-
-
Onboarding
-
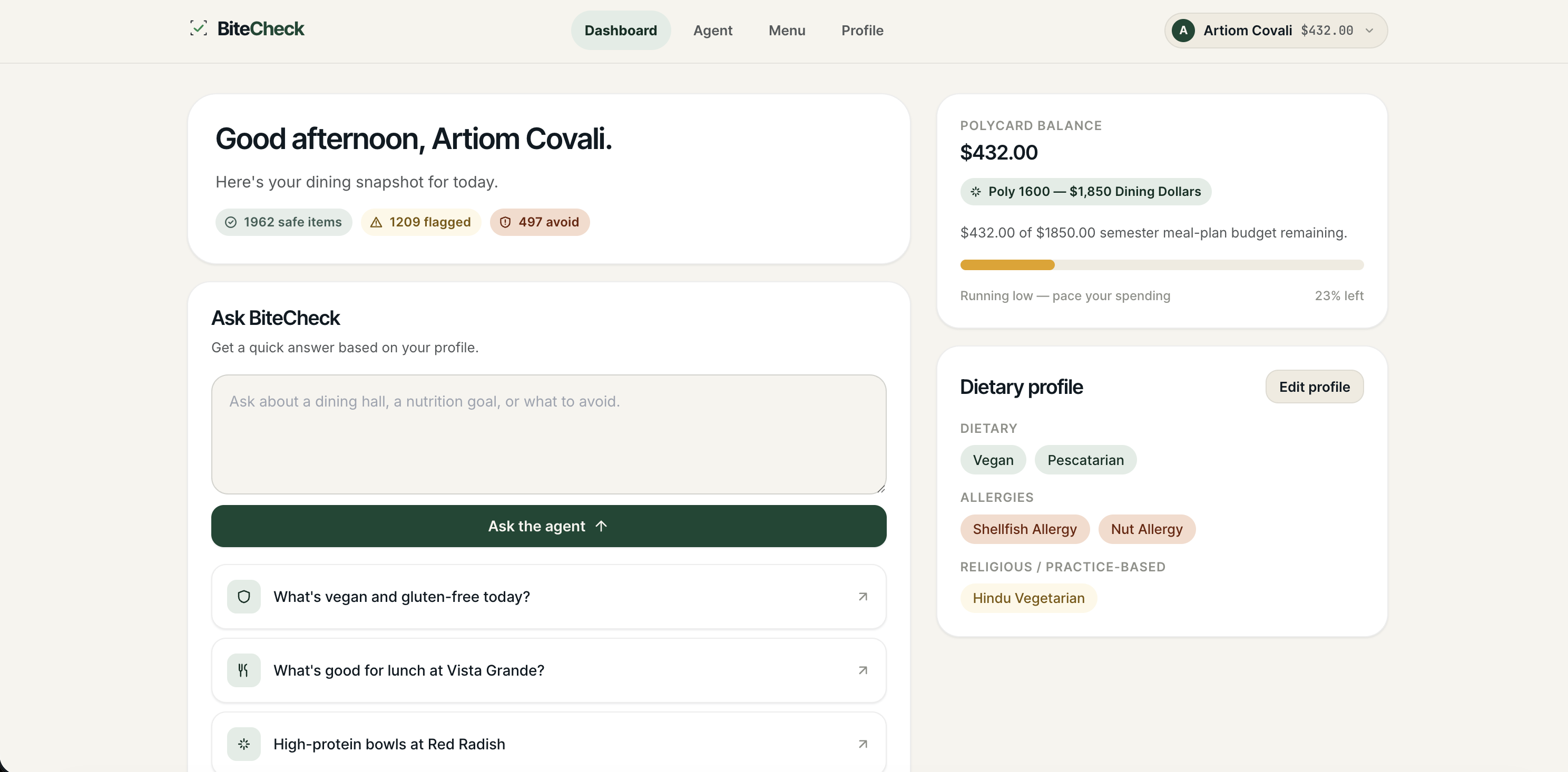
Dashboard
-
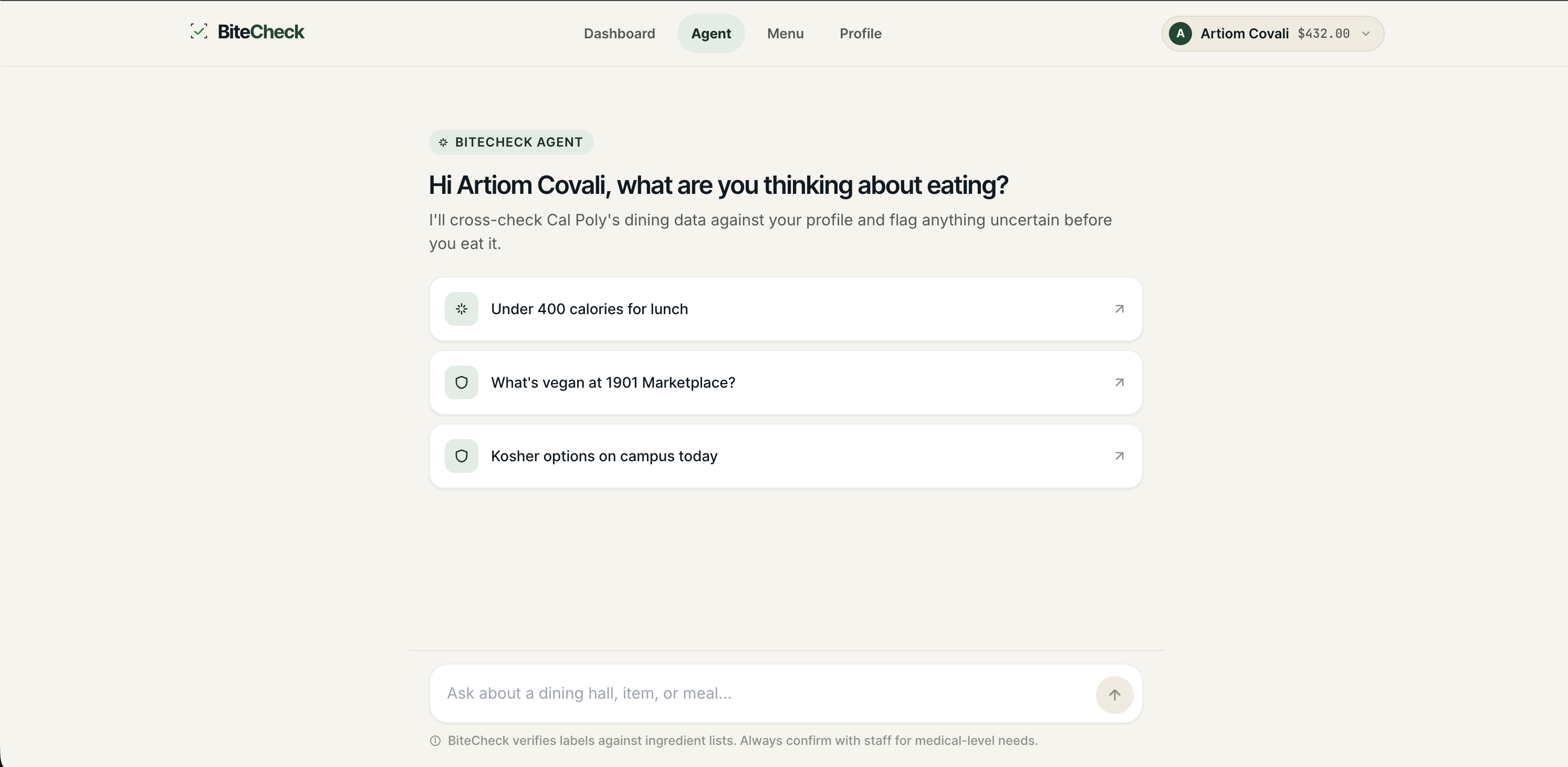
Agent
-
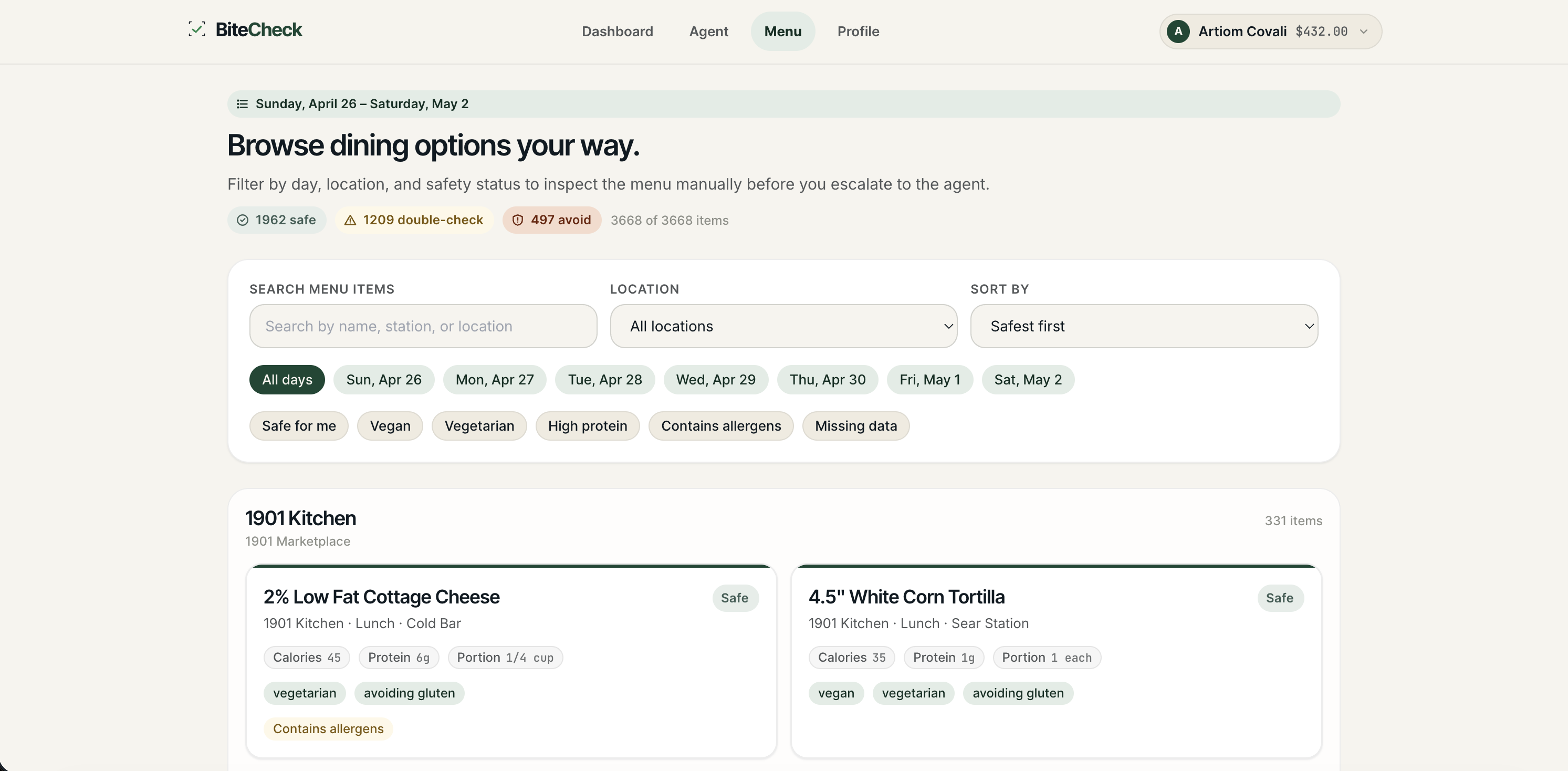
Menu
BiteCheck — Know Before You Bite
Inspiration
We're Cal Poly students. We eat on campus every day. And we've watched friends with allergies, religious dietary rules, and health goals struggle with the same problem: the dining app says "Vegan" on a label, but the ingredients list tells a different story.
It started when we noticed posts on r/CalPoly from students asking basic questions that should have easy answers — where to find nutrition facts for campus food, and which dining halls actually have healthy options. Students were crowdsourcing dietary information on Reddit because no existing tool gave them what they needed.
Then we dug into the actual data. Cal Poly's dining dataset has 3,668 menu items with nutrition facts, ingredients, and dietary labels — but the allergens column is completely empty across every single row. The dietary_labels field mixes categories, allergens, and cross-contamination warnings into one messy string. Items labeled "Vegan" sometimes list "Milk" in the same field. Asterisk-suffixed entries like Beef* indicate cross-contamination risk, but nothing explains what the asterisk means.
For a student with celiac disease, a severe nut allergy, or a Hindu vegetarian commitment, trusting these labels without cross-checking is a real safety risk. We built BiteCheck because that gap between what the data says and what students need to know shouldn't exist.
What it does
BiteCheck is a safety-first dining assistant for Cal Poly students. It does three things:
1. Audits every menu item against your profile. A deterministic discrepancy detector cross-checks dietary labels against ingredient lists, flags cross-contamination risks based on your severity level (medical, strict, or preference), and catches conflicts the dining system misses — like an item labeled "Vegan" that lists "Egg" in the same field. Every item gets a status: safe, flagged, or unsafe.
2. Answers natural-language questions with source-cited recommendations. Ask "What's safe at Vista Grande for dinner?" or "Find high-protein vegan options" and the AI agent runs a 5-step pipeline: parse your intent, retrieve candidates, audit each one against your profile, rank the safe ones, and stream back recommendations with confidence scores. Every recommendation cites at least two data fields so you can verify the reasoning yourself.
3. Lets you browse the full week's menu with filters. Date, location, safety status, dietary tags — filter 3,600+ items across 10+ restaurants to find exactly what fits your needs. Double-check items show in yellow with plain-English explanations like "Possible cross-contamination with egg" instead of cryptic technical labels.
Religious dietary restrictions (halal, kosher, Hindu vegetarian, Jain vegetarian) are treated with the same rigor as medical allergies throughout the entire system — because for the students who hold them, they are equally non-negotiable.
How we built it
We built BiteCheck entirely in Kiro, using its spec-driven development, steering docs, agent hooks, custom MCP server, and Kiro Powers to structure the development process.
Spec-driven development defined the architecture before we wrote code. Three specs — the agent decision loop, the discrepancy detector, and the streaming UI — documented the 5-step pipeline, the five conflict categories, and the event streaming contract. This was essential for the safety-critical parts: the discrepancy detector needed precise, documented rules that Kiro could reference across multiple sessions, not ad-hoc vibe coding.
Four steering docs ran as persistent instructions across every interaction: safety-first reasoning (the LLM never overrides the deterministic detector), dual-source citation (every recommendation cites two fields), LLM provider constraints (OpenAI structured outputs only), and domain vocabulary (canonical restriction taxonomy, forbidden phrasings). The safety steering doc was the single most impactful — it prevented Kiro from generating code that would silently filter out flagged items or use authoritative phrasing the data doesn't support.
Agent hooks automated quality checks. One hook validates that no flagged or unsafe item ever appears in recommendations after any change to agent code. Another regenerates TypeScript types when the database schema changes, catching field name drift before the agent cites a column that no longer exists.
A custom MCP server gave Kiro direct access to the Cal Poly dining dataset during development. When implementing the discrepancy detector, Kiro could query "show me items labeled Vegan that contain dairy in ingredients" and get real rows back instantly — no manual data export needed. This was the highest-leverage integration: it meant every detection rule was tested against real conflicting data as it was written.
Kiro Powers — the Supabase power provided contextual awareness of Postgres schemas, auth flows, and RLS policies, which was especially valuable for the SSR cookie-based auth setup with Next.js App Router. The Figma power bridged the design-to-code gap, letting Kiro pull exact design tokens, spacing, and typography values from the source file when building the component library.
The tech stack: Next.js 15 (App Router), TypeScript, Supabase (PostgreSQL + Auth + RLS), OpenAI GPT-4o with structured outputs, Tailwind CSS, Zod for shared validation schemas, and Vercel for deployment.
Challenges we ran into
The data is messy. Cal Poly's dining dataset wasn't designed for programmatic safety checking. The dietary_labels field is a semicolon-delimited grab bag of categories, allergens, ingredient flags, and cross-contamination warnings. The allergens column is empty. Asterisks mean "may contain" but that's nowhere documented. We had to reverse-engineer the semantics from 3,668 rows of real data before we could write a single detection rule.
Scraping campus dining data past Cloudflare. Cal Poly's Dine On Campus site is protected by Cloudflare's anti-bot system. Our initial approach — scraping the menu pages directly — was blocked immediately. Every request got a Cloudflare challenge page instead of actual data. We spent hours trying different scraping strategies before discovering that the site's underlying API endpoints weren't behind the same bot protection. We reverse-engineered the API calls the frontend makes, built a Python scraper (scrape_calpoly_dining.py) that hits those endpoints directly, and automated it with a GitHub Actions workflow that refreshes the data weekly. What looked like a dead end turned into a cleaner, more reliable data pipeline than scraping HTML would have been.
Supabase's 1,000-row default limit. When we switched from fetching today's menu to the full week (~3,600 items), the query silently returned only the first 1,000 rows. We initially tried bumping the page size to 5,000, but Supabase's server-side max is 1,000 regardless of what you request. The fix was parallel pagination: count query first, then fire all page requests concurrently with Promise.all.
Hydration mismatches from random suggestions. The rotating suggestion bank used Math.random() during initial render, producing different results on server vs client. React's hydration check caught the mismatch. We fixed it by rendering a deterministic fallback during SSR and swapping to random picks in useEffect.
Balancing safety with usefulness. The discrepancy detector is intentionally aggressive — missing data is unsafe, single-source recommendations get low confidence, cross-contamination flags are never hidden. But being too aggressive means showing nothing useful. We spent significant time tuning the severity system so medical users get maximum caution while preference users still see helpful results.
Prompt injection on a safety-critical app. If someone can trick the agent into recommending an unsafe item, that's not just a security bug — it's a potential health risk. We built three layers of defense: pre-LLM input sanitization (15+ injection patterns), topic relevance checking (~120 keywords), and anti-injection paragraphs in all four system prompts. Plus a post-hoc enforcement layer that deterministically blocks any recommendation the audit flagged, regardless of what the LLM outputs.
Accomplishments that we're proud of
The deterministic detector never trusts the LLM. The discrepancy detector runs before the LLM sees any data, and the LLM cannot override its verdicts. Even if the LLM hallucinates a recommendation for an unsafe item, the post-hoc enforcement layer catches it. This architecture means the safety boundary is deterministic and testable, not probabilistic.
Dual-source citations on every recommendation. When BiteCheck says an item fits your profile, it tells you exactly which data fields it checked and what they said. "The dietary_labels field marks this vegan, and the ingredients list confirms no animal products." Single-source recommendations are downgraded to low confidence. This makes the system auditable and trustworthy even when the underlying data isn't.
Religious restrictions treated as first-class constraints. A Hindu vegetarian student's dietary rules aren't a "preference" — they're non-negotiable. BiteCheck's code, prompts, and UI copy all enforce this. The severity system, the steering docs, and the domain vocabulary all treat religious dietary commitments with the same rigor as medical allergies.
Plain-English warnings. Instead of "dietary_labels marks Egg* — shared prep or possible cross-contact with something you avoid," users see "Possible cross-contamination with egg. This item may be prepared on shared equipment." Every warning was rewritten to be something a hungry student can read in 2 seconds and act on.
Real data, real problems. Every detection rule was developed against actual conflicting rows from the Cal Poly dataset, surfaced via the custom MCP server. The test fixtures come from real menu items that exhibit each conflict type. This isn't a demo built on synthetic data — it's built on the actual messy reality of campus dining.
What we learned
Steering docs are more powerful than we expected. The safety-first reasoning steering doc silently shaped every code generation decision across dozens of conversations. We didn't have to re-explain the safety rules each time — Kiro just followed them. The strategy of using steering for constraints and specs for architecture was the key insight.
Structured outputs change the LLM integration game. Using OpenAI's structured outputs with Zod schemas means the LLM literally cannot return malformed data. No parsing errors, no "the JSON was almost right but had a trailing comma." This let us focus on the reasoning quality instead of fighting output format issues.
The data layer is the hard part. We spent more time understanding and working around Cal Poly's data quality issues than on any other part of the project. The discrepancy detector's five conflict categories all came from real data analysis, not theoretical concerns. Messy real-world data is where safety-critical apps live or die.
Spec-driven development pays off for safety-critical code. Vibe coding is great for UI iteration, but the discrepancy detector and agent pipeline needed precise, documented rules. Writing the specs first meant Kiro had full context about why each rule exists, not just what to implement. The specs became the source of truth that the validation hook tests against.
What's next for BiteCheck
Meal period filtering — The data has Breakfast, Lunch, Dinner, and Everyday meal periods, but the menu browser doesn't filter by them yet. Students want to see "what's for dinner tonight," not scroll through breakfast items.
Favorites and saved items — Star items you liked so you can quickly check if they're available today. Simple Supabase table, big daily engagement win.
Push notifications — "Your favorite Spiced Tofu Scramble is on the menu today" or "Cross-contamination alert at Vista Grande for items you usually eat." This is the killer feature for daily retention.
Chat history persistence — Save conversations to Supabase so students can reference past recommendations across sessions.
Multi-campus expansion — The architecture is campus-agnostic. The dining data format, the discrepancy detector, and the agent pipeline could work for any university that publishes menu data. Cal Poly SLO is the first campus, but the system is designed to scale.
Nutrition tracking — "I ate this today" button on items, running daily totals against macro goals. Combined with the meal plan budget tracking already in place, this would give students a complete picture of their dining life.
Mobile app — The current web app works on mobile browsers, but a native app with offline caching and push notifications would be the ideal form factor for students checking the menu between classes.
Built With
- github
- kiro
- next.js-15
- node.js
- openai-gpt-4o
- postgresql
- python
- react-19
- supabase
- tailwind-css
- typescript
- vercel
- zod

Log in or sign up for Devpost to join the conversation.