-
-
Landing page
-
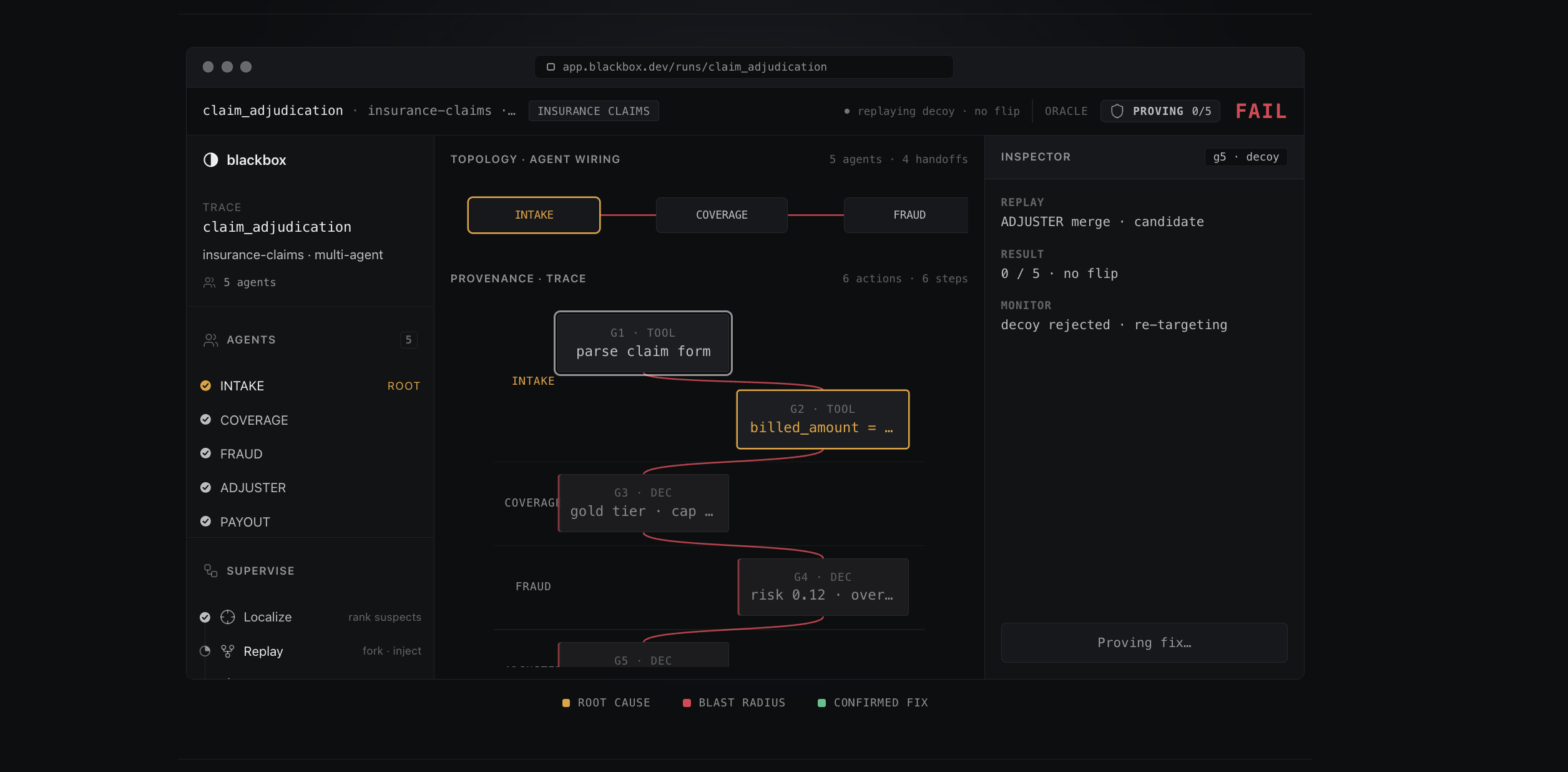
Agent failure
-
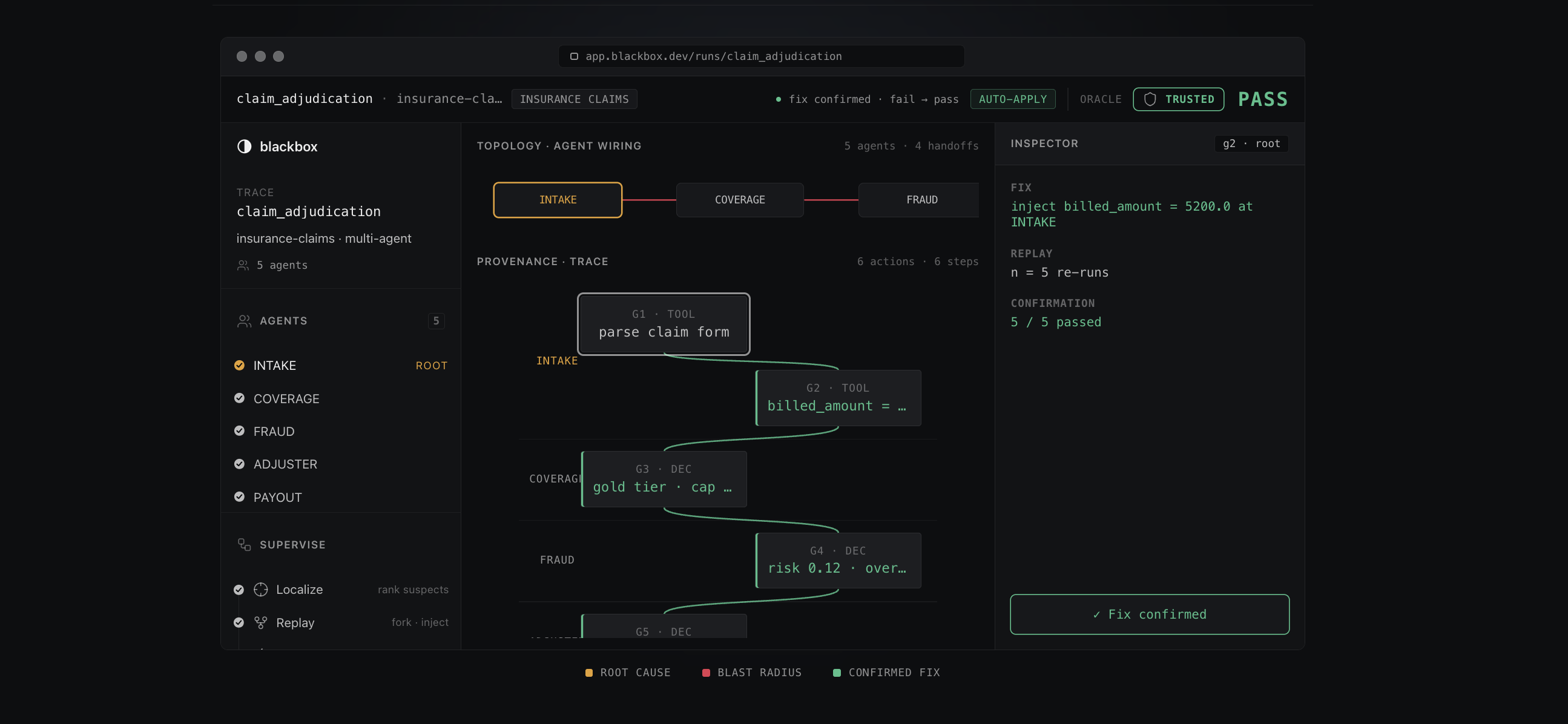
Agent passes
-
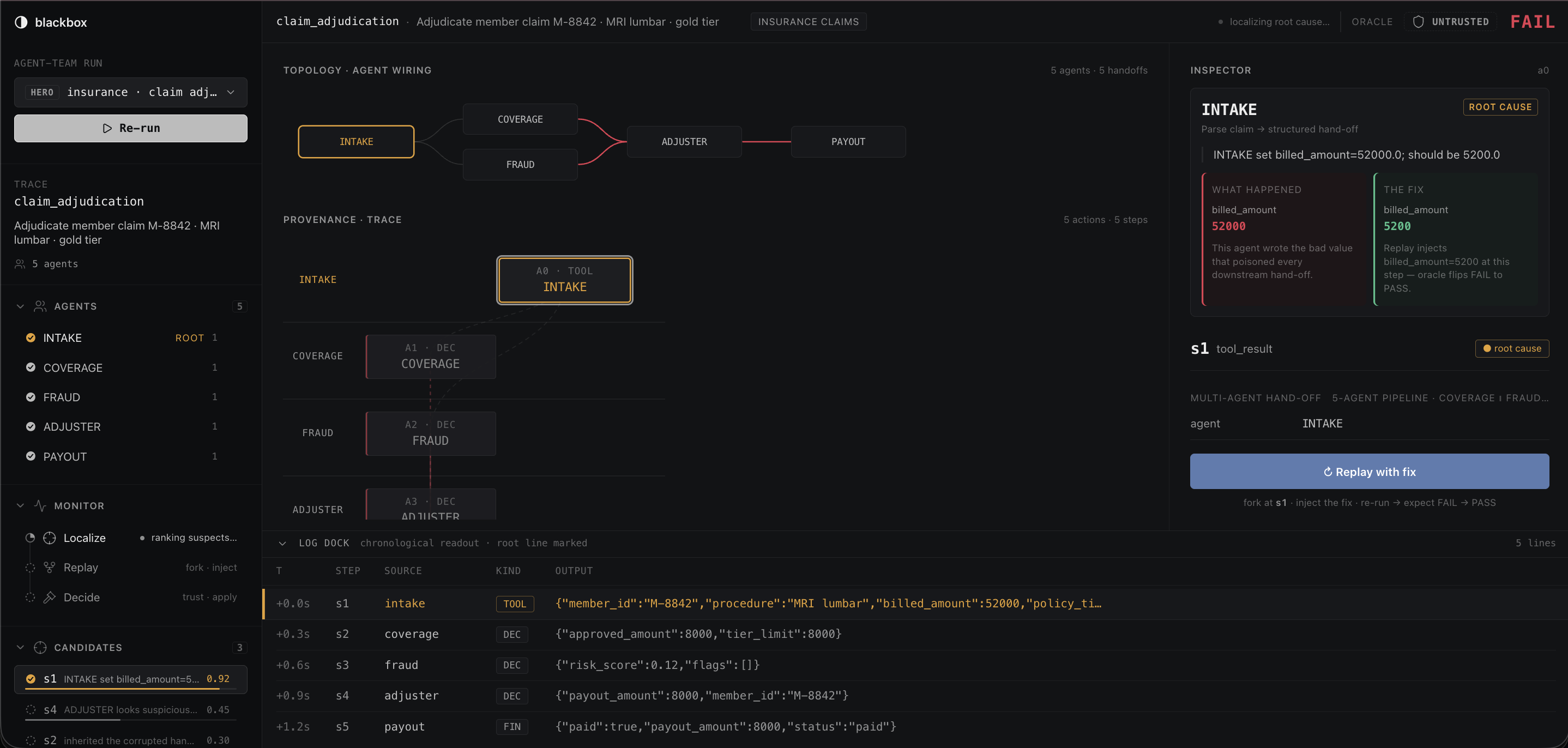
Dashboard to see the multi-agent performances
Blackbox
Inspiration
Enterprise work is quietly turning into teams of agents collaborating on one goal. One reads the invoice, one matches it to a purchase order, one approves it, one pays. They hand structured payloads to each other, and they trust whatever they receive.
These multi-agent systems can fail in the worst possible way: silently. If one agent misreads a spec or messes up a handoff, all the agents downstream will trust the result and faithfully pass this bad value along. Consequently, the final action, a payment or a booking, is confidently wrong and it can be difficult to trace exactly where the issue arose.
The way we know of for debugging these failures is simply scrolling through a wall of logs for the agents and guessing which one to blame. Every "supervisor agent" we looked at did the same thing, just automated, an LLM watching other LLMs and guessing a fix. Just guessing, not debugging.
The best published method for multi agent step level failure attribution scores around 14% accuracy. Simply asking an LLM which agent failed lands at under 10%. This is an open research problem, which we wanted to solve by providing solid proof.
What it does
Blackbox is a flight data recorder and causal debugger for multi-agent pipelines. When a run fails, it finds the step that caused it and proves that step is the cause by replaying the run, before it lets any fix get applied.
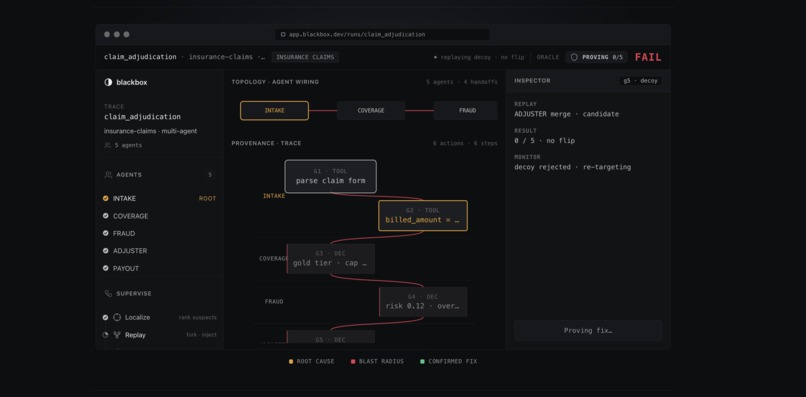
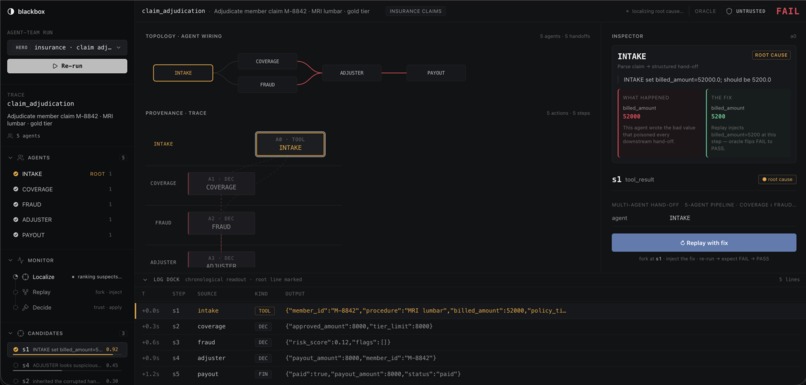
It starts by recording the failed run. Every reasoning step, tool call, and handoff payload becomes a graph, where the nodes are the agents and the edges are the handoffs between them. Blackbox then localizes the earliest wrong step by tracing the graph back to the first handoff whose output diverges from what it should have been.
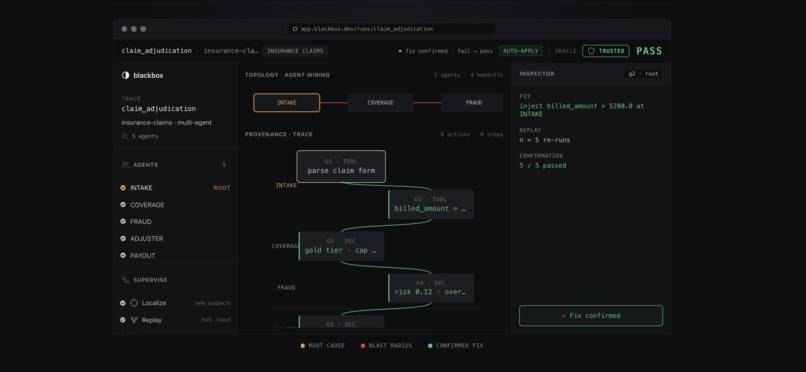
The part that makes Blackbox different is that it does not stop at a guess. It forks the run at the suspected step, injects a corrected value, and re-runs. If the outcome flips from FAIL to PASS, that step was the cause. If it replays a different suspect and nothing changes, that suspect is ruled out. Because fixing any earlier link also repairs the rest of the chain, the earliest step that flips is the root, and that falls out of the order of the replays rather than an LLM's opinion.
Only once a fix is confirmed by replay does Blackbox mark it auto_apply. If a fix is low confidence, it gets marked escalate, which brings a human in to inspect it. Nothing is silently auto-fixed without proof that the fix actually works.
The whole system rests on one idea: don't claim a root cause, prove it. The attribution comes from the graph and the replay, not from asking an LLM who failed. Every proposed repair, whether it is the agent's own fix or a human's suggestion, stays untrusted until a replay flips the outcome.
How we built it
Backend (Python and FastAPI): a provenance graph and a backward-slice localizer, a fork, inject, and replay engine, and a monitor that runs the trust gate.
Subjects: a deterministic multi-agent framework covering claims, prior-auth, procurement, and SOC, a real-Claude coding pipeline (spec, then implement and test, then review) running on Haiku so live runs stay fast and cheap, and a LangGraph flight agent that uses a real Browserbase web tool.
Frontend (Vite, React 19, TypeScript): a forensic instrument dashboard with a dark, high-contrast, IDE debugger look, never generic SaaS. It shows the trace as a vertical spine tagged by agent, an agent gutter on the left, a pinned monitor rail, and the moment everything builds to, a trust badge that flips from untrusted to trusted at the same time the verdict flips from FAIL to PASS.
Observability: OpenTelemetry + OpenInference spans exported to Arize AX. Evaluators judge end-to-end outcomes (claim in → payout out); span trees debug multi-agent hand-offs. Blackbox localizes and replay-proves fixes, eval does not replace attribution.
Challenges we ran into
Live LLMs self-correct. When we injected a fault into a spec, the implementer downstream would often quietly fix it on its own, so the bug never actually surfaced. That is what pushed us toward natural failures, where we let the model genuinely make the mistake, and toward keeping deterministic replay as the source of truth.
A fix that an LLM says works is not proof. So we kept the two things separate. The model is allowed to propose a repair, but a deterministic oracle is what decides whether the repair actually flips the outcome.
Parallel agents broke our reproducibility. The matcher and the fraud check finish in whatever order asyncio happens to schedule them, which would make a live run disagree with the saved fixture. We fixed it by assigning step IDs after the agents join back up, sorted by node name instead of by who finished first, so the trace comes out the same every time.
Accomplishments that we're proud of
We built a supervisor that proves instead of guesses. On a problem where the best published step attribution method sits around 14%, our localization gets 30 out of 30 on the labeled flight benchmark, and the monitor finds the right fault site on every injected fault in our convergence suite.
We were strict about not cheating. When a partial fix flips and a decoy does not, that is a real causal result and not a hardcoded branch. The corrected value always comes from re-deriving it or from a human, never from reading the answer key. The decoy rejection and the root confirmation both run live. And we are upfront about which numbers are measured and which parts are an existence proof.
It also reads at a glance. The dashboard turns a fairly abstract research idea, step level causal attribution, into a single moment you can actually see: the badge going from untrusted to trusted exactly as FAIL turns to PASS. The thing people remember is the proof.
What we learned
The hardest decision was not a coding one, it was deciding that an LLM should never be the source of truth. Once we made the model optional, used only to rank which suspect to test first while the replay decides the actual root, the whole approach became something we could defend.
We also learned to treat a rejected suspect as a real outcome rather than an error. A candidate that does not flip is exactly what proves causation, so we built both the logic and the UI to treat rejection as a normal, expected result, shown in a neutral state and never in an alarm color.
Working with tight constraints actually helped us move faster. A small fixed set of design tokens, one shared data contract, and only ever adding to the schema meant four people could build in parallel without stepping on each other.
What's next for Blackbox
Measure the multi-agent path. The flight benchmark gives us a real number, and the next step is a labeled multi-agent benchmark so the Accounts Payable accuracy is something we measure instead of assert.
Ingest more than LangGraph. Right now replay rides on LangGraph checkpoints. We want a standard OpenTelemetry span ingestion path, plus an Agent Client Protocol proxy that records and injects right on the wire, so we can capture runs across other frameworks with no instrumentation.
Close the loop in production. Turn a replay-proven fix into a committed guard rule that carries the structured handoff payload, and grow the supervisor from a single corrupted handoff toward failures with more than one cause.
Built With
- anthropic
- arize-ax
- browserbase
- claude-code
- fastapi
- langchain-core
- langgraph
- motion
- openinference
- opentelemetry
- pydantic
- pytest
- python
- react
- tailwind-css
- testing-library
- typescript
- uvicorn
- vite
- vitest



Log in or sign up for Devpost to join the conversation.