Inspiration
Marine biologists and organizations like NOAA deploy underwater hydrophones that record thousands of hours of ocean audio. Most of it never gets reviewed — there's simply too much for humans to listen through manually. Whale vocalizations get buried in noise, and missing them means missing critical data on population health, migration patterns, and responses to threats like shipping traffic and military sonar
What it does
BioSonar takes raw ocean audio, converts it into mel-spectrograms, and runs them through a fine-tuned ResNet-34 CNN to identify which of 8 whale species is vocalizing. If the model's confidence falls below 75%, it flags the detection as uncertain rather than forcing a prediction. The Streamlit app lets researchers upload any audio file and get an instant species prediction with a full probability breakdown across all 8 species.
How we built it
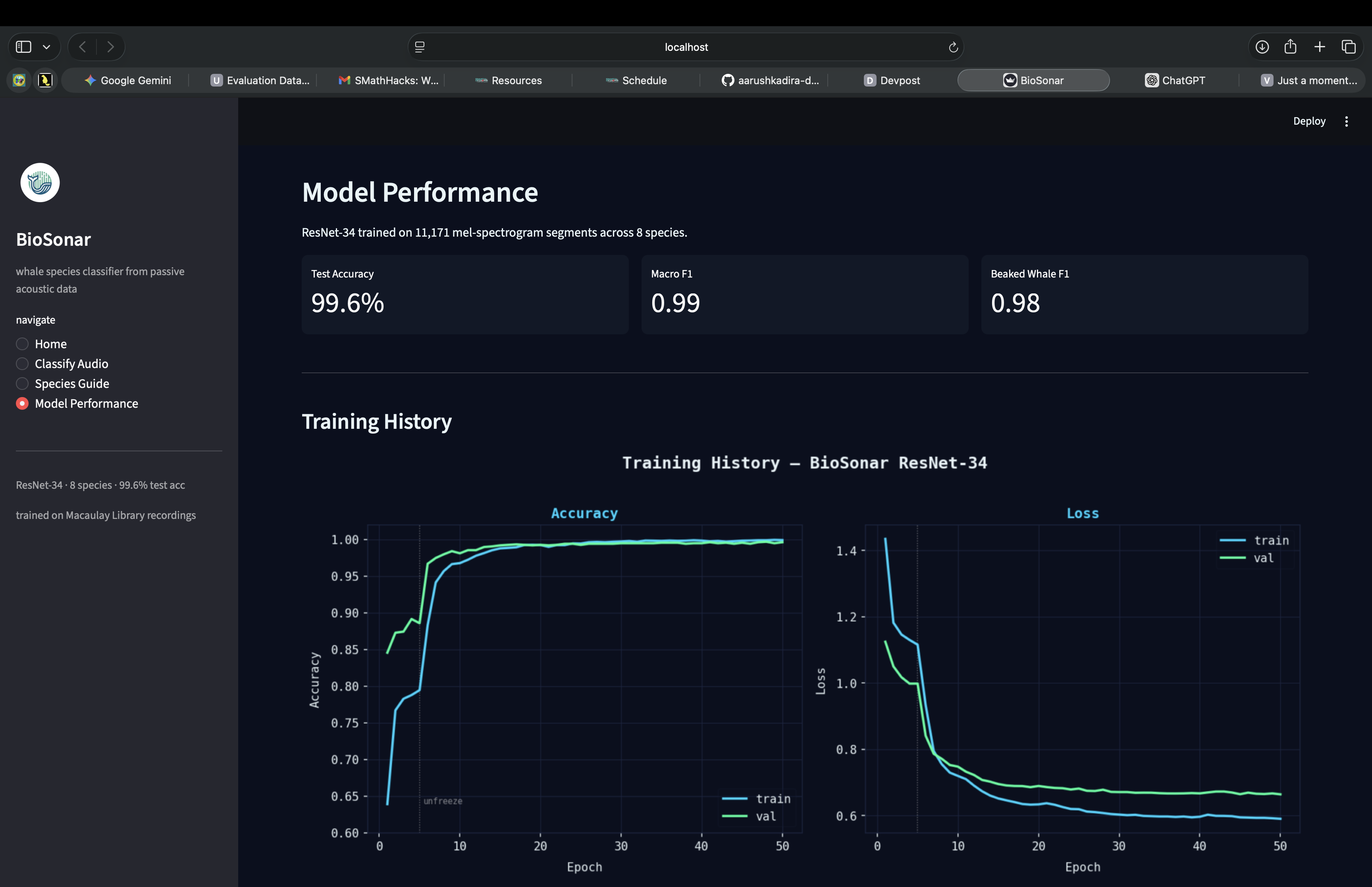
The pipeline has four stages. First, I downloaded 48 passive acoustic recordings from the Macaulay Library (Cornell Lab of Ornithology) covering 8 species and uploaded them to AWS S3. Second, I sliced each recording into 5-second segments and filtered out silence and off-frequency noise using species-specific frequency bands from the bioacoustics literature, ending up with 13,969 segments. Third, I converted each segment into a 128-band mel-spectrogram PNG at 224x224 pixels. Fourth, I fine-tuned ResNet-34 on the resulting 11,171 training images using progressive unfreezing which freezed the backbone for the first 5 epochs to train only the classification head, then unfreezing layer3 and layer4 with a lower learning rate. I added SpecAugment (frequency and time masking), dropout before the final layer, label smoothing, and class-weighted loss to handle the imbalance between species like beaked whale (~400 segments) and blue whale (~2,000 segments).
Challenges we ran into
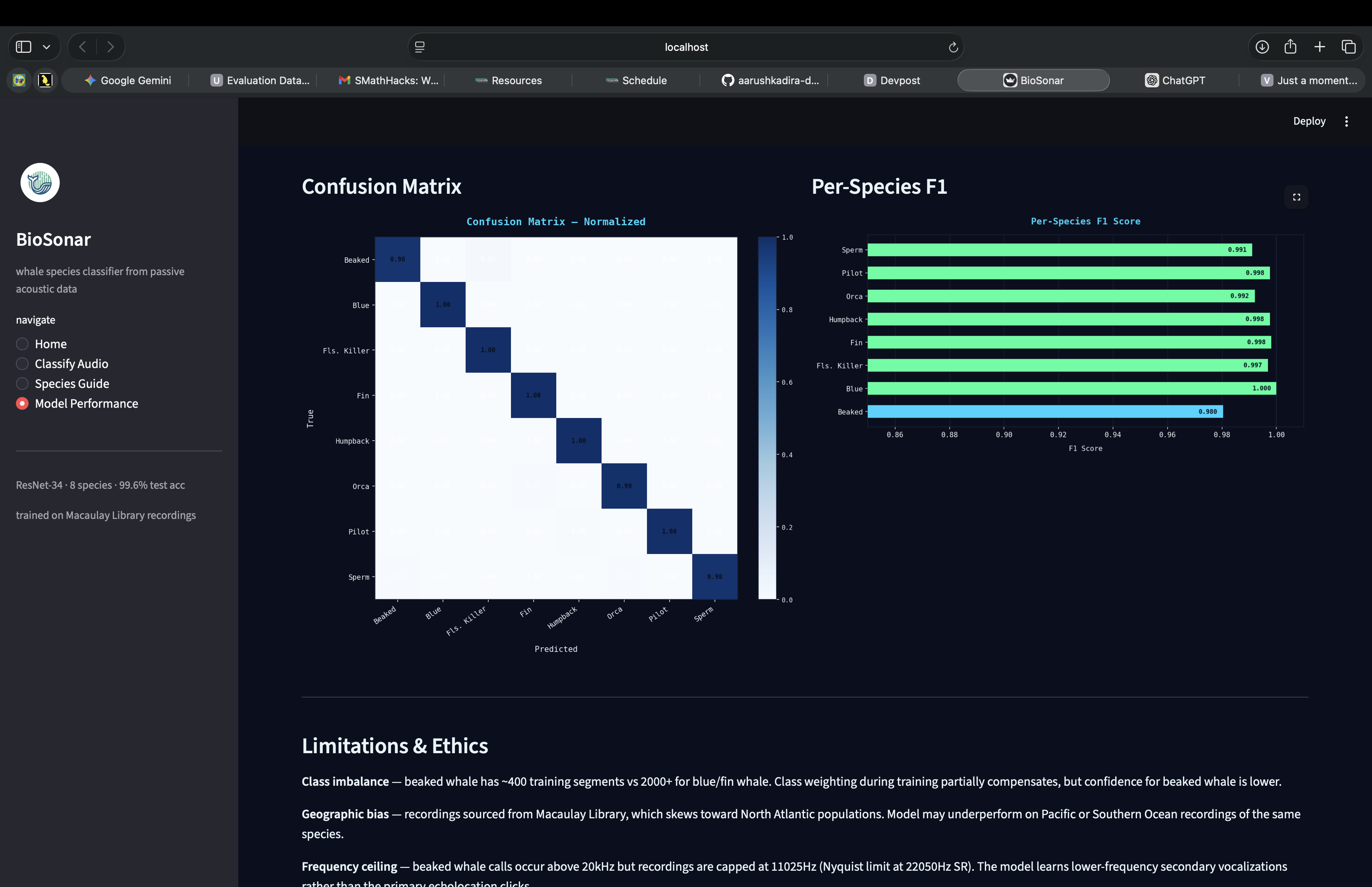
The biggest technical challenge was beaked whale. Their primary echolocation clicks occur above 20kHz, but standard recordings are capped at 22050Hz sample rate, meaning the Nyquist limit cuts off the most distinctive part of their calls. The model had to learn from lower-frequency secondary vocalizations instead. Class weighting and careful frequency filtering helped, but beaked whale remains the weakest class. The dataset was also geographically was also skewed. The Macaulay Library recordings leaned heavily toward North Atlantic populations. The model may underperform on Pacific or Southern Ocean recordings of the same species.
Accomplishments that we're proud of
Getting beaked whale F1 to 0.98 despite having less than a fifth of the training data of the majority classes. The combination of class-weighted loss, frequency filtering, and progressive unfreezing made a class that should have been the weakest nearly match the rest
What we learned
Progressive unfreezing made a bigger difference than I expected. The val accuracy jumped from ~89% to ~97% the epoch after unfreezing layer3 and layer4. The confidence flagging system also turned out to be one of the most important design decisions: a tool that admits uncertainty is far more useful for real research workflows than one that always outputs a confident answer
What's next for BioSonar
- Expand to more species and larger geographic coverage
- Test on real NOAA hydrophone data
- Add time-stamped detection output for long recordings so researchers can jump directly to whale vocalizations

Log in or sign up for Devpost to join the conversation.