Existing problem
My first try of using GBIF API was getting occurrence download. I notice it is very difficult to do even for me an IT specialist with big background. Main problem was a construct JSON request with predicates. It has machine oriented syntax. Next problem was to run curl in command line. In Linux and Mac OS it is not a very big problem. This tool installed by default in system. But in Windows you need to download special command tool. But even after this, you need to run it correctly. For ordinary not IT people it is a very difficult. After download was created you have an archive with several files. The most interesting is occurrence.txt. But it has a lot of columns, more than 200. It's hard to process, e. g. in Excel or R-project. Most columns not need and ofter for processing you need just 2-5 columns. It is pity to download such big file just for little part of it. Then you have to process this data using some statistic methods. You may use Excel for simple processing or R for something difficult. And again this is a problem. Problem to find formulas, make sequence of computation, know R, and so on. All these problems is barrier to many people who wants to work with GBIF data. I talk with several biologist and they were agree with me. They don't know what to start with.
Solution
And that is why I decide to create web service BioDigger which helps to do all these technical tasks.
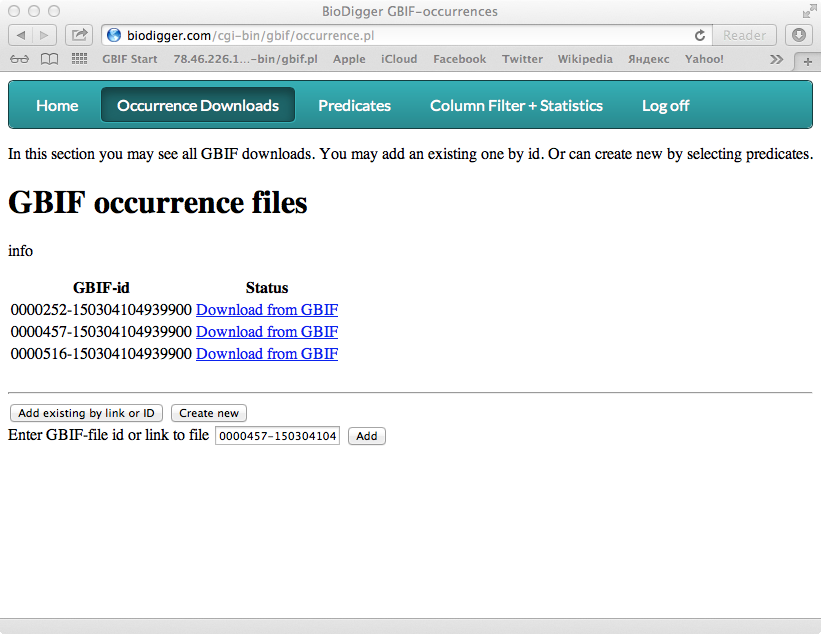
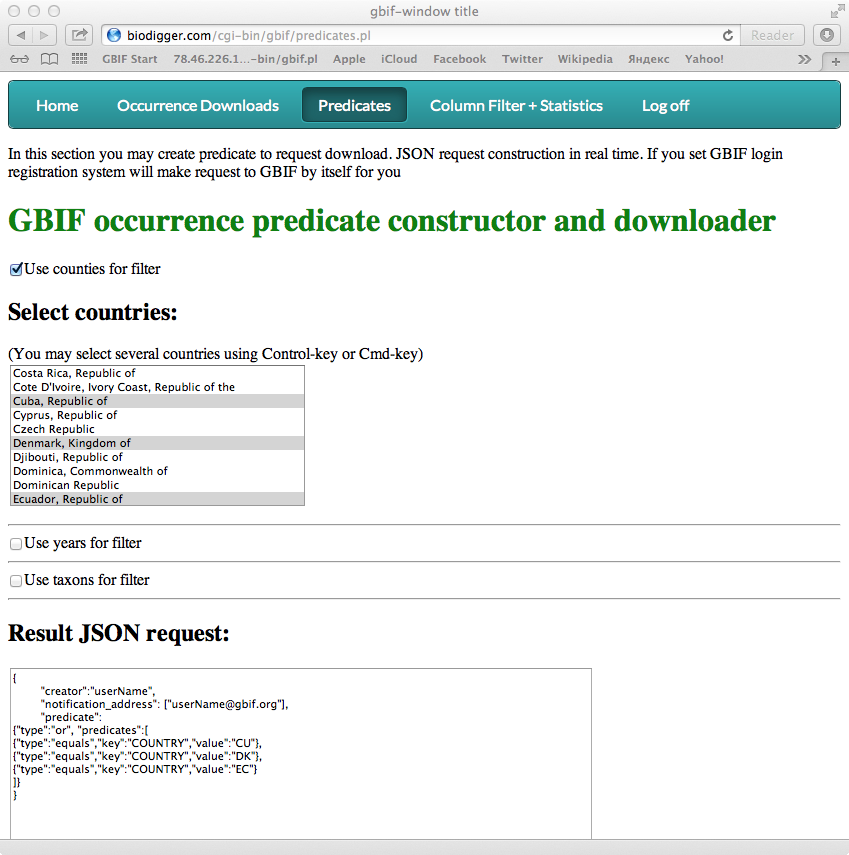
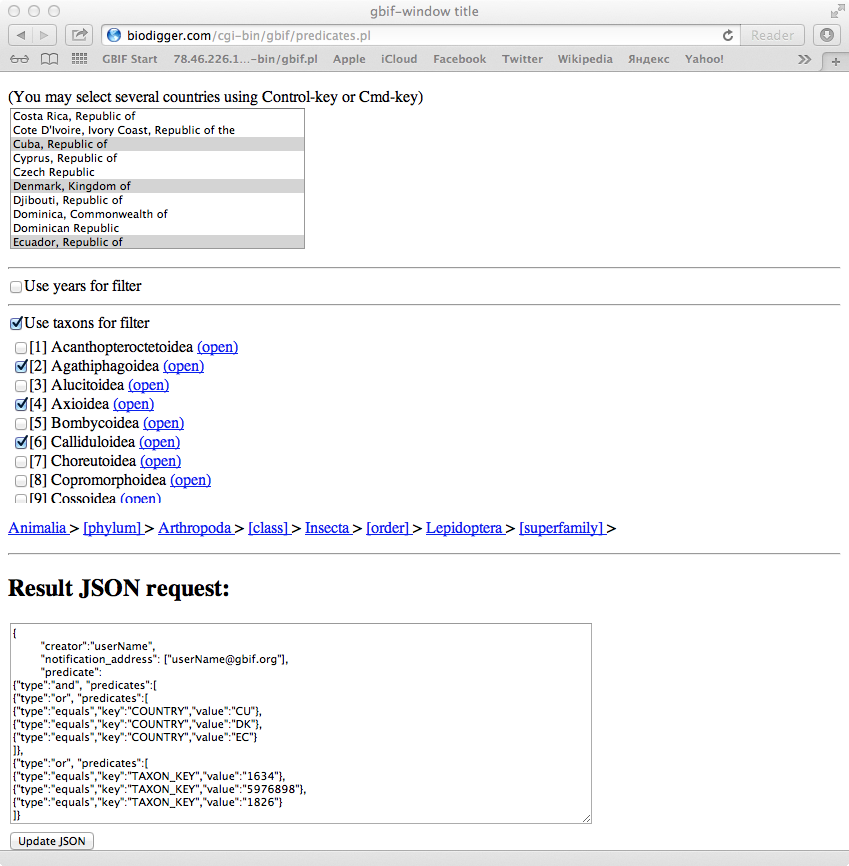
- First of all create JSON for given predicates. You just need to select in listbox or checkbox your conditions. Now it is an any number of countries and any number of taxons (GBIF Backbone Taxonomy) of one taxon rank (in nearest time I plan to and all other predicates from API). And JSON will be created immediately. This JSON code you can use by yourself by coping to curl or you may allow BioDigger to do it for you in one click. BioDigger send request to GBIF with your GBIF login and password. Then it will watch to process of download. Then file will be ready you'll be notified. This file will be in your list. To this list you may add existing GBIF occurrence download by its ID. All these downloads will ready for next processing.
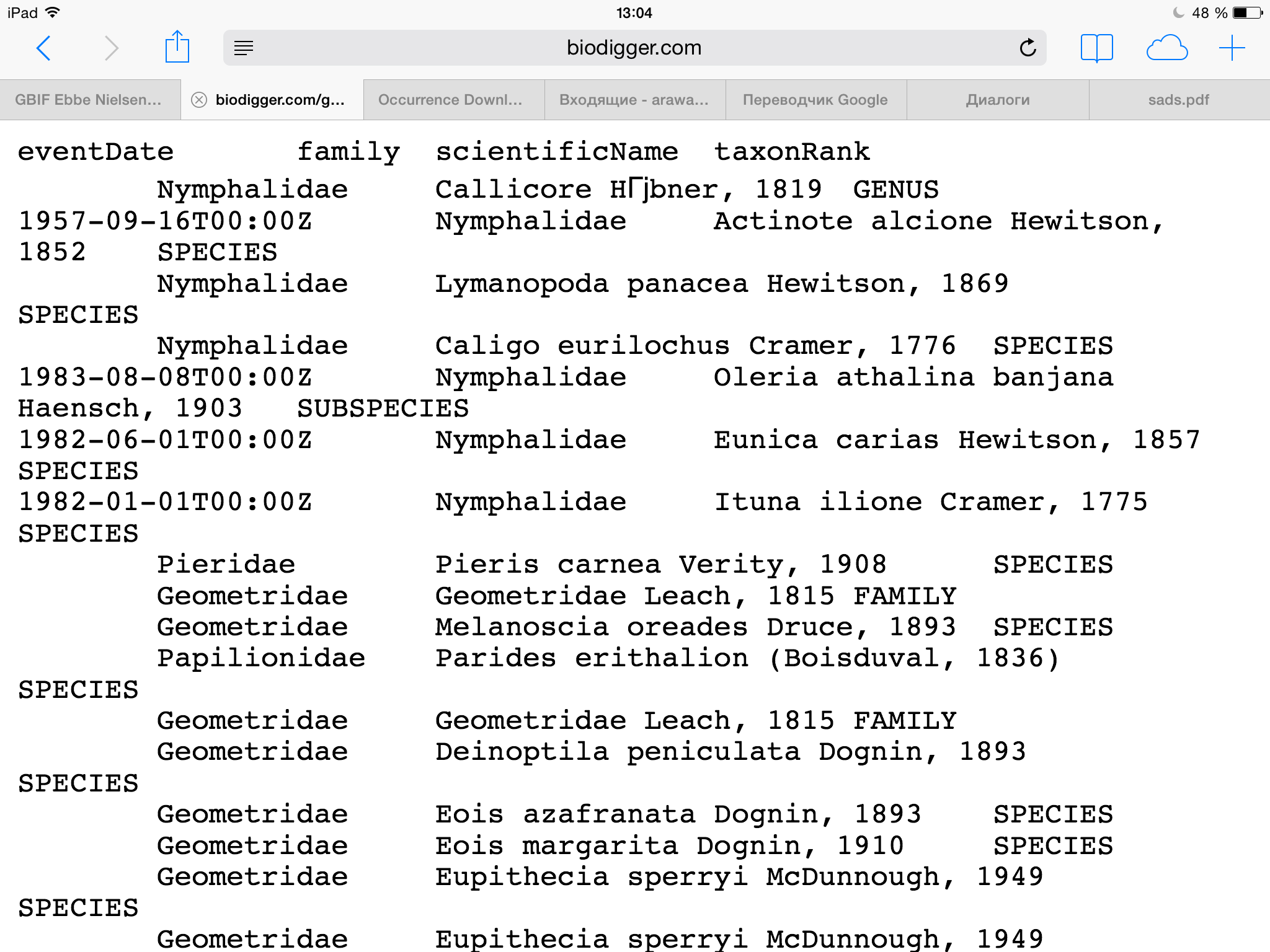
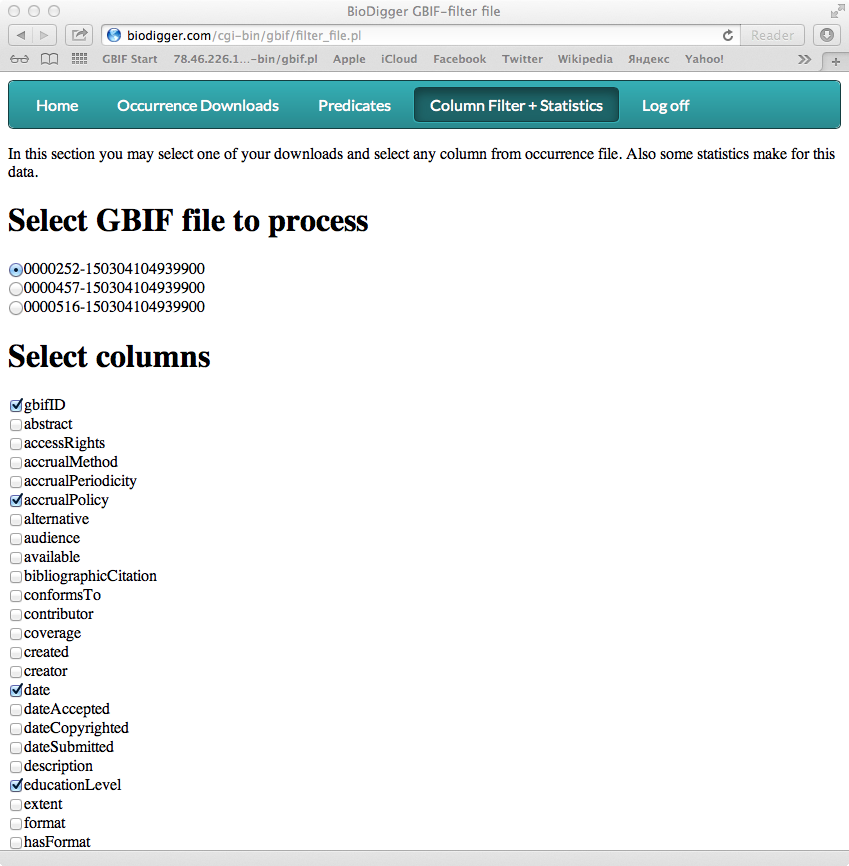
- Selecting columns. For ready downloads you may select any number of columns from occurrence.txt file. You just need to select column names in the full list of them. Then BioDigger will download zip file, extracts occurrence.txt and create new file which contains only selected columns and show link to it for you to download it.
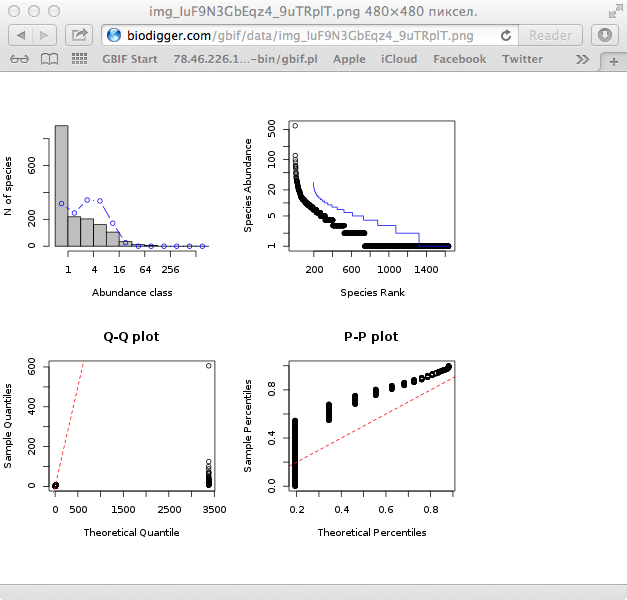
- Statistics. Then you select columns also will computed "Maximum Likelihood Models for Species Abundance Distributions" using R (package sads) for this data. And image with diagrams will be created.
The target users is all scientists and students who want to get data from GBIF by special predicates and process it using some statistical methods. Who not fluent in low level IT tasks. And don't want to lose time to study it.
Now web service BioDigger is proof of concept. It contains just main parts and will be expanded in future.
Plans:
- Add all predicates from GBIF API.
- Add more statistics methods using R-project from book "Measuring Biological Diversity" by Anne E. Magurran and "Biological Diversity: Frontiers in Measurement and Assessment" by Anne E. Magurran and Brian J. McGill.
- Add good looking design.
- Add geo maps for preicates.
- Automatic creating statistical reports (as HTML or PDF files)
- Tools for automatically search errors in data

Log in or sign up for Devpost to join the conversation.