-
-
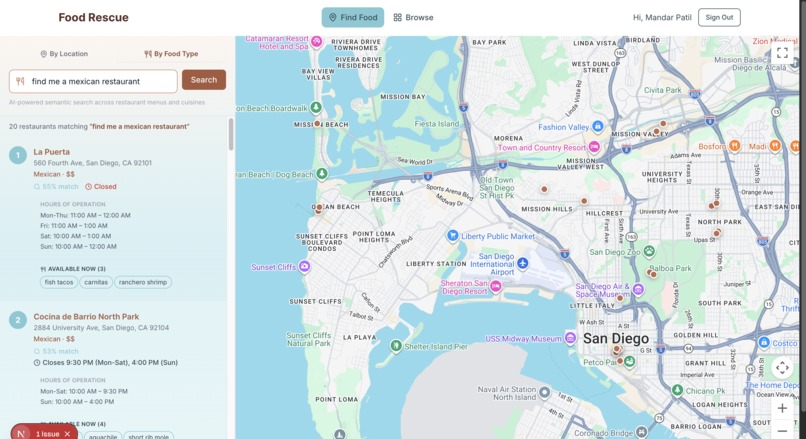
Semantic searching for restaurants
-
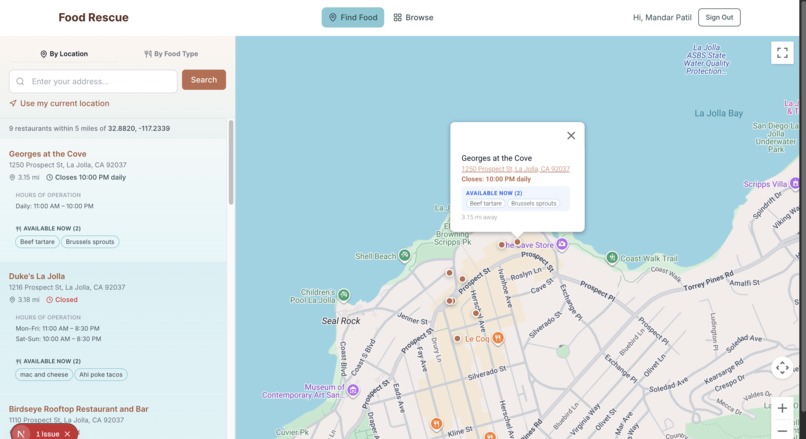
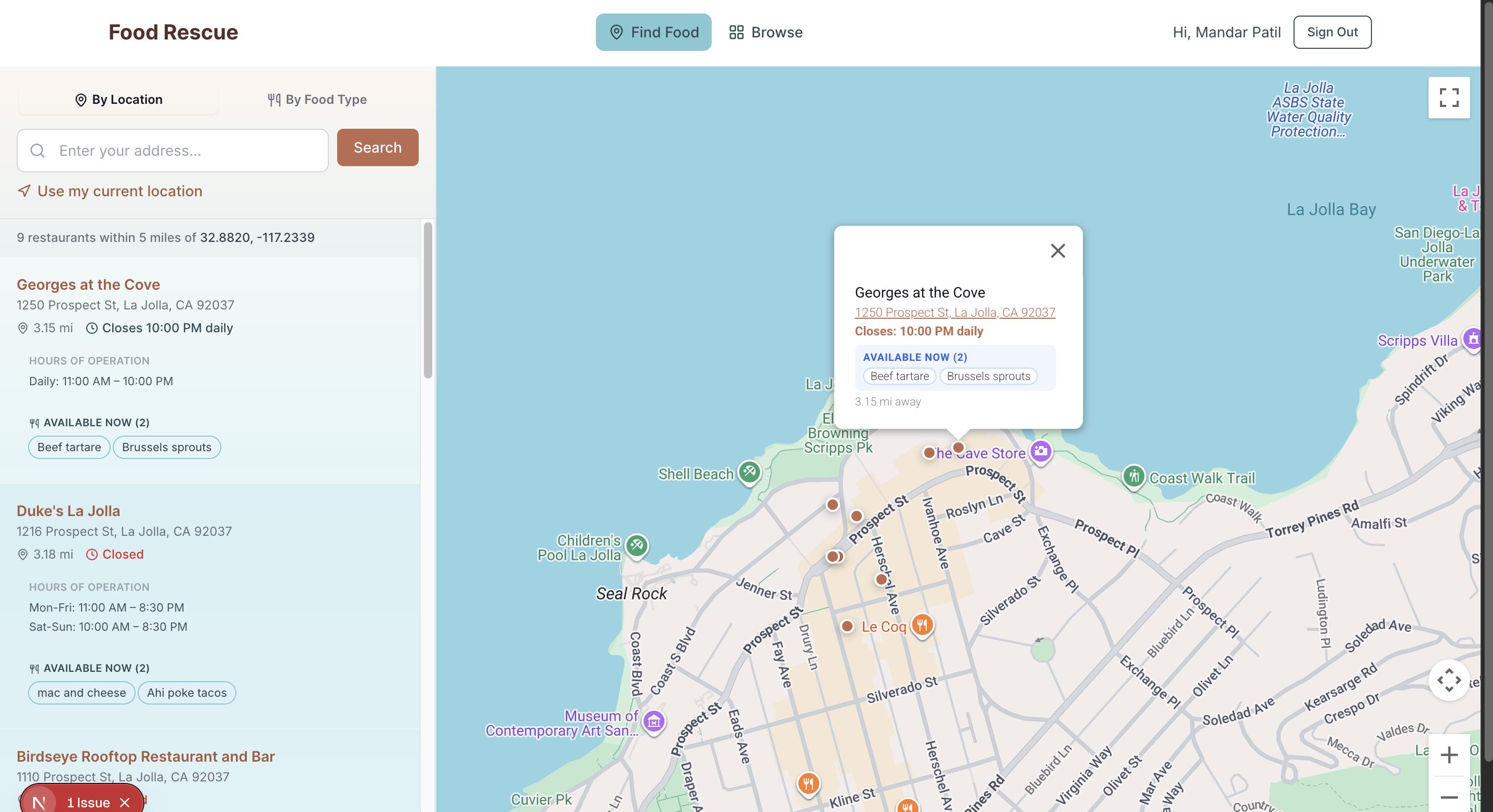
map view of all the restaurants
-
home page
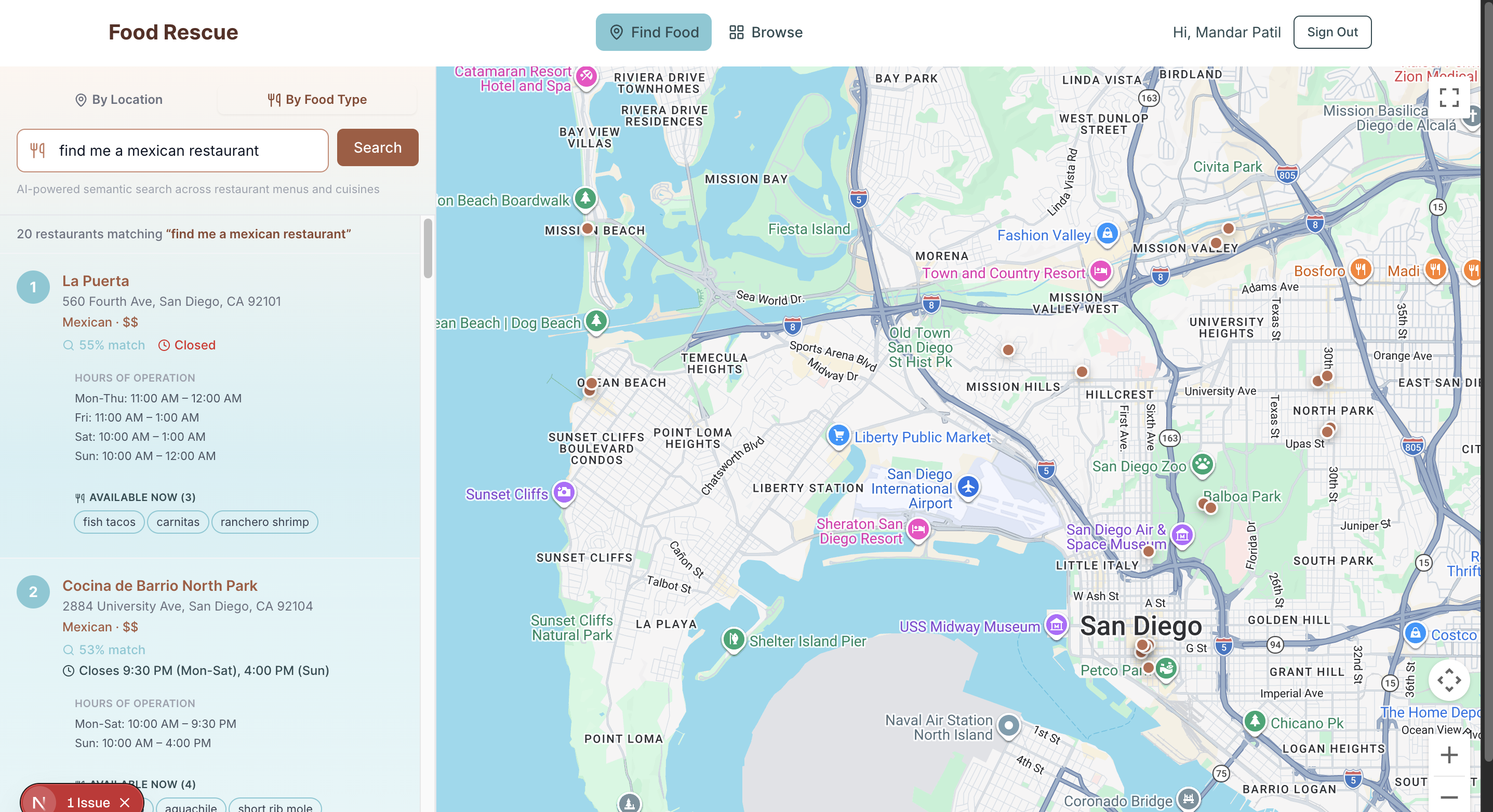
Inspiration
San Diego has thousands of restaurants spread across dozens of unique neighborhoods — from the seafood spots along the harbor to the hidden bistros in North Park and the rooftop bars of La Jolla. We wanted to build a smarter way to discover, search, and query local restaurants using modern AI infrastructure. The idea was simple: take real restaurant data and make it instantly searchable through both relational queries and semantic vector search.
What it does
FoodRescue is an AI-powered restaurant discovery platform for San Diego. It lets users search for restaurants using natural language — things like "find me a healthy spot where i can pick up fruits and vegetables" or "find me available italian food" — and returns accurate, real-world results. It combines a structured relational database (Supabase) for filtering by neighborhood, rating, hours, and cuisine, with a vector database (Pinecone) for semantic search powered by embeddings of each restaurant's full profile.
How we built it
We started by aggregating real restaurant data across San Diego's major neighborhoods — Gaslamp, Little Italy, La Jolla, North Park, Ocean Beach, Hillcrest, Mission Valley, Mission Beach, and Balboa Park — collecting details like addresses, coordinates, hours, ratings, cuisine types, and menu items. We organized this data into an Excel file: one sheet formatted for direct import into Supabase as a relational table, and a second sheet optimized for Pinecone, with a text_for_embedding column containing natural language descriptions of each restaurant, plus metadata fields for filtering. We then embedded the restaurant descriptions using OpenAI's text-embedding-3-small model and upserted the vectors into Pinecone in batches.
Challenges we ran into
Data consistency — restaurant hours, closing times, and menu items vary wildly in format across sources, requiring careful normalization before the data was usable. Dual schema design — structuring the same dataset to work well in both a relational database and a vector store required thinking carefully about what belongs in metadata vs. what belongs in the embedding text. Neighborhood coverage — San Diego is geographically large and culturally diverse; deciding which neighborhoods and restaurants to prioritize, and ensuring fair coverage, was harder than expected. Embedding quality — crafting the text_for_embedding field so that semantic searches return meaningful, relevant results took iteration to get right.
Accomplishments that we're proud of
Built a clean, production-ready dataset of 64+ San Diego restaurants with rich, structured metadata spanning 9 neighborhoods. Designed a dual-database architecture that supports both precise SQL-style filtering (Supabase) and natural language search (Pinecone) from a single source of truth. Created an Excel export pipeline that generates both schemas simultaneously, making it easy to keep both databases in sync as the dataset grows.
What we learned
Vector databases and relational databases are complementary to each other. Pinecone excels at "find me something like this" while Supabase handles "show me everything rated above 4.5 in Hillcrest." The real power is combining both. Data quality matters more than data quantity. A well-structured record with accurate hours, coordinates, and menu items is far more valuable for both search and AI applications than a large dataset with incomplete fields. Embedding the right text is everything in a vector search system. Including cuisine, location, price level, and menu items in the embedding text dramatically improves semantic search relevance.
What's next for BiteBack
Expand coverage to more San Diego neighborhoods including Pacific Beach, Coronado, Kearny Mesa, and Chula Vista. Add real-time updates by integrating with Google Places or Yelp APIs to keep hours, ratings, and menu items current. Expand to other cities — the dual-schema pipeline could be replicated for Los Angeles, San Francisco, or any other metro area.

Log in or sign up for Devpost to join the conversation.