-
-

The logo
-
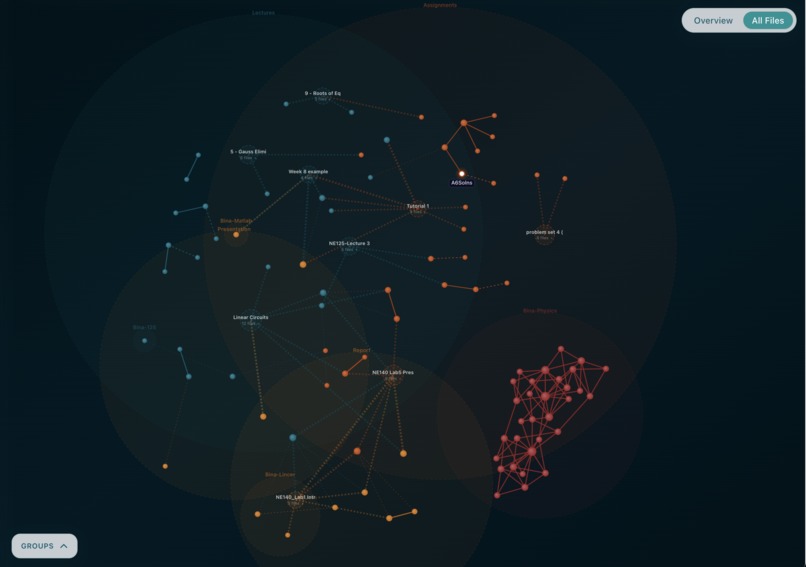
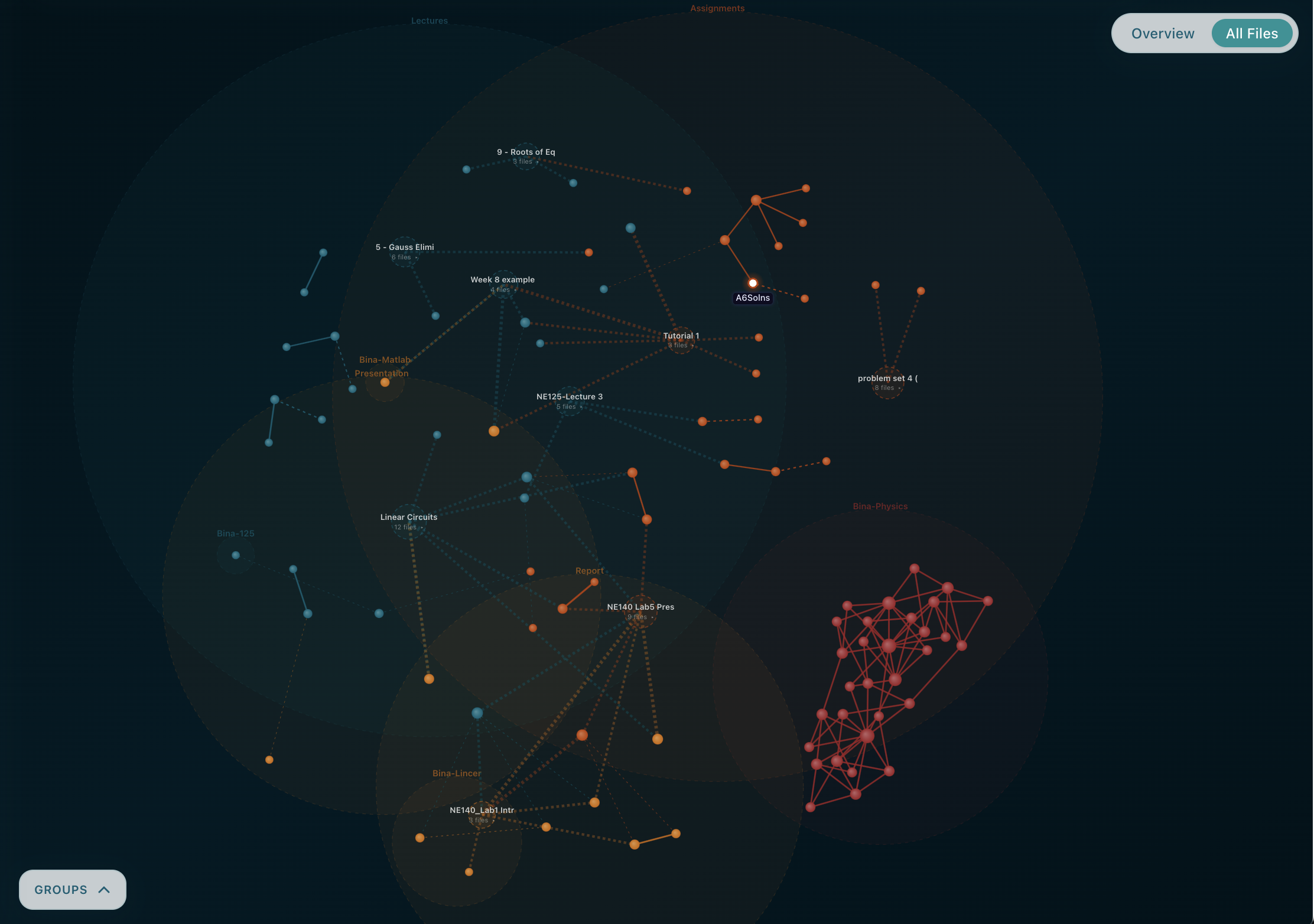
Simple Graph sample
-
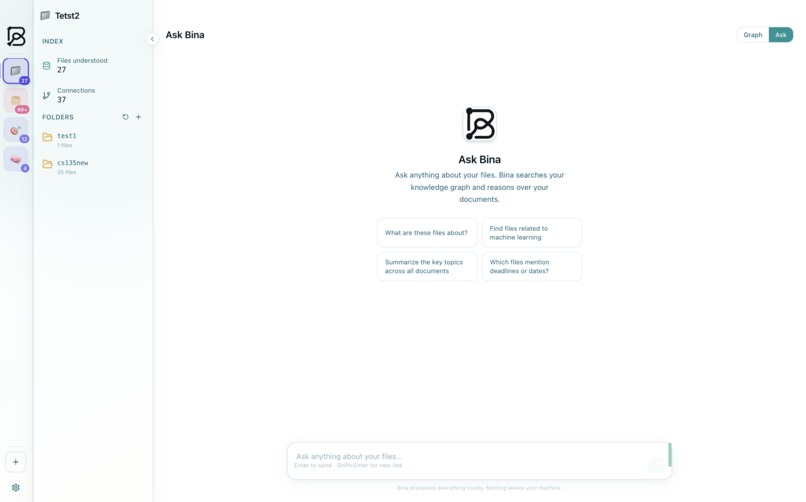
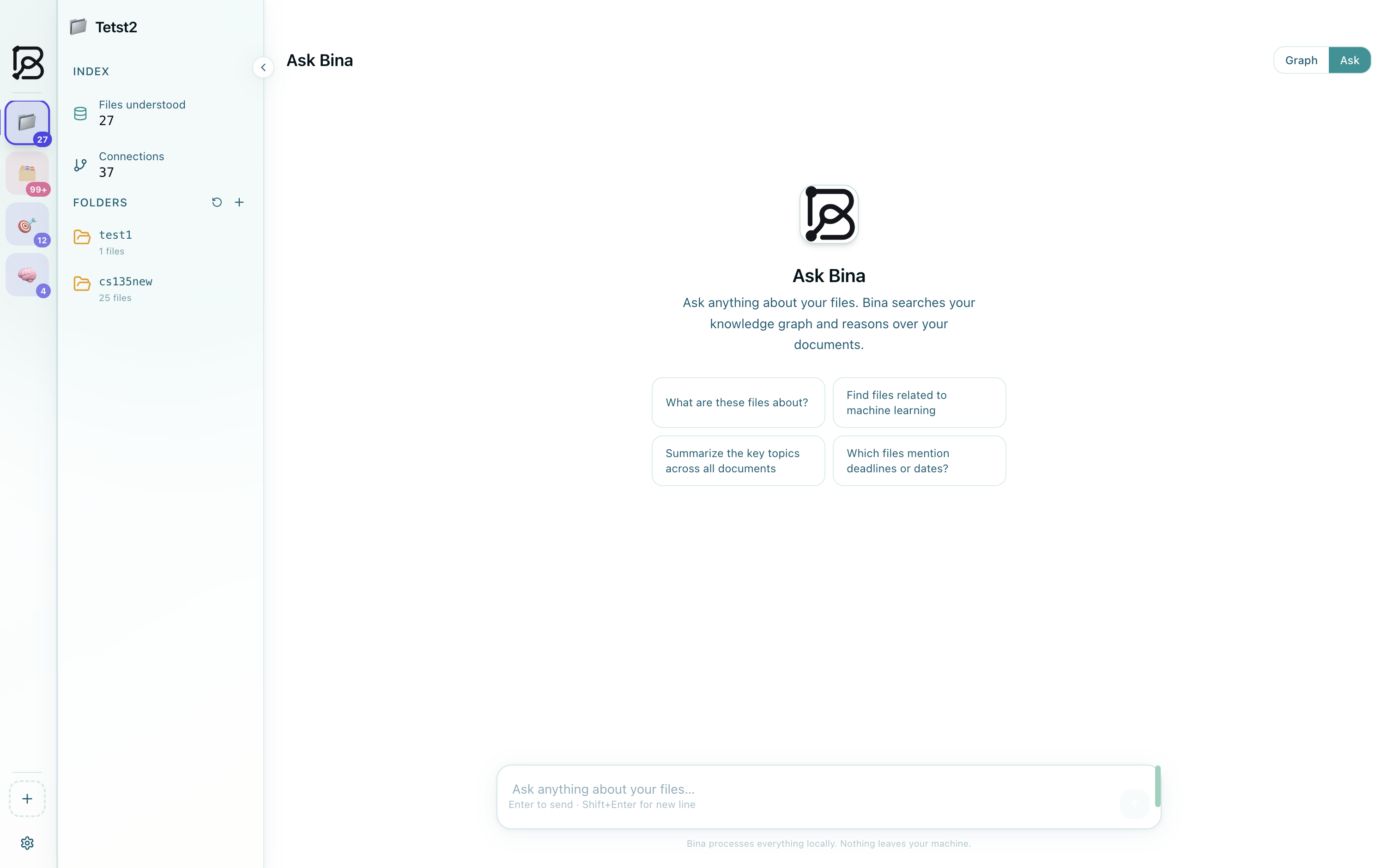
App Dashboard

Inspiration
We've all felt it: you know you have a file about something, but you can't find it. You try every folder, every search term, every variation of the filename you might have used. The file exists. Your memory of its contents is real. But the bridge between the two is broken.
That frustration is what started Bina. We didn't want to build a better file browser or a smarter search bar. We wanted to fix the underlying model entirely. Files shouldn't be isolated objects in a folder hierarchy. They should be nodes in a network of ideas, connected by meaning, explorable like a map of your own thinking.
The name comes from the Farsi philosophical word بینا, meaning "one who sees clearly". Not data retrieval. Not keyword matching. Genuine comprehension of what you've written, saved, and created.
What It Does
Bina is a 100% local-first AI file manager for macOS. Point it at any folder and it reads, understands, and interconnects all your documents into an interactive knowledge graph. PDFs, Word files, text, Markdown, CSVs, and images: every format is extracted into meaning and encoded as a semantic vector. Files that share meaning are drawn together as connected nodes, clustered into colour-coded communities.
When you want to find something, you don't browse. You ask. The Ask Bina chat panel activates a Railtracks reasoning agent that reads your actual documents, follows connections through the graph, and returns a cited answer. Three AI paths are available: a free hosted 120B model, fully local Ollama inference, or your own OpenAI key. Nothing is ever sent to the cloud unless you explicitly choose the hosted path.
How We Built It
The architecture splits into two cooperating layers: an Electron + React frontend handling all interaction, and a FastAPI Python sidecar handling all intelligence.
The indexing pipeline processes every file through five stages: content extraction tailored to file type, smart sampling up to 24,000 characters, LLM-generated structured metadata (summary, keywords, entities, doc type), embedding via nomic-embed-text, and dual-write to both Moorcheh and ChromaDB.
Edge formation uses cosine similarity between embedding vectors. For any two files with embeddings \(\vec{a}\) and \(\vec{b}\):
An edge is drawn if and only if \(\text{similarity}(\vec{a}, \vec{b}) \geq \tau\), where \(\tau = 0.65\) by default. Raw similarity is then boosted by shared named entities:
This ensures that a meeting note and a contract referencing the same project are connected even if their surface text is stylistically dissimilar.
Graph search expands results through the graph topology, discounting neighbour scores to keep direct matches ranked above their relatives:
The Railtracks agent exposes four discrete tool nodes the LLM can call in any order:
semantic_search(query, workspace_id, top_k)
answer_query(query, workspace_id)
summarize_node(node_id, workspace_id)
get_node_neighbors(node_id, workspace_id, depth)
Community detection uses deterministic structural group assignment based on folder name and doc_type rather than Louvain, producing stable human-readable labels like "Lectures" and "Assignments" instead of numeric community IDs that flip on every rebuild.
Deduplication identifies files by MD5 content hash. If two workspaces index the same file, only one FileRecord is stored. Adding a duplicate costs zero AI compute: no re-embedding, no LLM call, just one row inserted into the workspace_files join table.
Challenges We Ran Into
Running everything locally. Getting multiple AI models to coexist on a single machine without memory conflicts required careful orchestration through Ollama. The dynamic context window calculation — \(n_{ctx} = \max(1024, \min(n_{tokens} + 512, 8192))\) — was essential to prevent OOM errors on large documents without wasting memory on small ones.
LLM JSON reliability. Local models, especially qwen3.5 in thinking mode, frequently return malformed JSON wrapped in <think>...</think> blocks, markdown fences, trailing commas, and Python literals. The _repair_json() pipeline handles all of these through a multi-stage fallback: direct parse, regex extraction, and graceful failure — without which the indexing pipeline would crash constantly.
The dual vector store problem. Moorcheh doesn't expose raw embedding vectors by ID. Graph building requires raw vectors for cosine similarity computation. Without a solution, the graph would need to re-embed every file on every rebuild. The fix was to always dual-write to ChromaDB as a local embedding cache, transparently, regardless of which vector backend the workspace uses.
Graph flickering during search. Naive force graph implementations re-render everything on every query, causing the entire layout to jump. Bina separates graph topology (nodes, edges, positions) from search score overlay (node glow, colour intensity). Topology is rebuilt only when node IDs actually change. Scores are patched in-place without restarting the D3 simulation.
The cold start problem. A knowledge graph with three files is unconvincing. The 5-step onboarding, the seed script, and the progress indicator were all designed to ensure the graph felt meaningfully populated before a user committed to the product.
Accomplishments That We're Proud Of
The agent genuinely reasons. Asking a multi-document question and receiving a coherent, cited answer drawn from your own files — running entirely offline — is a qualitatively different experience from keyword search or basic RAG. Getting qwen3.5:2b to produce reliable structured JSON, chain tool calls correctly, and synthesise across documents at acceptable speed on Apple Silicon felt like a real milestone.
True deduplication. The MD5-keyed file_records table means that file identity is content, not path. Rename a file: free. Move it: free. Add it to a second workspace: free. This architectural decision quietly makes the entire product feel faster and more trustworthy than it would otherwise.
Three inference paths from one codebase. The same indexing pipeline, agent, and graph logic runs against a free hosted 120B model, a 2.7 GB local model, or the user's own OpenAI key — switchable per workspace with no code changes. The vector_store_router.py and inference.py abstraction layers made this possible without spaghetti conditionals throughout the codebase.
Crash recovery. On every startup, _resume_unfinished() scans all watched folders and re-processes any file without status='done' in SQLite. Files interrupted mid-index by a force-quit or power outage are silently recovered. Users never lose progress.
What We Learned
The biggest lesson was that deterministic design beats algorithmically correct design for user-facing features. Louvain community detection is theoretically superior for finding clusters. But it produces numeric IDs that change on every rebuild, causing the graph's colours to shuffle every time a file is added. Replacing it with folder-name-based structural groups — \(O(N)\) vs \(O(N \log N)\), stable labels, human-readable — made the graph feel trustworthy for the first time.
We also learned that the embedding content strategy matters more than the model. Prepending the AI-generated summary to the raw text before embedding:
concentrates the vector on semantic meaning rather than surface patterns. A lecture on gradient descent and a problem set asking to minimise a cost function end up adjacent in vector space. Without this, the graph was useful. With it, the graph was surprising.
Building the D3 v7 force simulation on an HTML Canvas (instead of SVG) taught us how much performance headroom the canvas approach opens up — and how much harder hit-testing and pan/zoom become without the DOM's help. Every pointer interaction required manual math that SVG would have handled automatically.
What's Next for Bina
Scanned PDF support. Image-only PDFs with no text layer are currently unsupported. Integrating an OCR pass before the extraction pipeline would unlock a huge category of documents — scanned contracts, handwritten notes photographed as PDFs, legacy archives.
Subgraph zoom. D3 canvas degrades past ~2,000 nodes. A zoom-level-aware renderer that switches from the full graph to a subgraph view at high node counts would make Bina viable for large vaults without sacrificing visual fidelity.
Temporal graph replay. Animating the evolution of the knowledge graph over time — watching \(w_{edge}\) form and clusters emerge across weeks of added files — would let users see how their thinking on a topic developed.
Cross-platform support. The only macOS-specific dependency is watchdog's FSEvents backend. Replacing it with the cross-platform watchdog observer would bring Bina to Windows and Linux with no other changes.
Collaborative workspaces. A lightweight sync layer over the SQLite + Moorcheh stack would allow multiple people to contribute to a shared vault while keeping all local AI inference on each participant's own machine.
Built With
- javascript
- moorcheh
- ollama
- python
- railtracks
- typescript

Log in or sign up for Devpost to join the conversation.