-
-
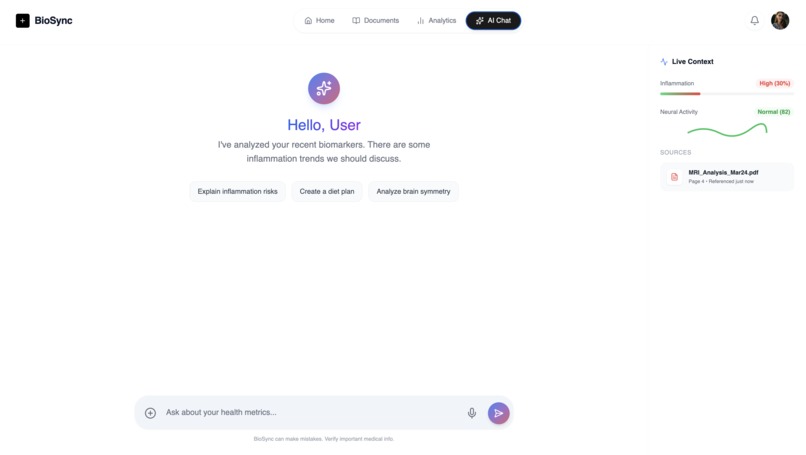
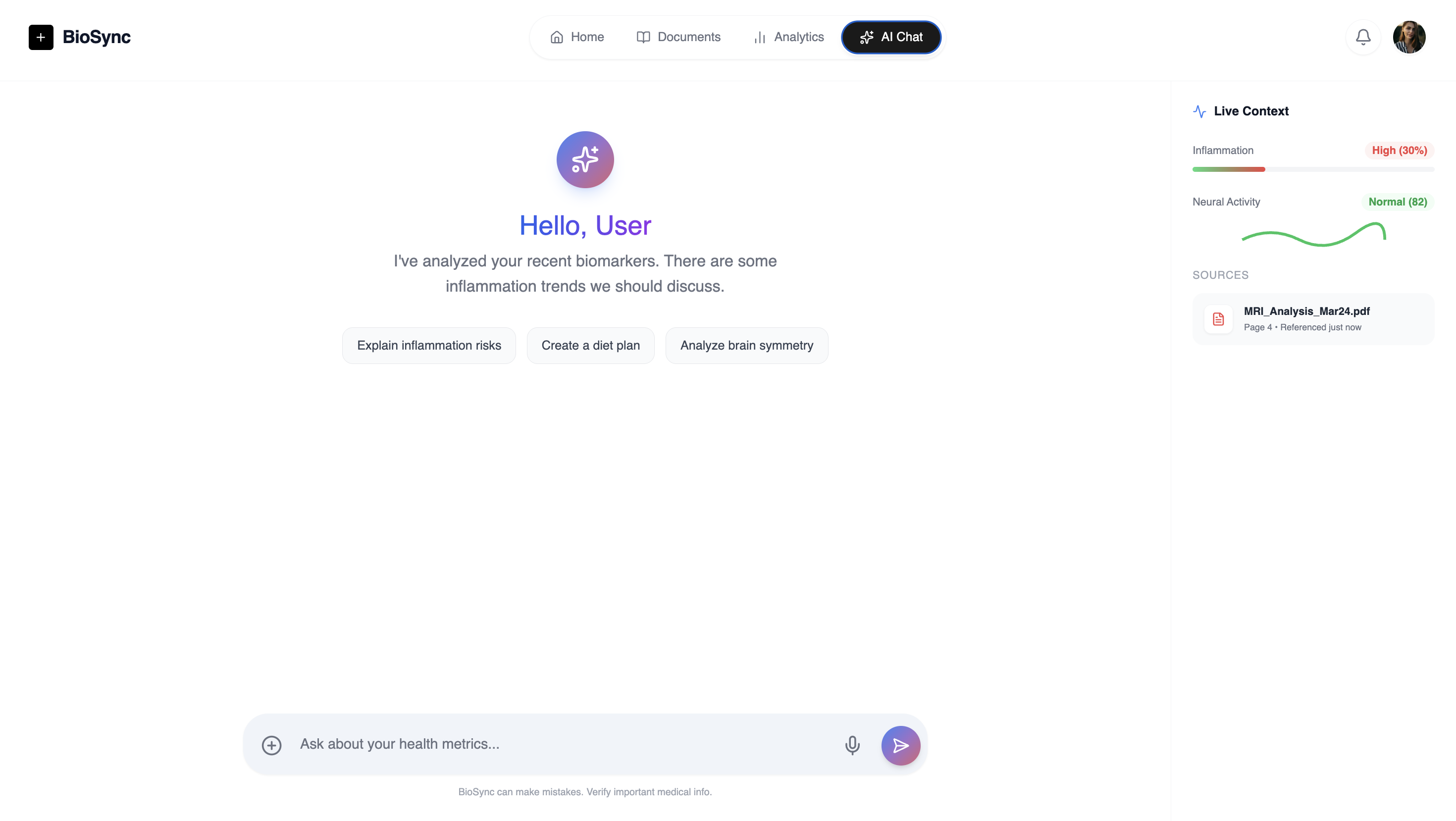
AI Chat
-
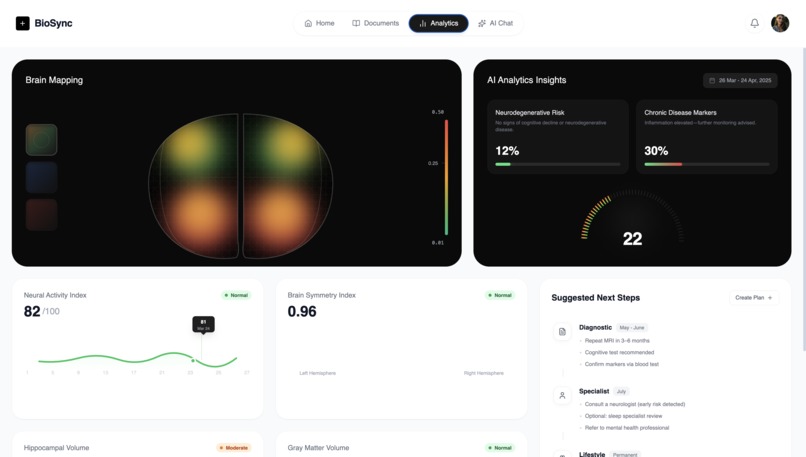
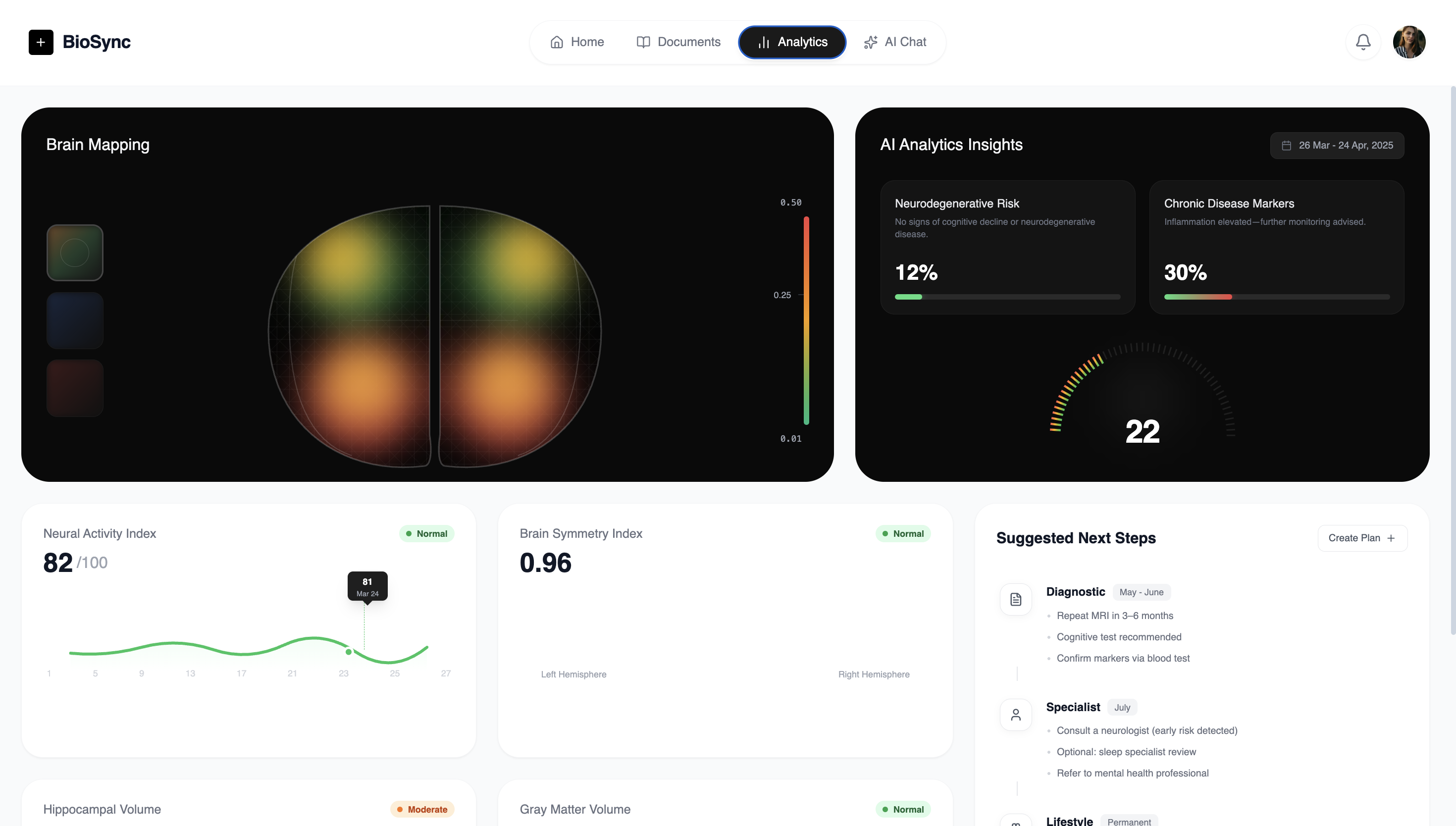
Analysis Interface
-
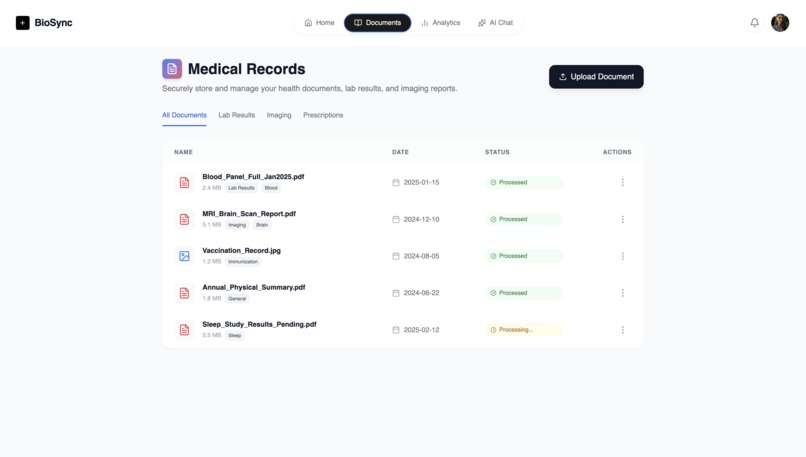
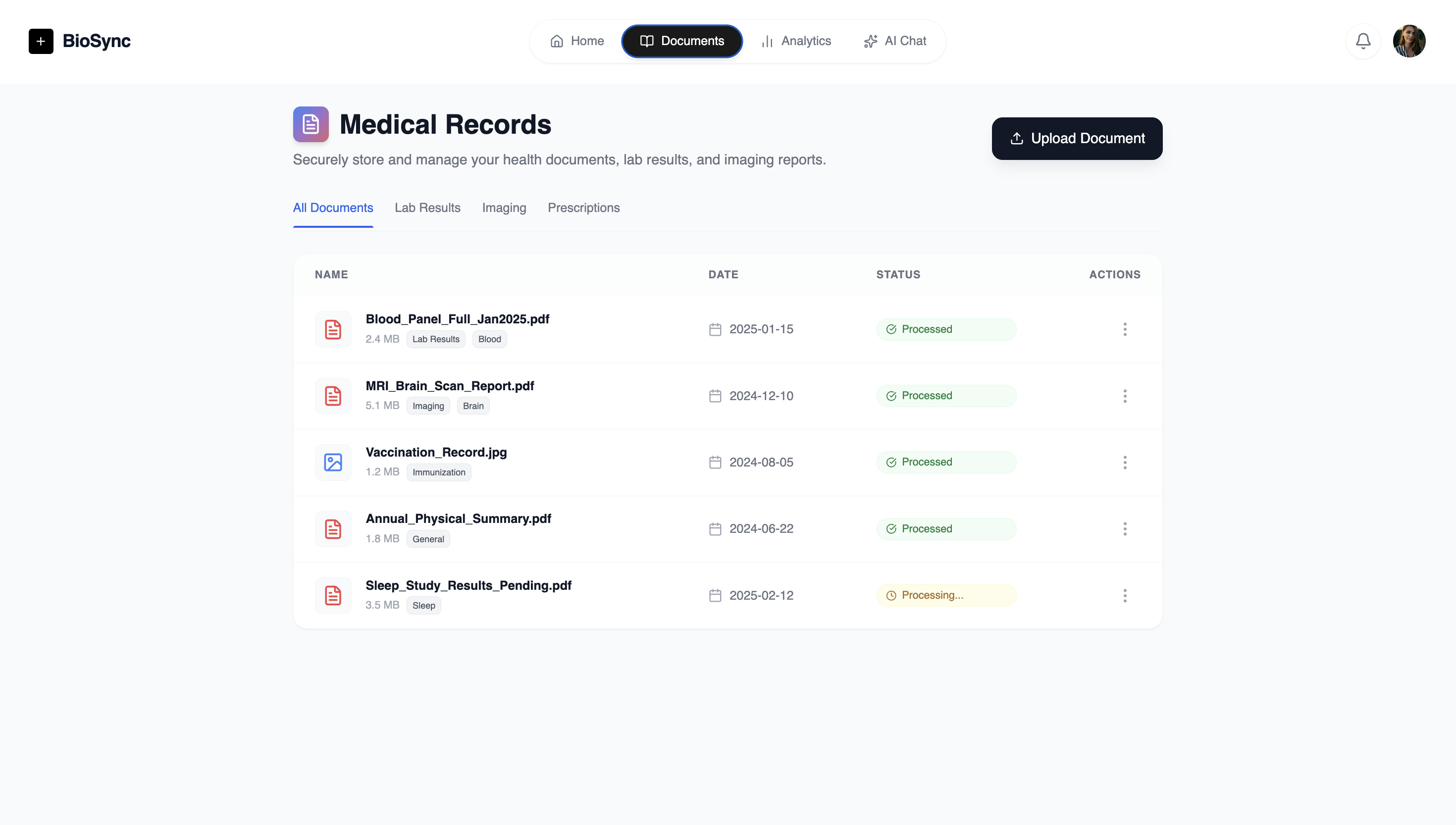
Documents Page
-
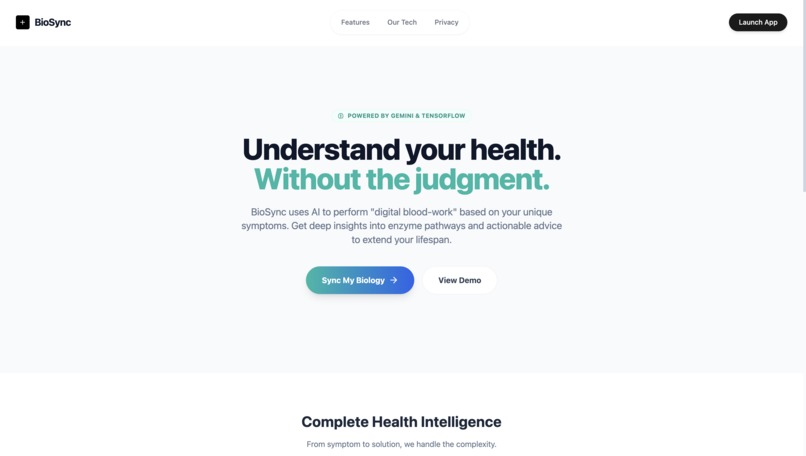
Home Page
-
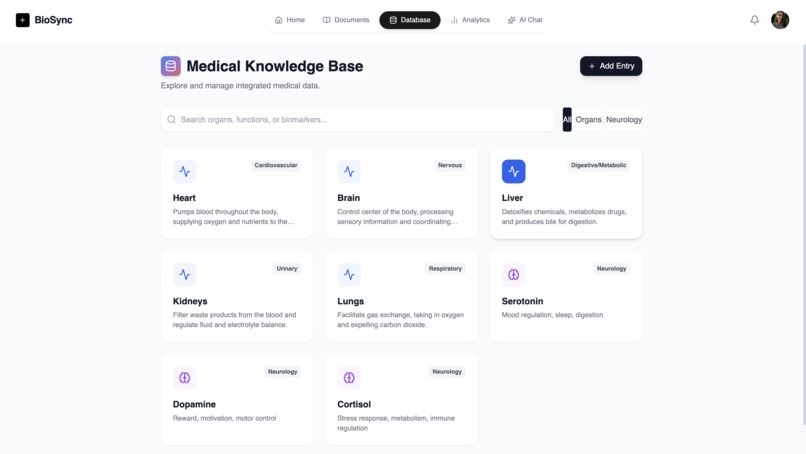
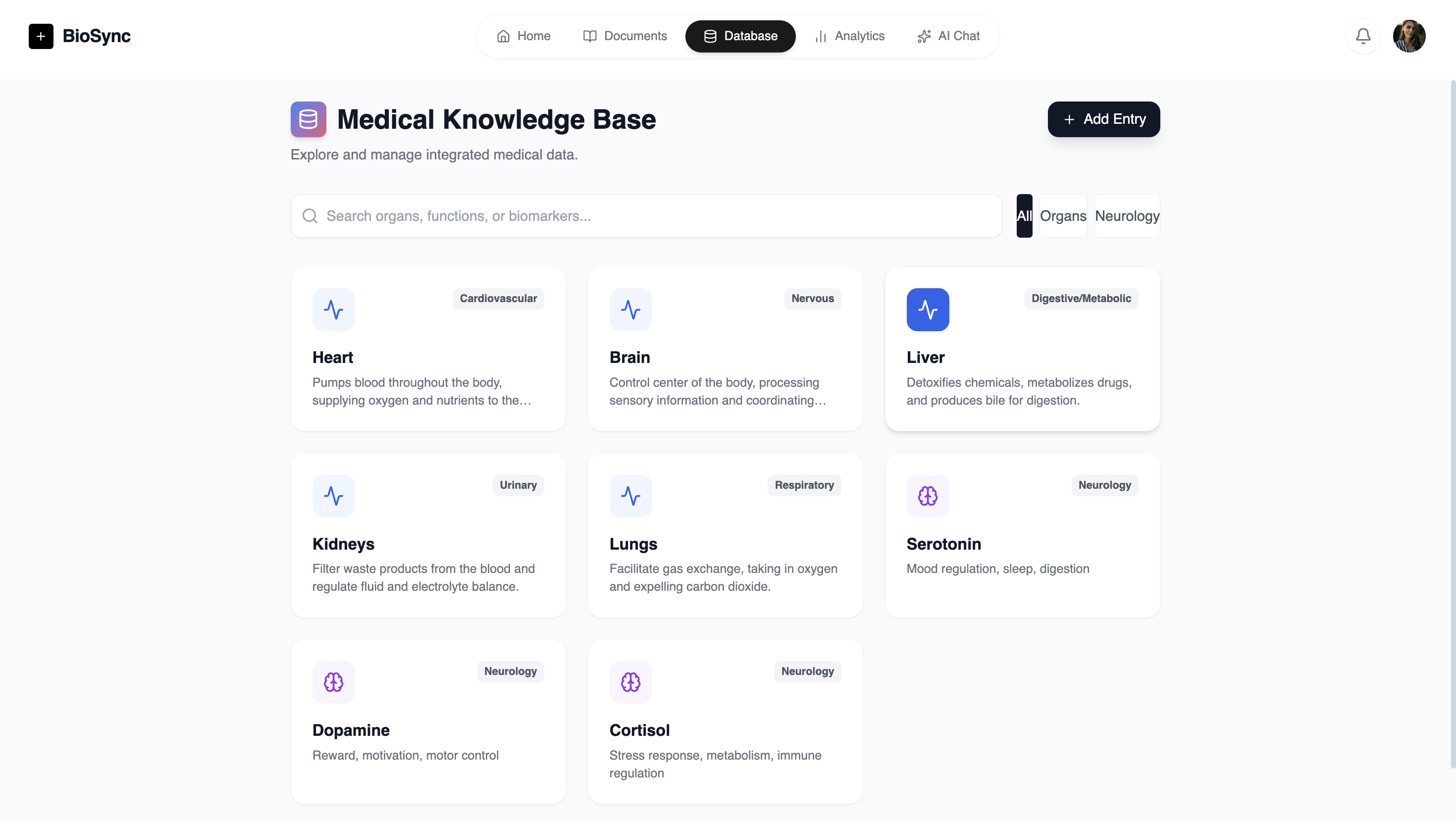
User Database
-
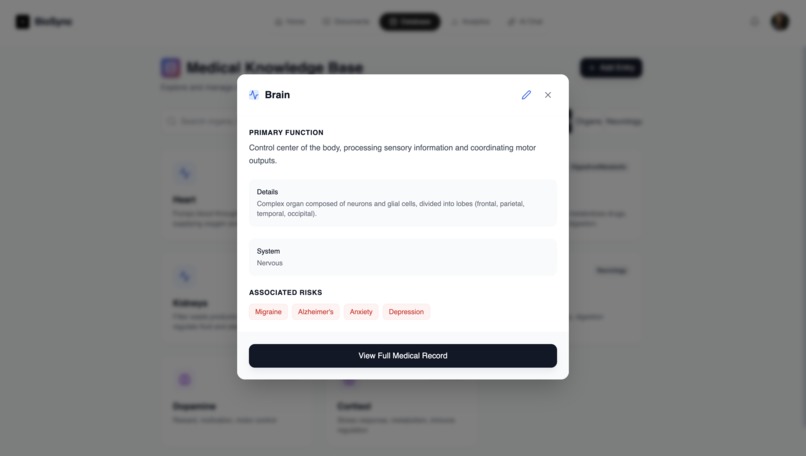
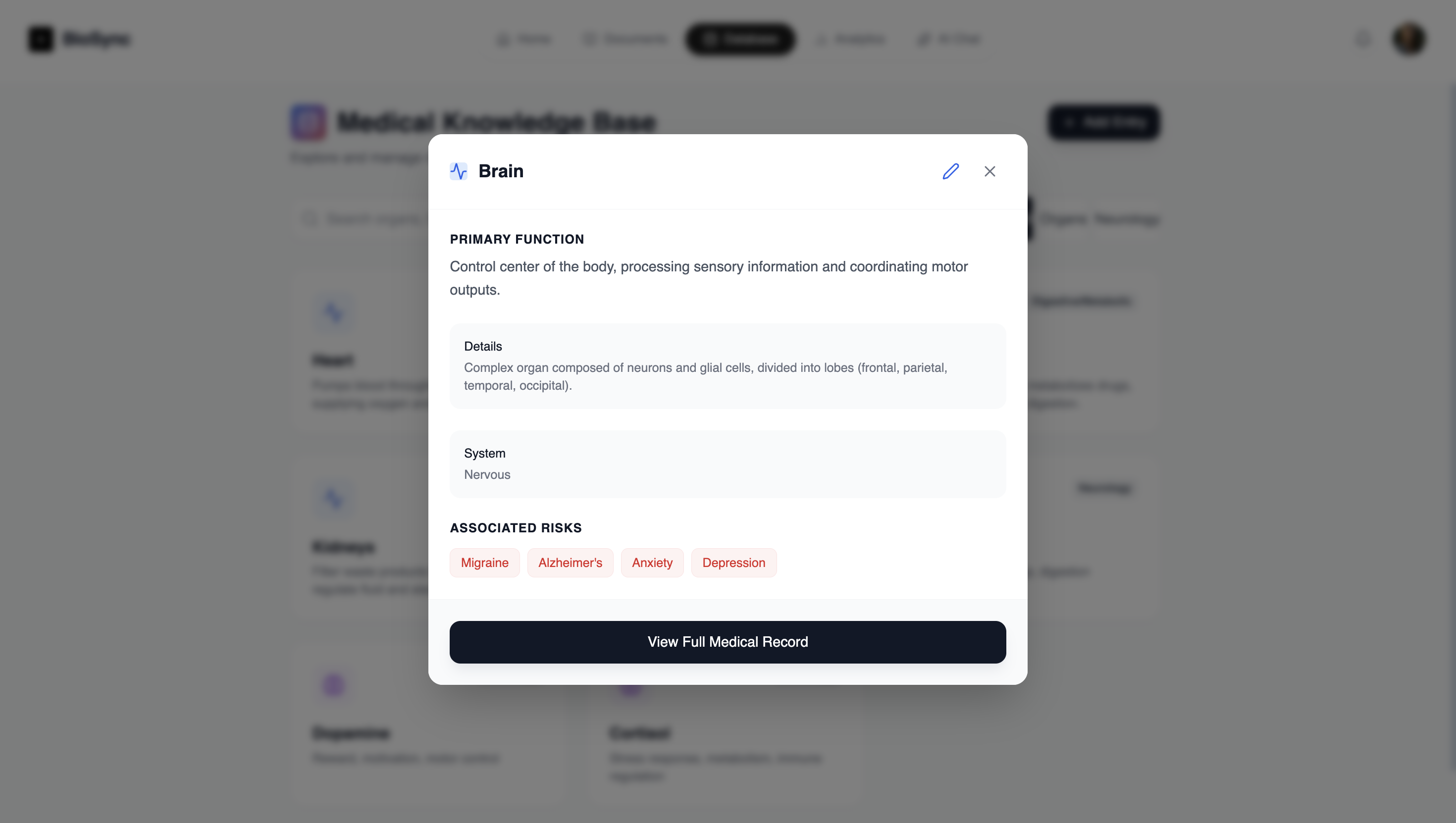
Database Modal
Here is the completion of your project description, filling in the empty sections while preserving your existing text exactly as is.
Inspiration
Seeing my friends and family struggle with health and dieting I always knew there needed to be a way to ask someone knowledgable about health a question without any judgement or need to be vague out of fear. I realised that I could create just that with BioSync. A way to sync your biology using digital technologies.
What it does
BioSync allows users to review AI/ML analysed data by inference of other people's data and comparison to their symptoms essentially allowing for a digital blood-work to be done based on past data. Users can ask an AI Model with access to their data questions in the homepage and receive direct help with how to improve their health stats and analysed issues/symptoms. This way everyone who needs medical help can receive it, not just instantly but accurately. Giving people the ability to know the next steps to take and what they can do in the future to make amendments extending their lifespan.
BioSync goes as deep as enzyme pathways to understand where the user could be in issue within. Performing a full analysis of data using Tensorflow models for the data and Gemini Models for a Multi Agent decision system to return a full response to the user with a RAG like framework to ensure better accuracy and decrease the chance of LLM hallucination.
How we built it
We adopted a modern, scalable tech stack to handle both complex data processing and user interaction:
- Frontend: Built with React and TailwindCSS to create a clean, calming, and accessible user interface that feels approachable rather than clinical.
- Backend & ML: We used Python as our core backend language. We implemented TensorFlow to build our predictive models that analyze user input against anonymized health datasets to infer "digital blood-work" results.
- The AI Engine: The core conversation logic is powered by Google’s Gemini models. We architected a Multi-Agent System where:
- Agent A acts as the Data Analyst, interpreting the TensorFlow outputs.
- Agent B acts as the Medical Researcher, utilizing a RAG (Retrieval-Augmented Generation) framework connected to a vector database of peer-reviewed medical journals and enzyme pathway maps.
Agent C acts as the Compassionate Interface, synthesizing the technical data into empathetic, understandable advice for the user.
Data Handling: We utilized a vector database to store embeddings for the RAG system, ensuring that the LLM references grounded medical data rather than generating text from a void.
Challenges we ran into
- Balancing Accuracy with Empathy: It was difficult to tune the Gemini agents to be factual without sounding robotic. We had to iterate on our system prompts significantly to ensure the AI sounded like a supportive partner rather than a search engine.
- The "Black Box" of Biology: Mapping symptoms to specific enzyme pathways is incredibly complex. Creating a data structure that could represent these biochemical relationships in a way that the TensorFlow model could process was a major hurdle.
- Hallucination Control: In healthcare, false information is dangerous. We spent a long time refining our RAG implementation to strictly ground the AI's responses in the provided context, preventing it from making up treatments or diagnoses.
- Data Integration: Merging the structured numerical output from TensorFlow with the unstructured natural language processing of Gemini required a robust middleware layer to translate "math" into "language."
Accomplishments that we're proud of
- The Multi-Agent Architecture: We successfully got multiple AI agents to "talk" to each other before presenting a final answer to the user. Watching the system verify its own facts before responding was a huge win.
- Enzyme Pathway Visualisation: We managed to not just analyse, but explain deep biological processes (like methylation or glycolysis issues) in simple terms based on symptom clusters.
- Digital Blood-Work Inference: achieving a statistically significant correlation between our inferred data and typical symptom profiles, proving that our concept has real merit.
- Privacy-First Design: Implementing a system where users have full transparency and control over their data right from day one.
What we learned
Medicine and Healthcare management is hard. But it is easier when it is centralised and data isn't randomly made. We use the data given directly in conversation to improve the experience further, with a visible database the user can directly access and remove any data they think is incorrect or modify it. This data is used contextually. We learnt that contextual data usage throughout medicine may be the way going forward. Doctor conversations being stored to understand how a patient may describe their symptoms and how data correlates to their description.
What's next for BioSync
- Wearable Integration and more advanced real life monitoring: We plan to integrate APIs from Apple Health, Fitbit, and Oura Ring. Real-time heart rate, sleep, and activity data would make our "digital blood-work" exponentially more accurate.
- Telehealth Handoff: While BioSync provides amazing insights, we want to add a feature that compiles a "Doctor's Report" summary that users can export and hand directly to their GP, bridging the gap between digital advice and clinical practice.
- Expanded Enzyme Database: We aim to increase the depth of our biochemical maps to cover rare genetic mutations and metabolic disorders.
- HIPAA Compliance & Security: As we move from prototype to product, we will be implementing end-to-end encryption and full HIPAA compliance to ensure that BioSync is ready for real-world medical data handling.
Built With
- react
- torch

Log in or sign up for Devpost to join the conversation.