


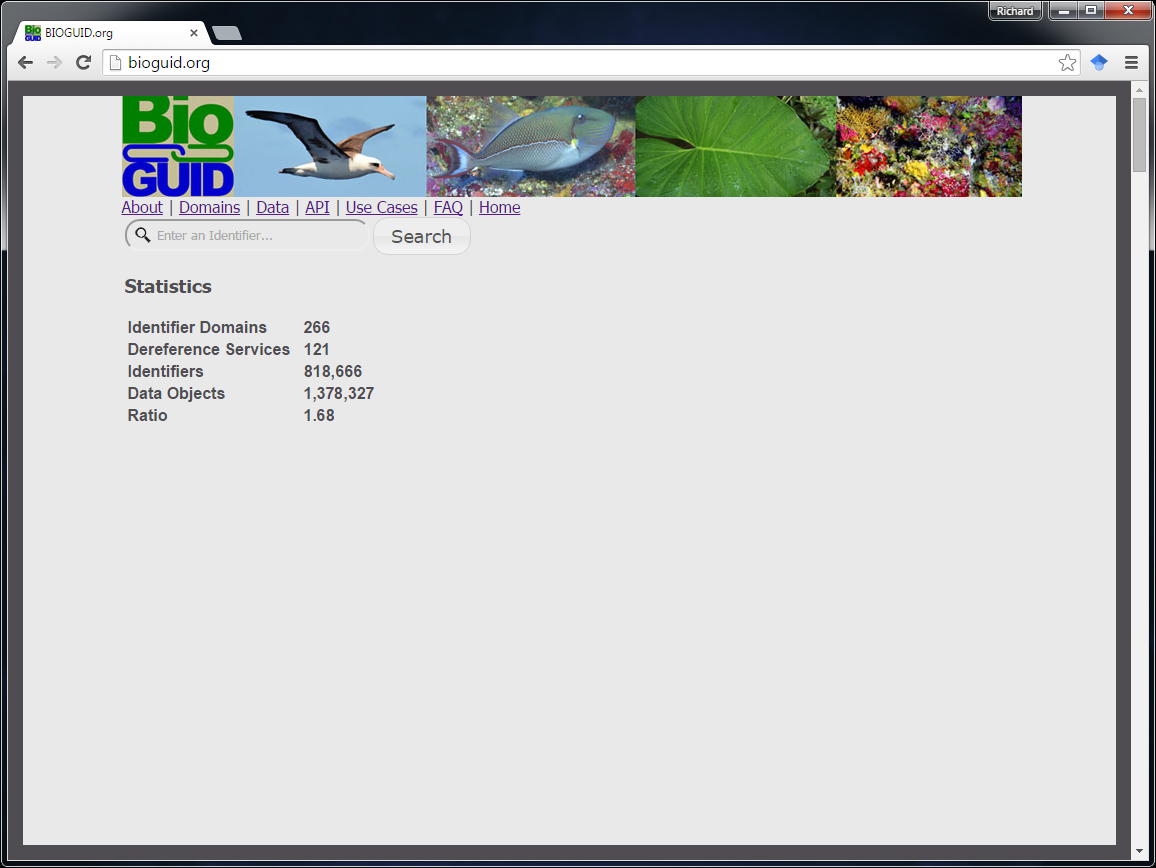


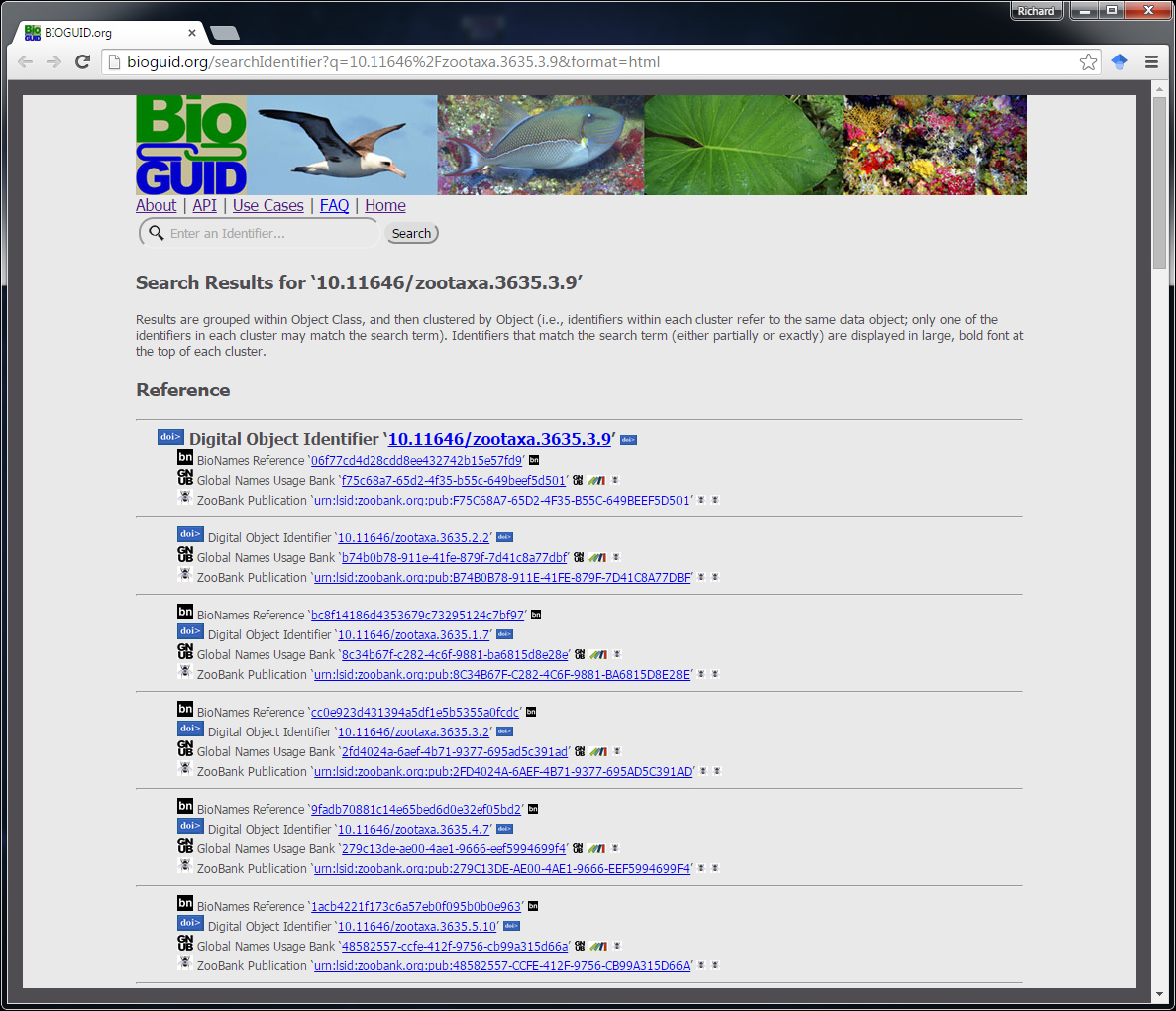
BioGUID.org is a service for indexing and cross-linking identifiers for data objects within the realm of Biodiversity informatics. The importance of reliable globally unique identifiers for mobilizing biodiversity data has been well established through multiple workshops, whitepapers, and publications spanning several decades. Although individual databases have attempted to establish cross-links among identifiers, these efforts have been limited in scope and content. BioGUID.org establishes a global platform for indexing and cross-linking identifiers of all kinds, to better facilitate establishing relationships among digital biodiversity objects. The core items managed by BioGUID.org are “Identifier Domains” (sets of identifiers) and the Identifiers within those Domains. Each Identifier Domain may have one or more “Dereference Services” associated with it (e.g., http://dx.doi.org/ for DOIs). Identifiers are cross-linked to each other by being anchored to the same “Identified Object”. These Objects may additionally be linked to each other according to relationship types, such as Congruent, Includes, and Overlaps. New services allow end users to upload batches of linked or unlinked identifiers, and download sets of cross-linked identifiers. With a core set of web services, documentation and web tools, and more than a billion indexed identifiers (and growing), BioGUID.org is designed to help tie Biodiversity data together.
I was inspired to build BioGUID.org to make it easier to cross-link biodiversity datasets, and make them more powerful by harnesing identifiers.
Built With
- coldfusion
- javascript
- sql-server


Log in or sign up for Devpost to join the conversation.