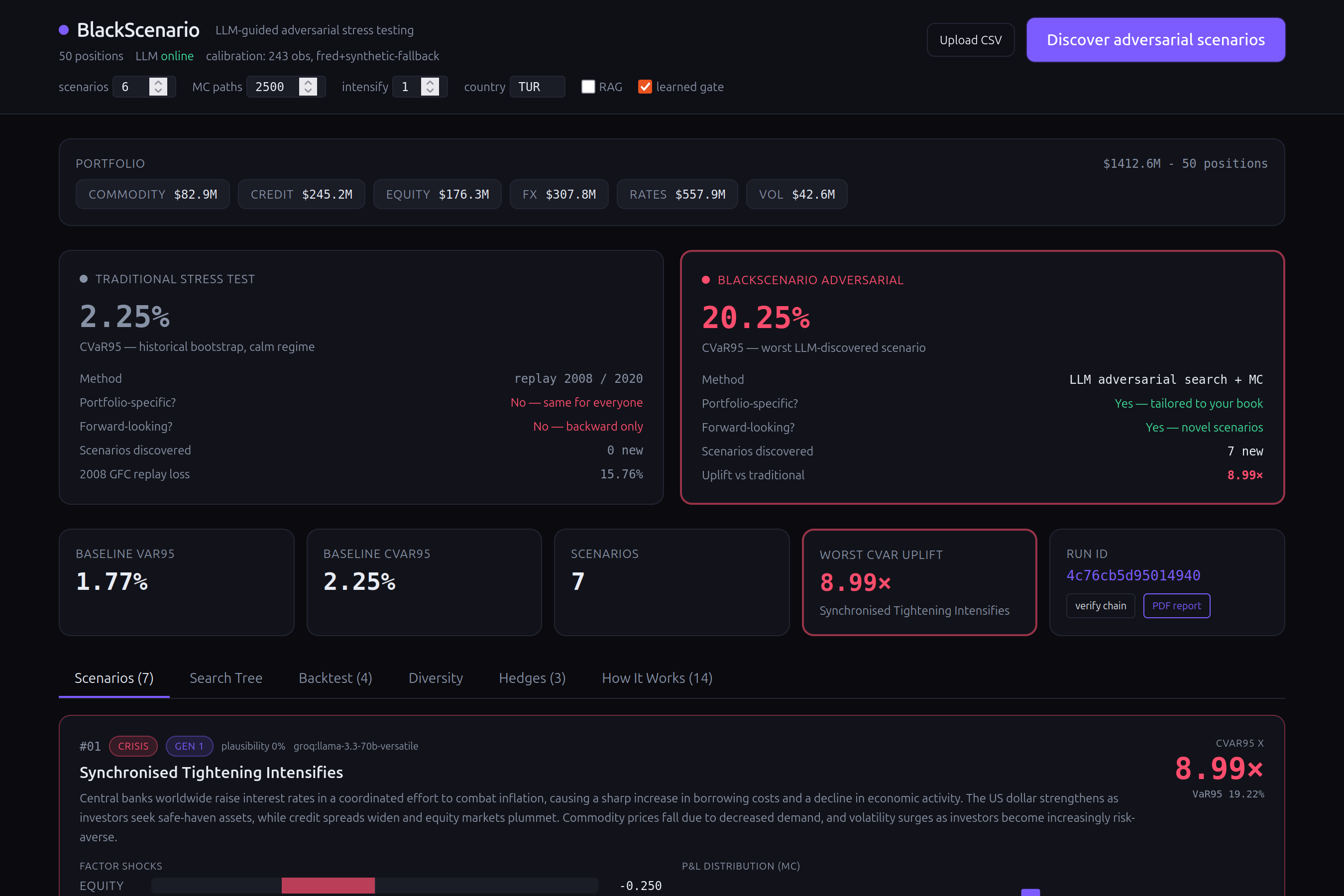
In our tests, BlackScenario found scenarios causing 9x more damage than what traditional stress tests predict for the same portfolio.
How we built it
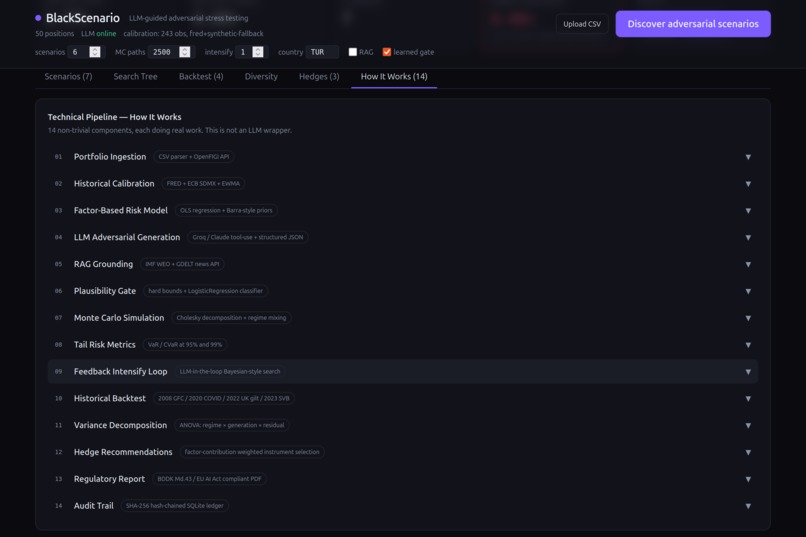
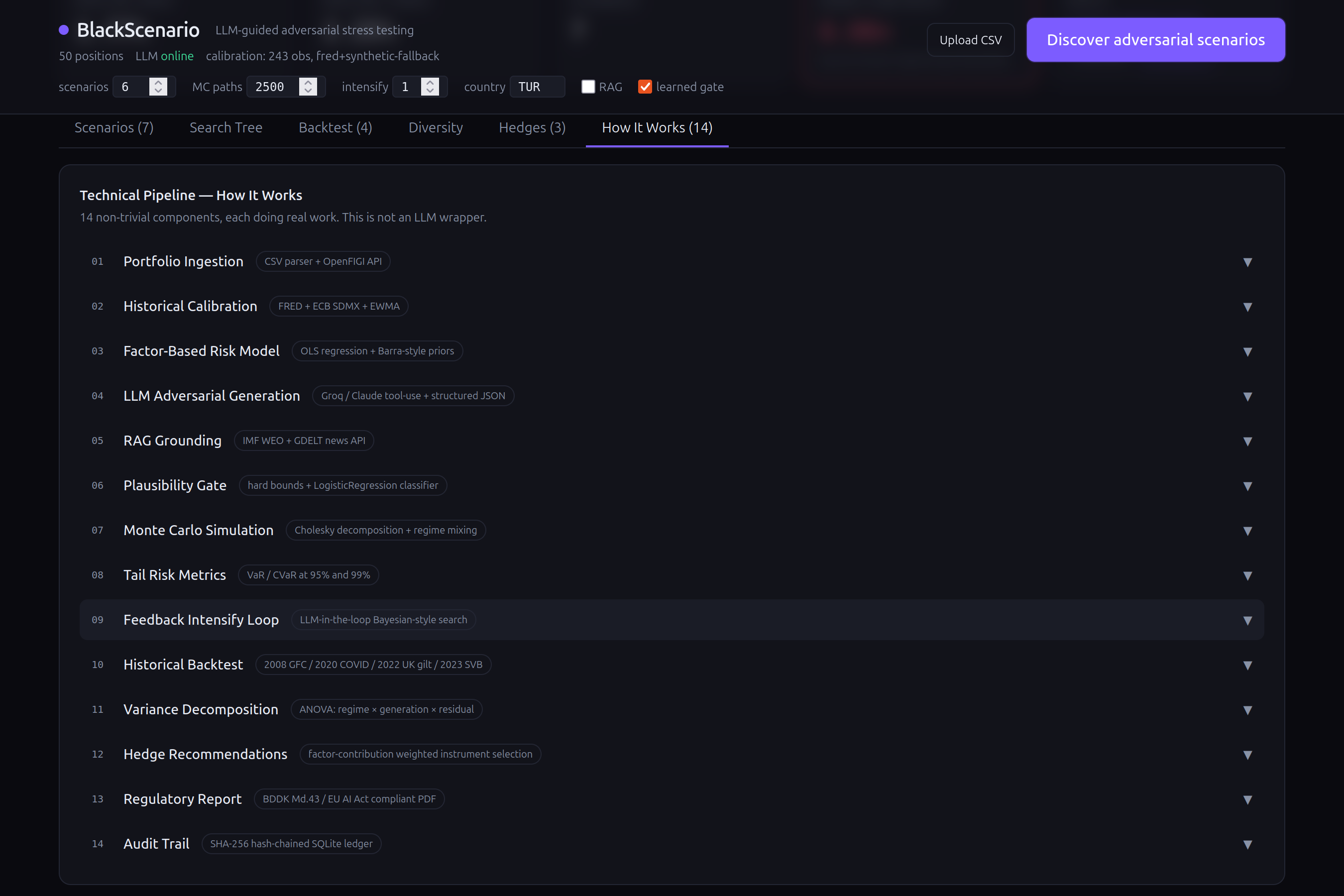
The system has 14 distinct technical components — this is not an LLM wrapper.
Risk engine: 6-factor model (equity, rates, credit, FX, commodity, volatility) calibrated from 243 months of real FRED data (NASDAQCOM, DGS10, VIX, WTI, HY spreads, USD index). Cholesky-decomposed Monte Carlo with calm/crisis regime mixing. Non-linear overlay for options (Black-Scholes) and bonds (duration + convexity).
AI layer: LLM scenario generation via Groq (Llama 3.3 70B) with structured JSON through tool-use function calling. RAG grounding using IMF WEO fundamentals and GDELT news headlines. A scikit-learn LogisticRegression trained on historical vs random shocks scores each scenario's plausibility.
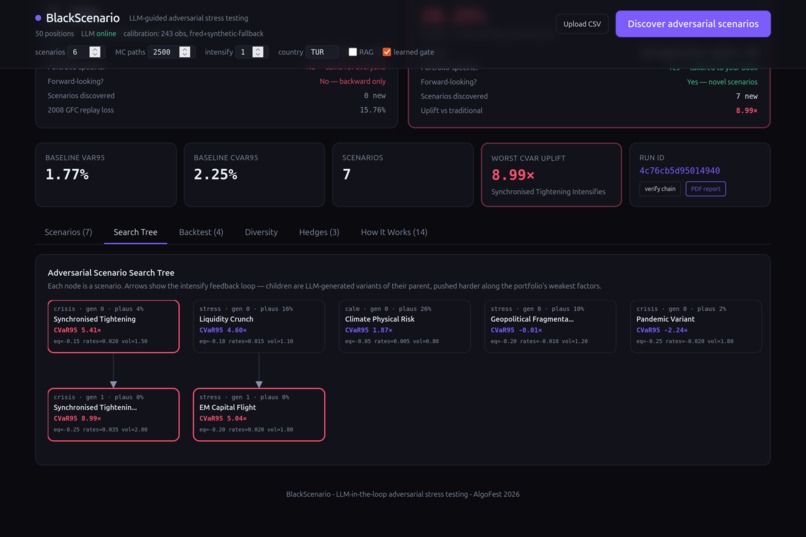
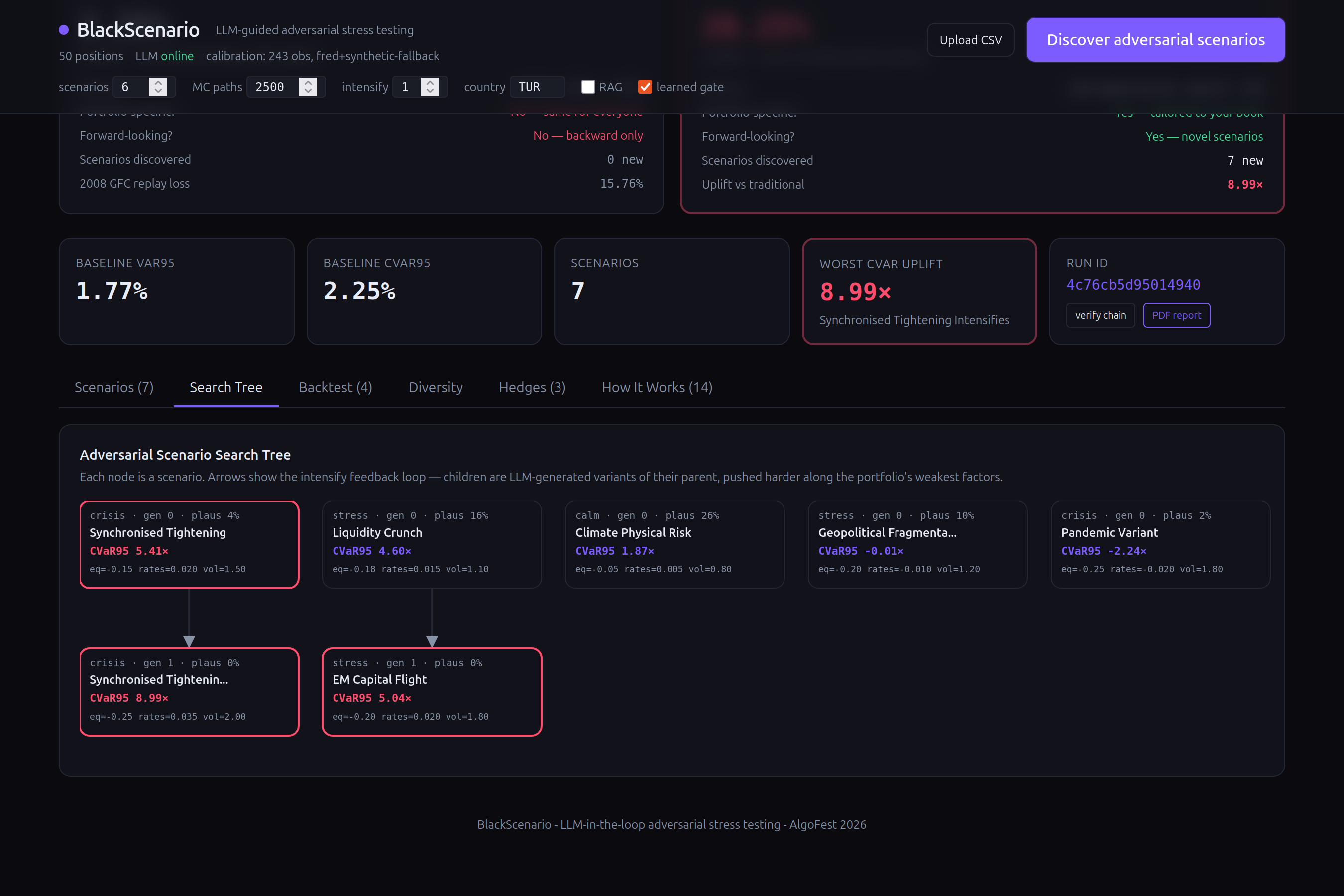
Feedback loop: The top-k worst scenarios are fed back to the LLM with an "intensify along the portfolio's weakest axes" prompt. This creates a search tree — visible in the UI — where each generation pushes harder on the factors that hurt the most. This is Bayesian-optimization-shaped search with the LLM as both prior and acquisition function.
Validation: Historical backtest replays 2008 Lehman (equity −32%, credit +781bp, VIX +190%), 2020 COVID (equity −35%, VIX +296%), 2022 UK gilt crisis, and 2023 SVB — all from real Federal Reserve data. ANOVA variance decomposition quantifies scenario diversity.
Compliance: SHA-256 hash-chained append-only audit ledger logs every LLM call, gate decision, and Monte Carlo seed. BDDK/Basel III aligned PDF report with written assumptions, methodology, and management actions. EU AI Act (Aug 2026) compliant traceability.
Frontend: Single-file React dashboard with scenario cards, P&L histograms, factor shock bars, an SVG search tree visualization, historical backtest table, variance decomposition charts, hedge recommendation table, and a 14-step technical pipeline accordion.
Challenges
LLM output consistency: The AI sometimes generated shocks that contradicted its own narrative — saying "dollar strengthens" but putting a negative FX value. We solved this by embedding explicit sign convention rules directly in the system prompt with examples for each factor.
Plausibility vs adversarial tension: The whole point is finding scenarios beyond history, but the gate needs to reject nonsense. We trained a classifier that scores plausibility without hard-blocking creative scenarios — the score is shown on each card so users can judge for themselves.
Real data calibration: The S&P 500 series in FRED only starts in 2016, which meant our 2008 backtest showed zero equity shock. We switched to NASDAQCOM (available from 1971) to capture the full crisis history.
Rate limits: Groq free tier is strict. We added exponential backoff with retry and tuned inter-call delays to stay within limits while keeping response times under 30 seconds.
What we learned
- LLMs are good at generating coherent macro-financial narratives when constrained with structured output schemas and explicit sign conventions
- The real value is not the LLM itself but the feedback loop — iteratively intensifying scenarios along the portfolio's weakest axes finds risks that random sampling never would
- A tamper-evident audit trail is not optional for financial AI — EU AI Act and BDDK regulations require full traceability
- Historical backtest validation is essential — without it, adversarial scenarios are just creative fiction
What's next
- Multi-LLM consensus scoring (Claude + Groq + local model)
- Real-time daily portfolio monitoring with automated reruns
- Full option revaluation with Greeks
- PostgreSQL for production multi-tenant deployment
- Streaming scenario generation via SSE

Log in or sign up for Devpost to join the conversation.