
Introduction
City of London is the pulsing heart of Europe and one of the most important cities in the world. With a metropolitan area that hosts about 14 million people, London is a city that you simply never get tired of, thanks to its multi-ethnical population, its intense cultural and artistic surrounding and its business opportunities. These are only a few of the reasons why London has become one of the most attractive and rich cities in the world. Wealth and diversity, though, may lead to social problems and concerns about safety when migration and integration-related phenomena are as huge as they are in London. Leveraging on datasets coming from London Datastore, our project wants to highlight any major correlations between several socio-demographic indicators, including crime, to understand how these may impact the house prices and, therefore, the wealth and the quality of life throughout the city. Data visualization provides details about every LSOA (Lower Super Output Area), in order to produce insights with the finest granularity and precision and make them available for a wide public.
Data Selection
For this project, we decided to use some data regarding London. All the information was found using government data sets that are published on the following website: http://data.london.gov.uk/. The information we took into account is divided into 4 main categories:
- House Price: the value of real estate sale transactions from 1995 to 2013. This data set is composed by four .csv files of approximately 600MB.
- Crime Summary: the summary of the crimes in the city of London. This data set is composed by one .csv file of approximately 70MB.
- Age of People: population by year of age. This data set is composed by one .csv file of approximately 30MB.
- Summary: this category provides a summary of demographic and related data. This data set is composed by one .csv file of approximately 20MB. All the information regarding the datasets has the same granularity by Year and Lower Super Output Area (LSOA). After identifying the core information, the first step was to open the source files and to level out all the information. Each file had a different format and we had to adapt the columns separator, the end-of-line characters and remove all the spaces and double quote (character “) that were inserted in the data sources.
Data Loading in Bluemix
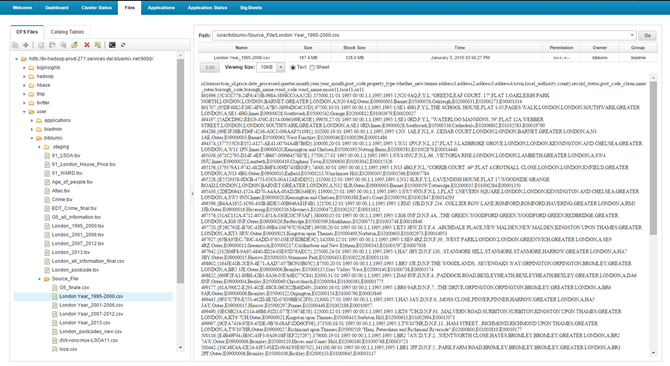
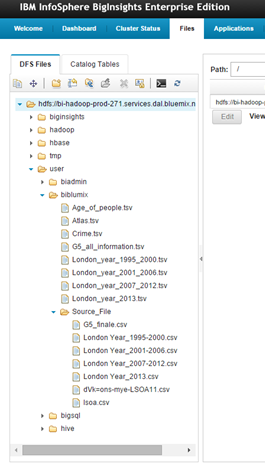
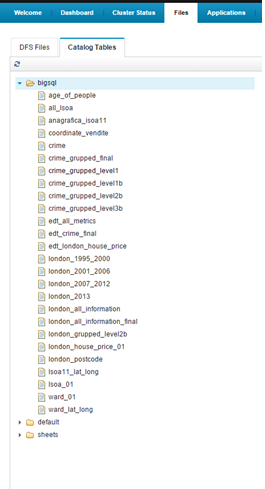
When all the information was cleaned, all the .csv files were loaded in the Bluemix console. In particular, we used the following folder (/user/biblumix/Source_File/) in the DFS Files section.
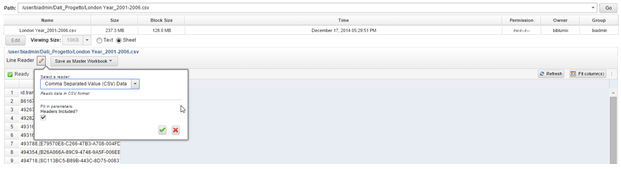
After this step, all the files were exported in a Master Workbook using the button “Save as Master Workbook”.
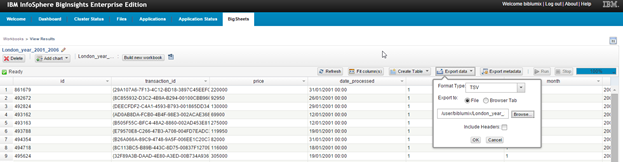
Once all the Workbooks were created, we saved them in a .tsv file.
These steps were necessary since we are able to import data in BIG SQL table only by using a .tvs file. At the end, we had the same files in both .tsv and .csv format:
The last step to import the data in the Bluemix Big SQL database was to create the corresponding tables and load the .tsv files. In order to do it, first of all we created the tables (the following table is one example of the SQL script):
create hadoop table if not exists bigsql.London_1995_2000 (
id varchar(200),
transaction_id varchar(200),
price varchar(200),
date_processed varchar(200),
quarter varchar(200),
month varchar(200),
year varchar(200),
year_month varchar(200),
post_code varchar(200),
property_type varchar(200),
whether_new varchar(200),
tenure varchar(200),
address1 varchar(200),
address2 varchar(200),
address3 varchar(200),
address4 varchar(200),
town varchar(200),
local_authority varchar(200),
county varchar(200),
record_status varchar(200),
post_code_clean varchar(200),
inner_outer varchar(200),
borough_code varchar(200),
borough_name varchar(200),
ward_code varchar(200),
ward_name varchar(200),
msoa11 varchar(200),
lsoa11 varchar(200),
oa11 varchar(200)
)
row format delimited fields terminated by '\t';
and after that we loaded the data.
load hadoop using file url '/user/biblumix/London_year_1995_2000.tsv' into table bigsql.london_1995_2000 overwrite;
This last step was repeated for all the .tvs files.
Big SQL Data Elaboration
The next step was to elaborate the new tables and to create the final tables that are used by Tableau. The transformations were numerous because the goal was to unify the information that was split in different tables and to join the different pieces of information (divided in the four source files) in two or three tables to obtain only one source file. In order to reach this goal, we created a SQL code ad hoc; it selects only the information referring to the intervals of time we were interested in (the last four years) and then it pivots that information to obtain optimal data. These data can be analysed to identify different insights that can be contained in the data. To complete the geographical information, we loaded a file with the information about the space coordinates of the LSOA in Bluemix. This file contains both latitude and longitude of the centroid of the polygon that identifies a single LSOA. At the end of the elaboration, we obtained four different tables containing the optimal aggregated and pivoted data for the next elaborations. Such tables are:
- bigsql.edt_all_metrics: table with all the demographic data
- bigsql.edt_crime_final: table with crime data
- bigsql.edt_london_house_price: table with the data of real estate sale transactions
- bigsql.lsoa11_lat_long: table with the latitude and longitude of LSOA
Watson Analytics
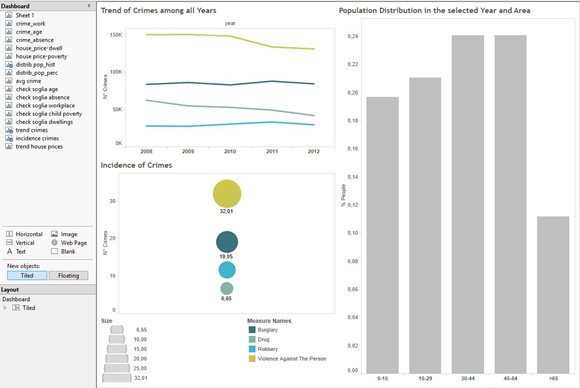
Statistical investigation of data was performed via Watson Analytics. Initial exploration provided an overall view of available information. Features and anomalies were pinpointed, suggesting further refinements via Bluemix queries before the final output is created; for example, a careful missing value management turned out to be necessary when merging datasources. Multi-dimensional representations highlighted patterns and trends. An analysis of the temporal evolution revealed a reduction in children's poverty besides an increase in the number of families claiming for benefits. An improved awareness of public means of sustain may explain this phenomenon. Looking at the districts, some differences were evident for the crimes distribution and house prices.
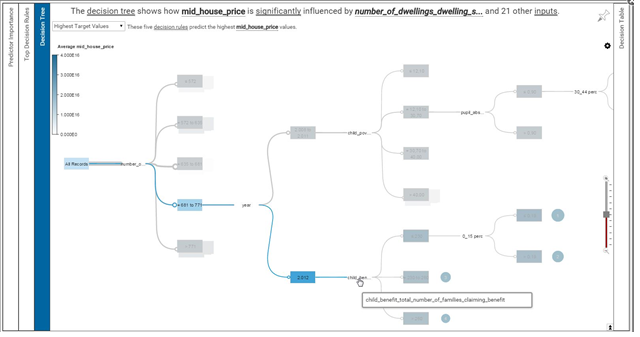
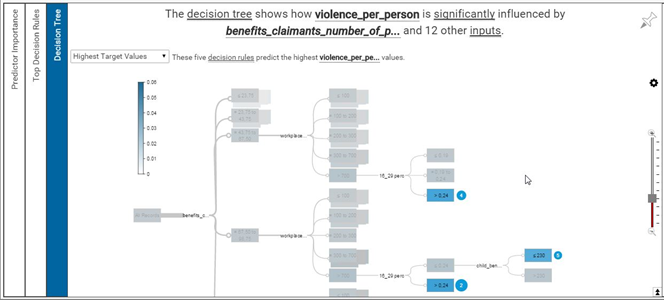
Our aim is to undertstand LSOA features and provide a spatial intuitive representation with deep insights. Watson Analytics predictive service was exploited for discovering the most influential variables and their effective ranges. We focused on four crimes of interest (violence against people, robbery, burglary and drug) and an economic one (average value of house-selling transactions), explored each decision tree and retrieved relevant insights to be represented in the output.
Tableau
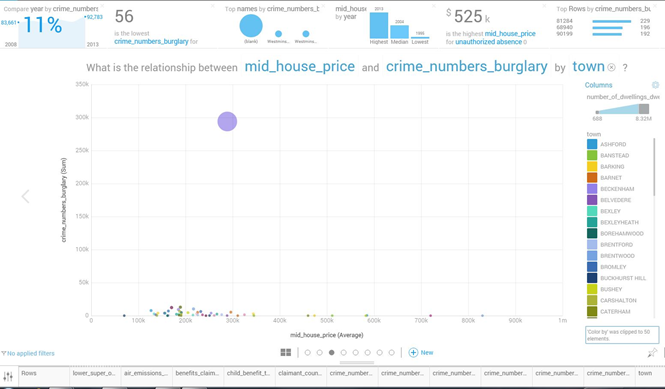
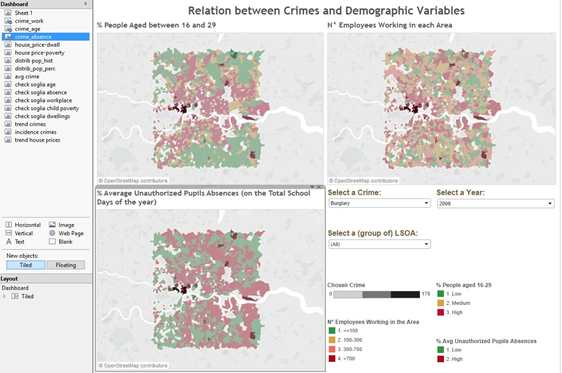
Our final product is a Tableau dashboard with geographical maps showing London area. Spatial resolution relies on LSOA boundaries, retrieved from the Open Geography Portal of the Office Of National Statistics: https://geoportal.statistics.gov.uk/geoportal/catalog/main/home.page We exploit Generalized clipped boundaries for Lower Super Output Areas in year 2011, which allow a detailed and manageable visualization. Access to the dataset is enabled by odbc connection with Bluemix. For each of the four crimes, three maps show the variables that turn out to be the most predictive: percentage of population in the range 15-29 years, average percentage of school days with unauthorized absence and number of people employed in workplaces. These factors are categorized, as suggested by Watson, and their range values are depicted with a heat-readable map; the number of crimes is normalized on population numerosity and represented with the intensity of the color via shading. With the same rationale, the average price of houses is mapped against childen poverty and the number of dwellings. The dashboard is interactive, allowing the user to switch among the crimes, select an year or a range of values for the factors, and highlight a region of interest, with further statistical summaries and plots exploding for each LSOA. The most interesting area is central London, where the number of dwellings is generally high; a few LSOAs are characterized by high house prices, and the percentage of children in poverty is low in those districts. The distribution of criminality slightly changes with the crime of interest; the most dangerous LSOAs are highlighted, confirming they correspond to areas with an elevated percentage of population in the range 15-29 years, a high number of people employed in workplaces; unauthorized absences from school constitute a further warning. Details about each year and the interconnections between the variables can be investigated in the dashboard, which is published on Tableau public: it can be freely navigated and downloaded.
Built With
- bluemix
- ibm-analytics-for-hadoop
- sql
- tableau
- watson-analytics

Log in or sign up for Devpost to join the conversation.