-

The extension window
Inspiration
This project was made for the WHACK 2025 by a team Mykhailo Kopytskyi, Lidiia Tonieva and Milli Gebremariam.
While billions of users surf the net every day, there is process going on behind the scenes of the web pages - data collection. Internet browser providers, such as Google can collect user data without their explicit consent. This data normally includes mouse movements, time the user spent on the page and other interactions with the content. You might ask - what bad could they do by collecting such information? Well, when there are a huge array of user data, you can find patterns in it. These patterns are then combined into a behavioural model of the user, which then companies can sell to advertisers and just anyone who is willing to pay for it. What makes it even worse, there could be an identity theft using this information which can then lead to even worse consequences.
Our goal is to make members of general public more aware about this problem, by showcasing what data can be collected about them by just surfing the web and teach them how to protect your identity online.
What it does
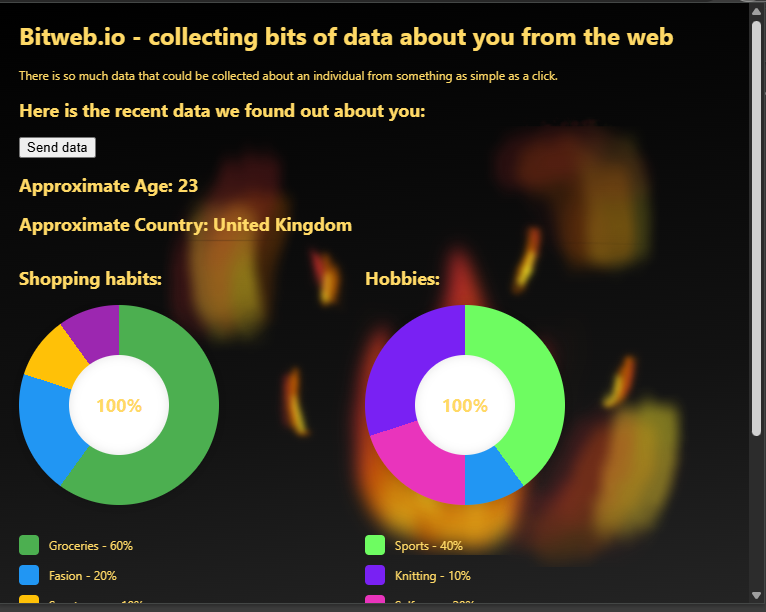
BitWeb.io is a Web Browser Extension that can collect user data and process it in order to build a behavioural model. This behavioural model stays within the local storage of the user's browser and does not go anywhere on the net, making it way safer to use. Our model uses easy to understand infographics to showcase what information can be collected about them. This includes approximate age, location, purchasing habits and even something like hobbies.
How we built it
For the client side, we decided to implement a browser extension that will silently scrap the websites in the background and send them to the server for processing.
For the NLP side, we used the all-MiniLM-L6-v2. We picked this BERT model because it was lightweight and fast. The program compares different keywords, using cosine similarity to categorise html pages into different categories (such as 'hobby-related').
Challenges we ran into
Accomplishments that we're proud of
We are proud of being able to implement such a big app in a short period of time, which can potentially raise awareness amongst people towards the issue of data gathering.
Difficulty of using browser API as it uses a main process and several helper processes which have to communicate between each other using special API. The speed of computation on the server is another issue, as the NLP takes some time to process the data, but the results are worth it.
What we learned
We have acquired a lot of skills - both technical and soft ones. We were able to successfully communicate with each other in order to produce a huge piece of work. We also acquired a lot of practical skills, which will definitely help us in both out academic and professional career.
What's next for BitWeb.io
We want to make our app into something that will help users to stay safer online. In the next updates, we will add more parameters that could be tracked, so that the model becomes closer to the one big companies have. This would help users to grasp the whole scale of the problem and would motivate them to stay safe even more. In the future, we are also planning of adding an introductory information about Incognito mode and other methods to reduce the impact of data gathering.

Log in or sign up for Devpost to join the conversation.