



Built under 24 hours in HackMIT 2015
Winner of Disney: Best Use of Visual Media
Winner of Kensho: Best mashup of multiple unstructured data sources
Inspiration
The advantage of photography is that it is visual and can transcend language. Images alone have now eaten up over 63% of the internet. While this powerful realization has spawned amazing leaps in statistical data modeling for teachers, researchers, and companies, it has dismissed such tools as almost inapplicable in the daily interactions of the common man. Binoculars break this one-sided conversation by letting the internet talk back. Every image on the internet is transformed into a fully responsive hub for the user, letting them hone complete control over every dimension of the experience.
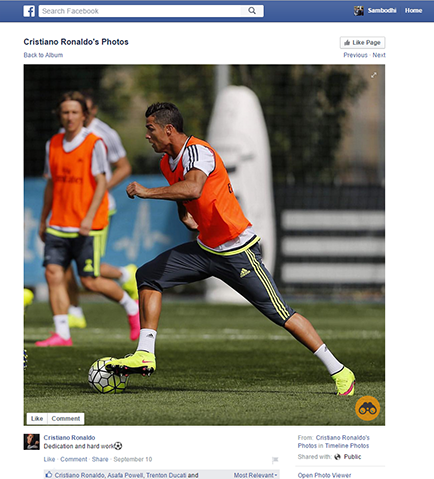
Step One Enable our chrome extension to pull out your pair of binoculars. It will look through all the images on your active tab and place a button in the bottom right of compatible images.
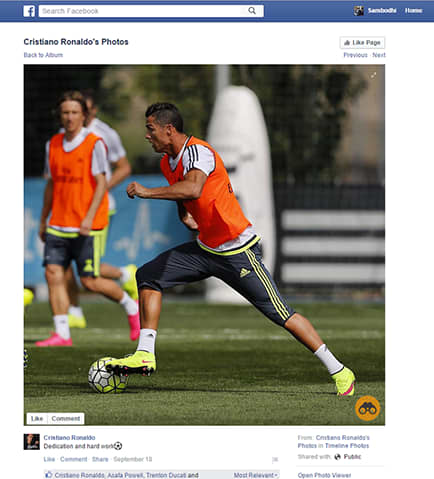
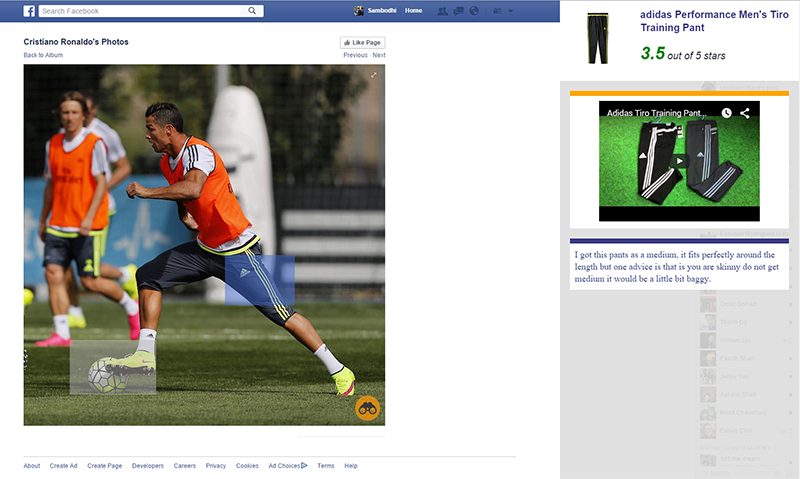
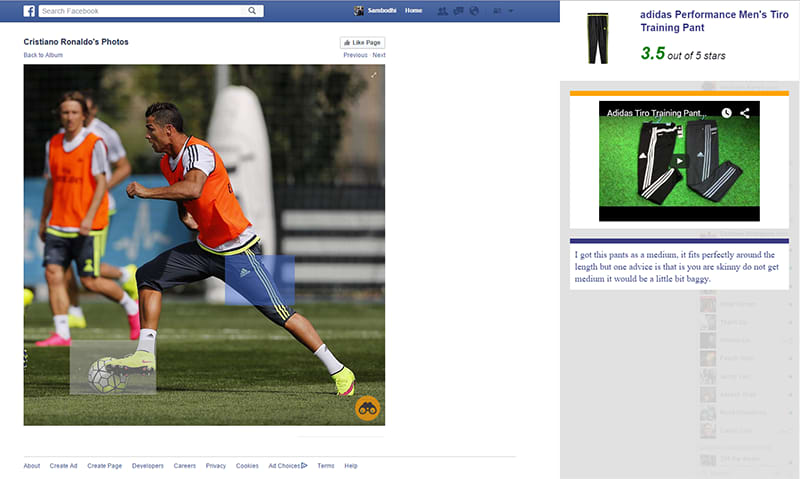
Step Two Press the binocular button on the bottom right of a compatible image. This will transform your image into a responsive hub, showing areas of interest picked up by our algorithm and parsed with our image-recognition machine learning engine.

Step Three Navigate through your responsive image to find any items of interest.
How Did We Make Our Binoculars?
Binoculars depend greatly on Lens, an object detection algorithm we built over this weekend. The algorithm implements segmentation with normalized datapoints, followed by cluster analysis with a mean distribution of distances between consecutive feature points to allow a greater degree of accuracy in object detection, including partially hidden objects. Here is a general overview of what Lens looks like in action.
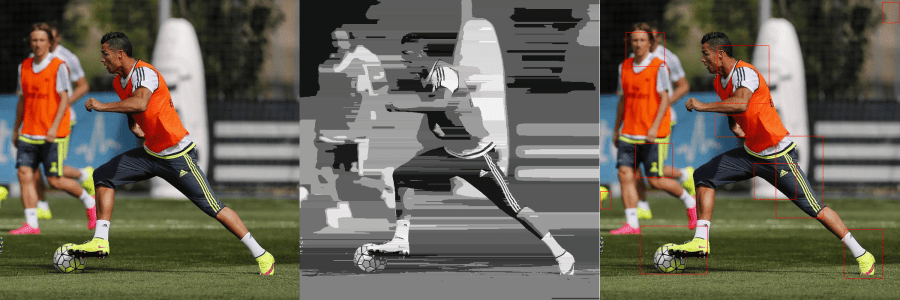
How Did We Focus Our Lens?
Clarifai's amazing API for a low burden and scalable solution in machine learning let us distinguish objects after collecting training data from scraping Amazon's product listing database. This allowed us to get pinpointed, specific data from training our custom machine learning models.
What's Next?
We would love to open up our work to the hacker community to be used as an open-source tool for future projects. The src is extremely messy and inefficient due to the 24-hour time constraint(my CS professor would flip if he saw it), but once we get time to clean up the dirty nooks and crevices we'll throw it up on GitHub.





Log in or sign up for Devpost to join the conversation.