-
-
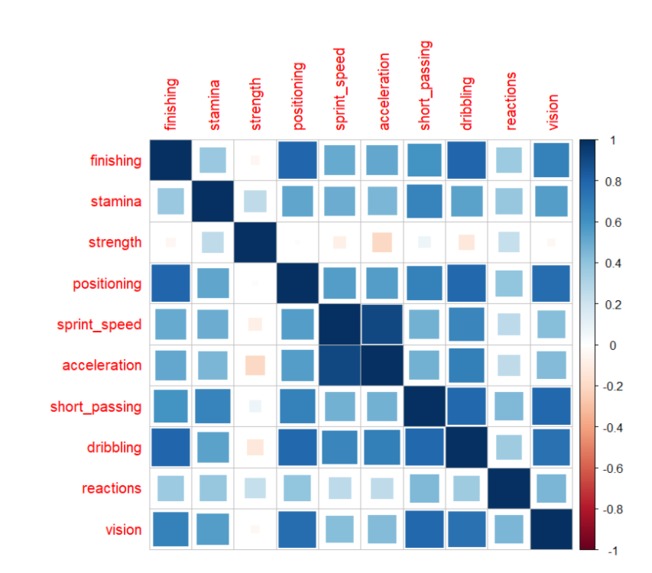
Correlation between our initial features
-
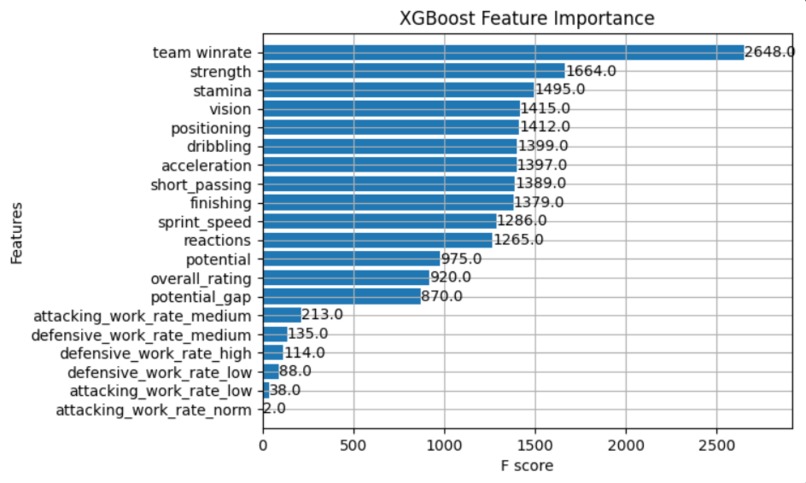
Variable Importance after training model
-
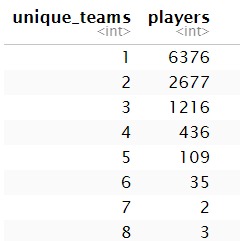
Number of teams players have played for
-
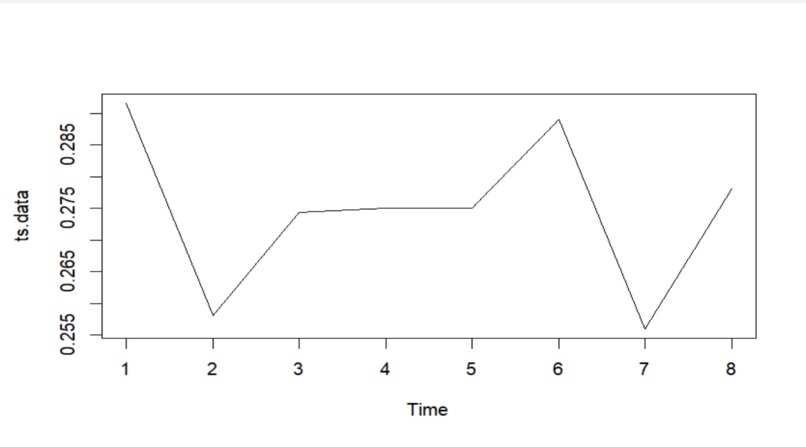
Trade Percentage over Seasons
-
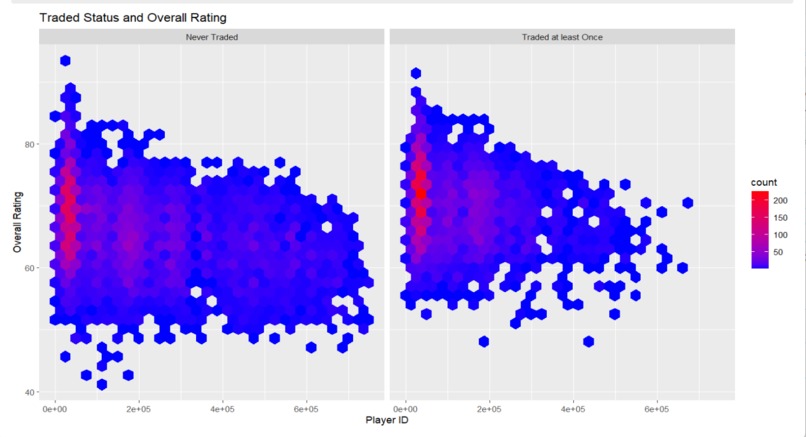
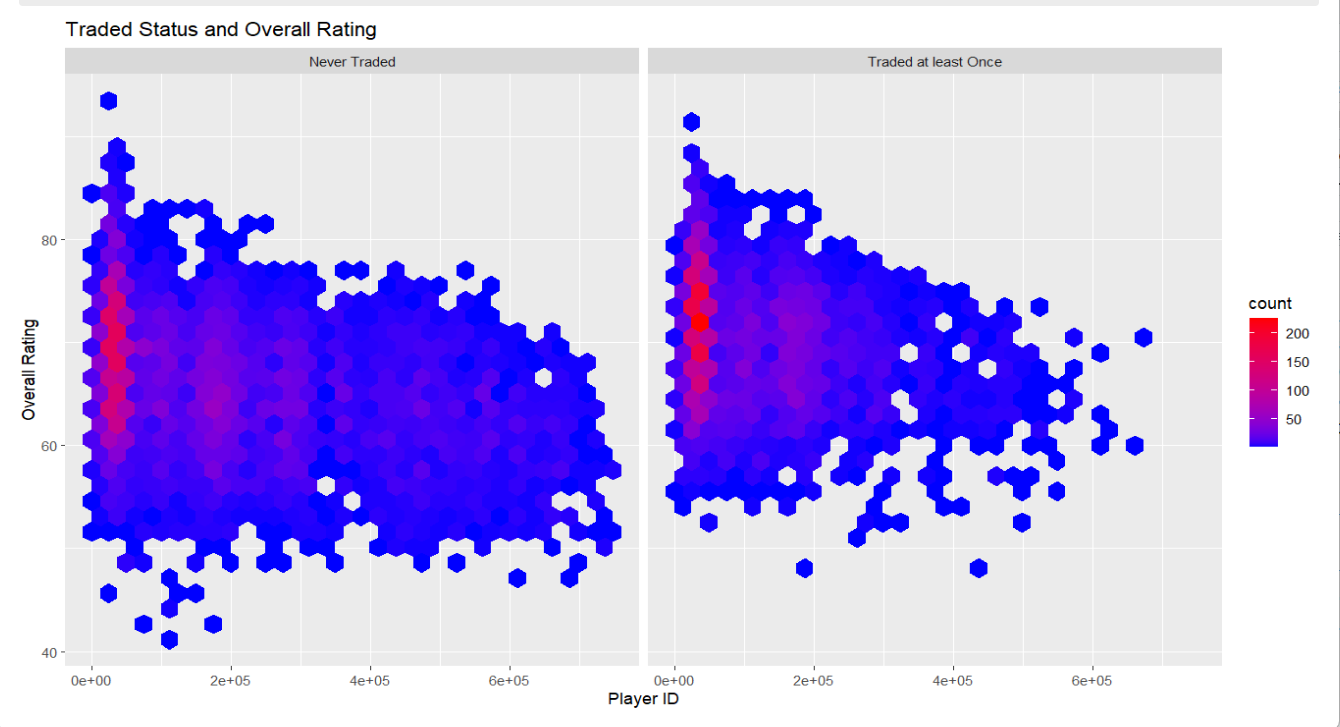
Trade Status and Overall Rating
-
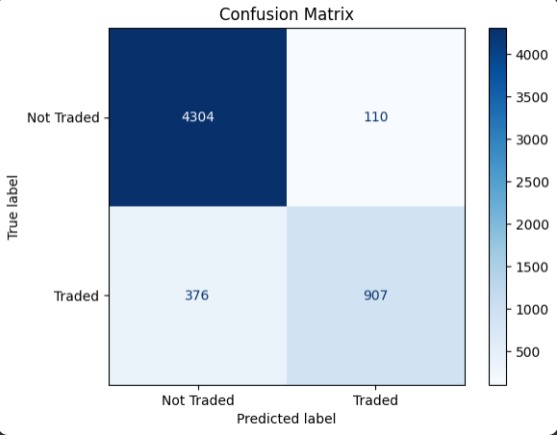
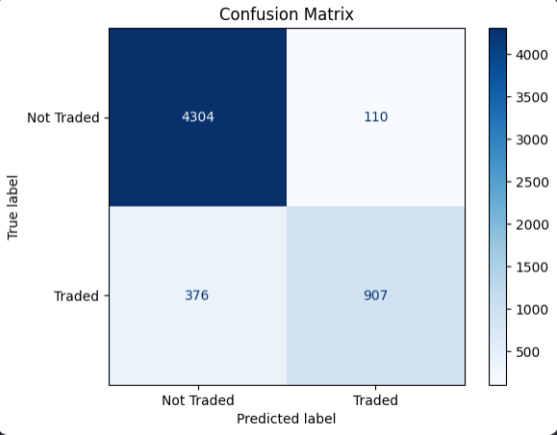
Confusion Matrix
-
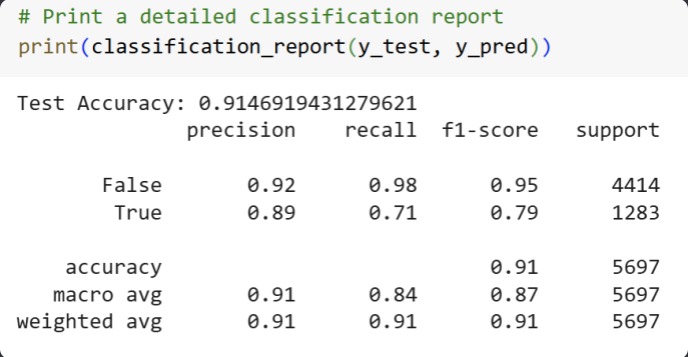
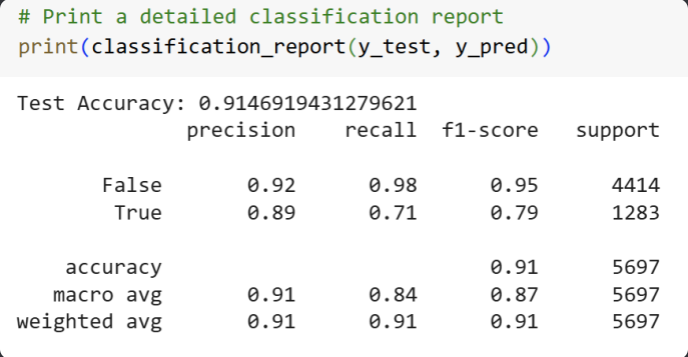
Model Report
-
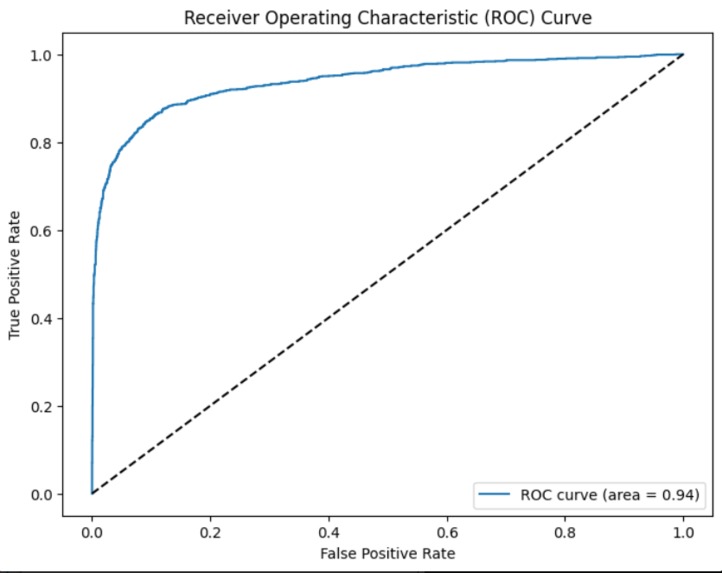
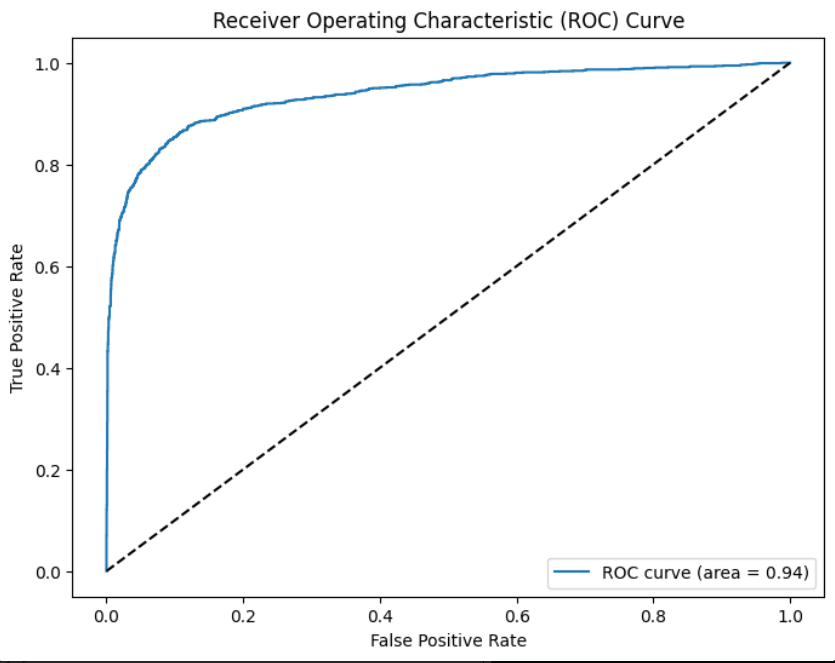
Receiver Operating Characteristic Area Under the Curve
-
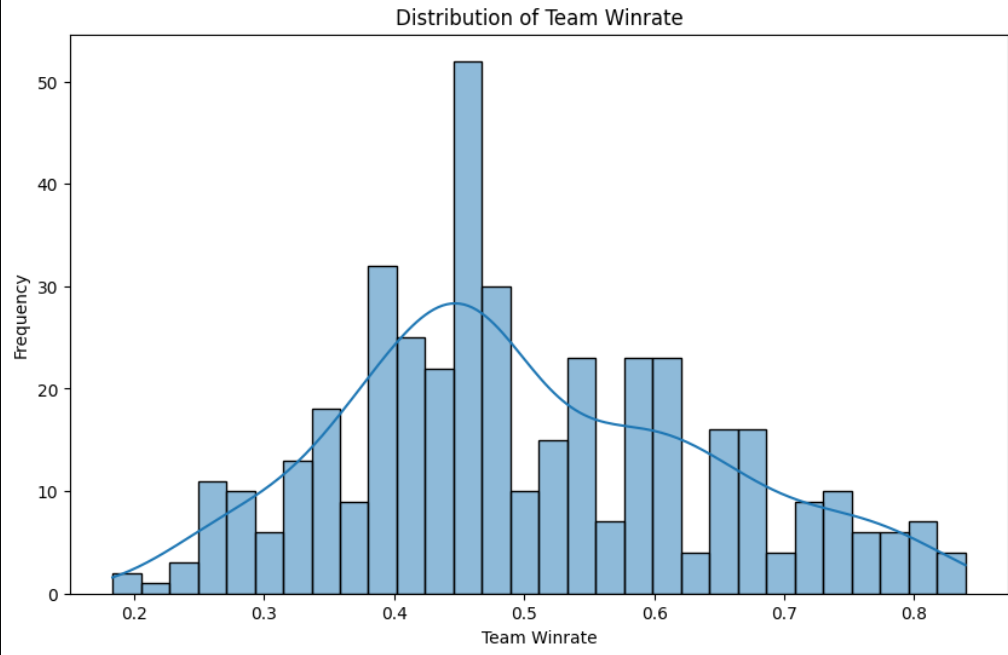
Winrate
What inspired:
Our group was inspired by a mutual appreciation for soccer which led us to seek out and examine the relationship between player statistics and their probability of being traded.
What we learned:
We learned how to clean and process datasets and then create new variables based on previously given variables. Using this processed dataset we improved on our data visualization skills while also starting our journey into machine learning modeling using the xgboost model.
How We Built it:
We preprocessed the data and added new features within the dataset. Using xgboost we used GridSearchCv with scaled position weights to account for imbalanced True/False values within the set using the weighted values we then trained the model to predict the trade probability.
Challenges:
The challenges we faced included a lack of time to create new features, which in theory if created would drastically improve the model's accuracy
Accomplishments:
We were able to successfully process and train the model, while also enhancing our data visualization skills thus giving us a deeper understanding of data processes.


Log in or sign up for Devpost to join the conversation.