-
-
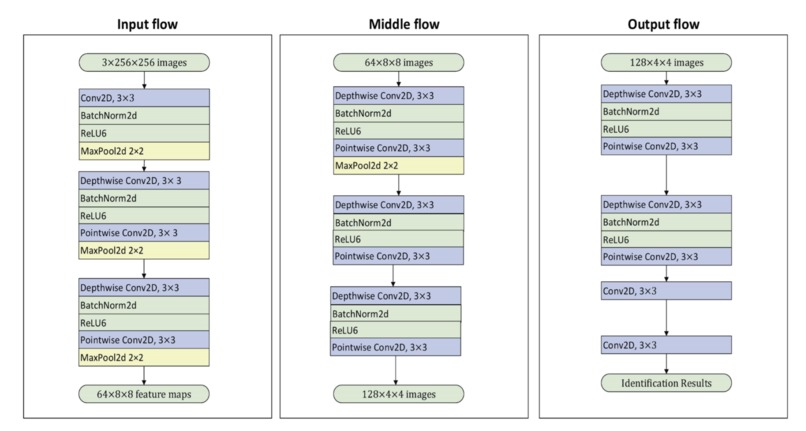
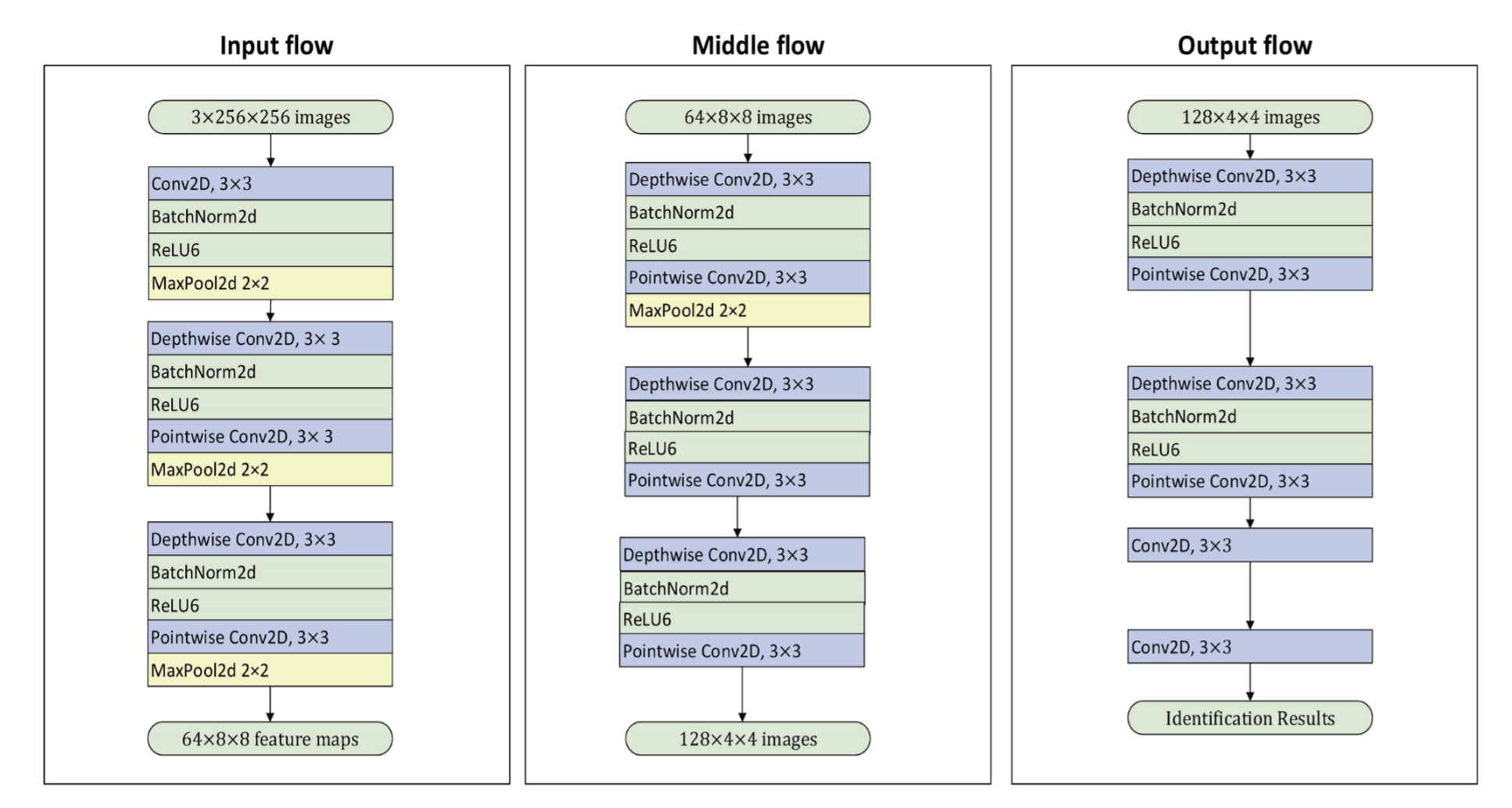
BioCafe CNN Model Software Architecture
Inspiration
BioCafe upcycles spent coffee grounds and revitalize them to use in our self-care products. We aim to reduce greenhouse gas emissions from our startup and to create value from waste. However, as we reuse spent coffee grounds, we need to ensure that the coffee grounds/beans are still of good quality and still maintain their benefits. There are currently two ways of coffee bean inspection: visual and mechanical, but their main pain points are that external factors can reduce the accuracy. Thus, we decided to create a Convolutional Neural Network model that can process coffee bean images and classify them into "Pass" or "Fail" categories.
What it does
Our CNN model will process images of coffee beans and categorize them into two groups: Group 1: Pass - coffee beans are of good quality and can be used Group 2: Fail - coffee beans do not meet the standard quality and should not be used
The algorithm will involve visual search, semantic segmentation, and identification of objects (coffee grounds) from images and .csv datasets. Our model will be given images of coffee bean to process and it would be able to classify the images to differentiate good quality beans from defective ones.
How we built it
We firstly set 4 parameters for our CNN model to follow and decide based on them whether a coffee bean is pass or fail. The parameters are:
1+2 Size + Shape: Diameter of coffee bean should be equal to either 14/64, 16/64, or 18/64 inches Matching these sizes and a normal shaped bean will make the beans classified as “Pass” This is because these sizes of a bean offer the best ratio between quality and reliability
Color: Classifies the color of the coffee beans Colors are: "Green", "Blue-Green", "Bluish-Green", "None"
Flavor: Classifies as "Arabica", "Robusta", "Other"
To train our CNN model, we started off by using neural network and 2 Github open source datasets:
- 2,149 images (good beans) and 2,477 images (bad beans) - Size and Shape
- Arabica and Robusta (raw + cleaned) .csv datasets - Color and Flavor
Our initial software development was done using Python. We used forward propagation method in CNN to randomly initialize the weights (with a mean of 0) to our parameters. Our model was then trained in neural network with our datasets to be able to classify the images. Each coffee bean image was to be segmented to locate the boundaries and partition it into multiple segments. Finally, our model's architecture was in 3 parts - Input Flow, Middle Flow, and Output Flow. It include depthwise convolutional, pointwise convolutional, ReLu6, and maxpooling layers.
Challenges we ran into
- Collecting cleaned coffee images data for testing and training our machine learning model
- Need good quality images of the coffee beans for the model to accurately classify into pass/fail categories
- Lack of proper resources and background in software development to create our image classification model
Accomplishments that we're proud of
We were able to develop a functional CNN algorithm that is capable of processing classification of coffee beans, given our specified parameters, and determine if the coffee beans are ready to used (pass) or not to be used (fail). Our algorithm will be used to define coffee beans that we collect from cafes and instant coffee manufacturers and determine for us whether the coffee beans are good quality or defective.
Benefits of the classification Algorithm:
-Biocafe: Guarantee of getting good quality coffee beans that will further be used in our self-care products -Coffee processing plant: Does not require much manual labor and resources for identifying defective/immature coffee beans
Next step: Our next step to improve our algorithm would be to separate our training and classification code for direct image classification and better efficiency and convenience for our coffee processing plant.
What we learned
- It is quite hard to find raw and clean datasets of coffee beans to train our CNN model
- Convolutional Neural Networks are good for classification because: a. having fewer parameters greatly improves the time it takes to learn b. reduces the amount of data required to train the model
- CNN uses just enough weights to look at a small patch of the image to identify
- CNN is simple as the number of parameters are independent of the size of of the original image
- CNN automatically detects important features without any human supervision. I.e. it learns distinctive features for each class by itself.
What's next for BioCafe
For BioCafe, we will launching our first products by December 15. Meanwhile, we will also be working on our CNN model to develop it further to make it easily perform image processing taken from our Coffee Processing Plant and classify it into two groups.
Members Responsibilities
- Anita Maihom
- Researched possible methodologies to be used
- Onpreeya Dechanatachat
- Explored the possible benefits and challenges of the classification algorithm
- Chia-Han Wu
- Identifying factors and properties determining coffee bean quality
- Bhira Songsaeng
- Compiled datasets and implemented them into algorithm coding
- Back-end development
- Sudev Bhatia
- Acquiring image and .csv file dataset for model training
- Setting the 4 parameters of our algorithm and defining the criteria
- Designing our model's CNN architecture
Link to our presentation
https://docs.google.com/presentation/d/1FobyArPuOoTzfF2yPggeBJsKoQpwlv2O9ydeoOt2Gd4/edit?usp=sharing


Log in or sign up for Devpost to join the conversation.