-
-

Logo
-
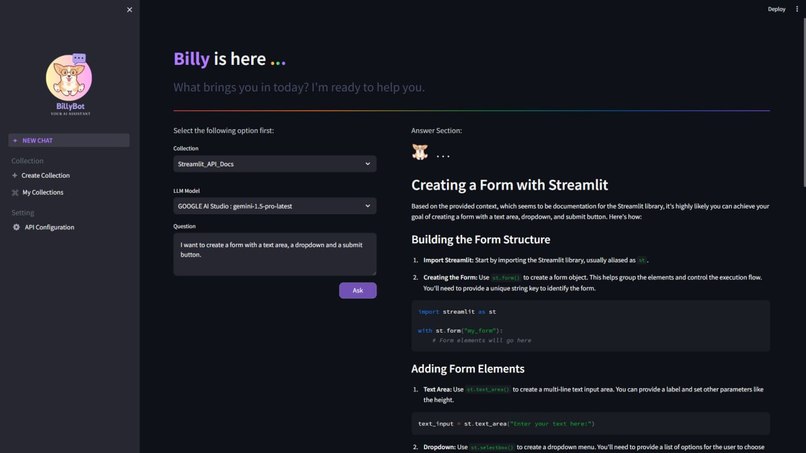
Chat
-
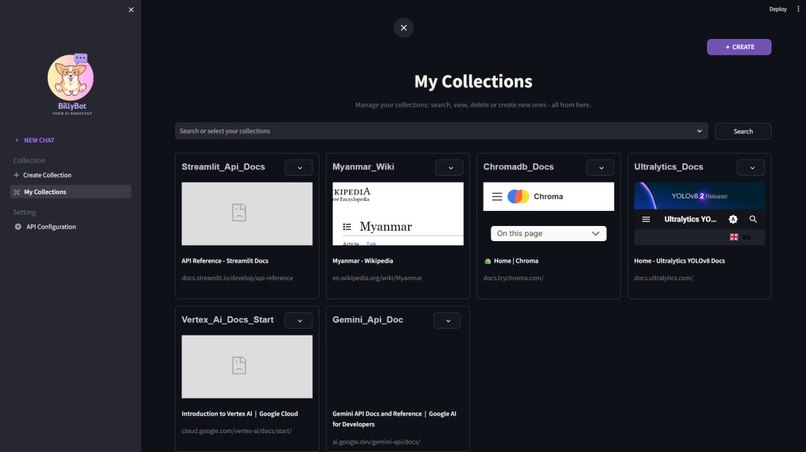
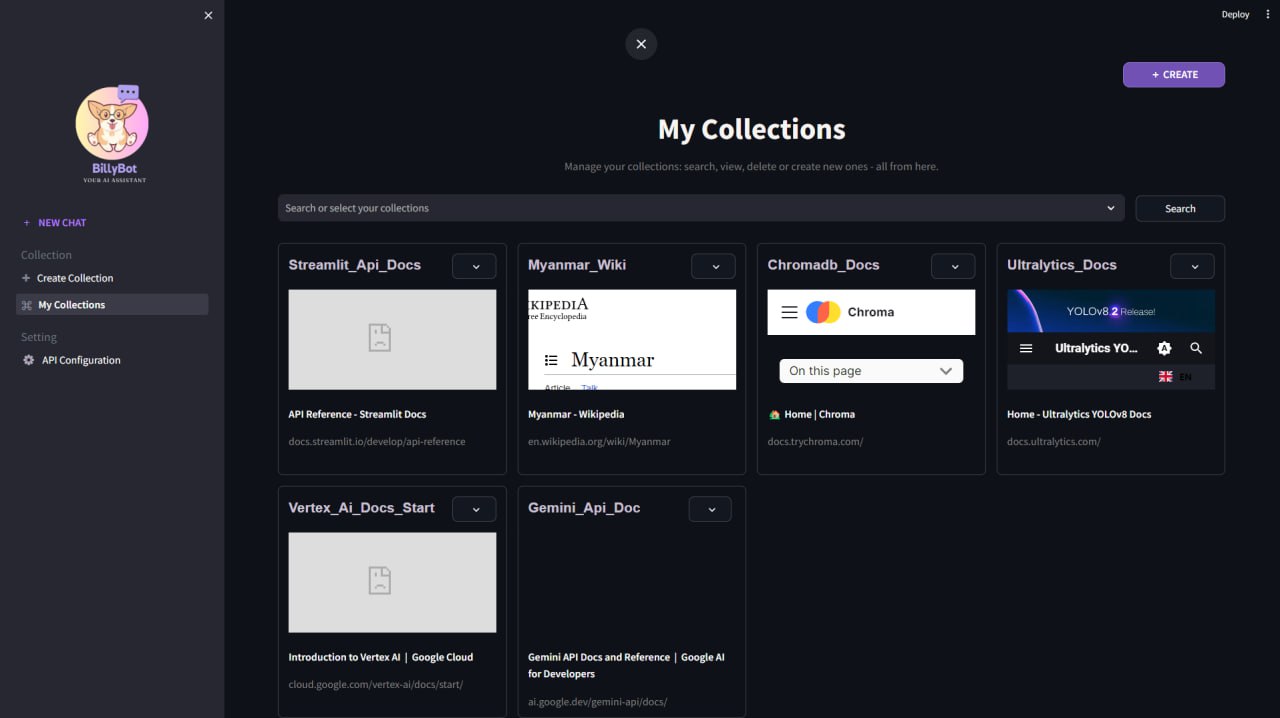
My Collections
-
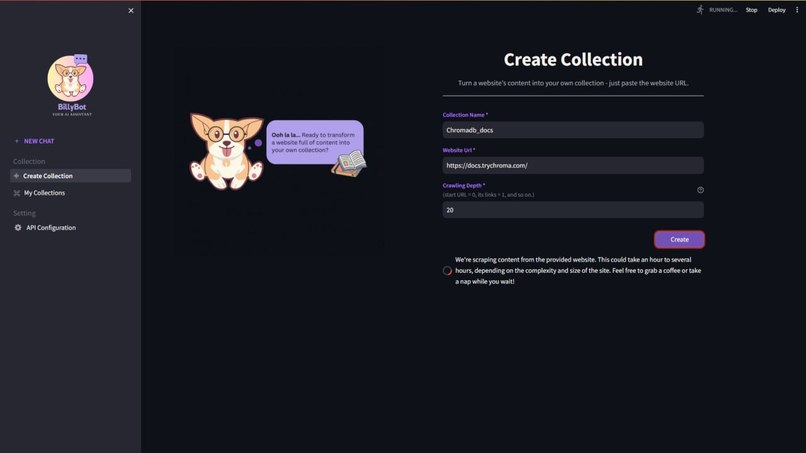
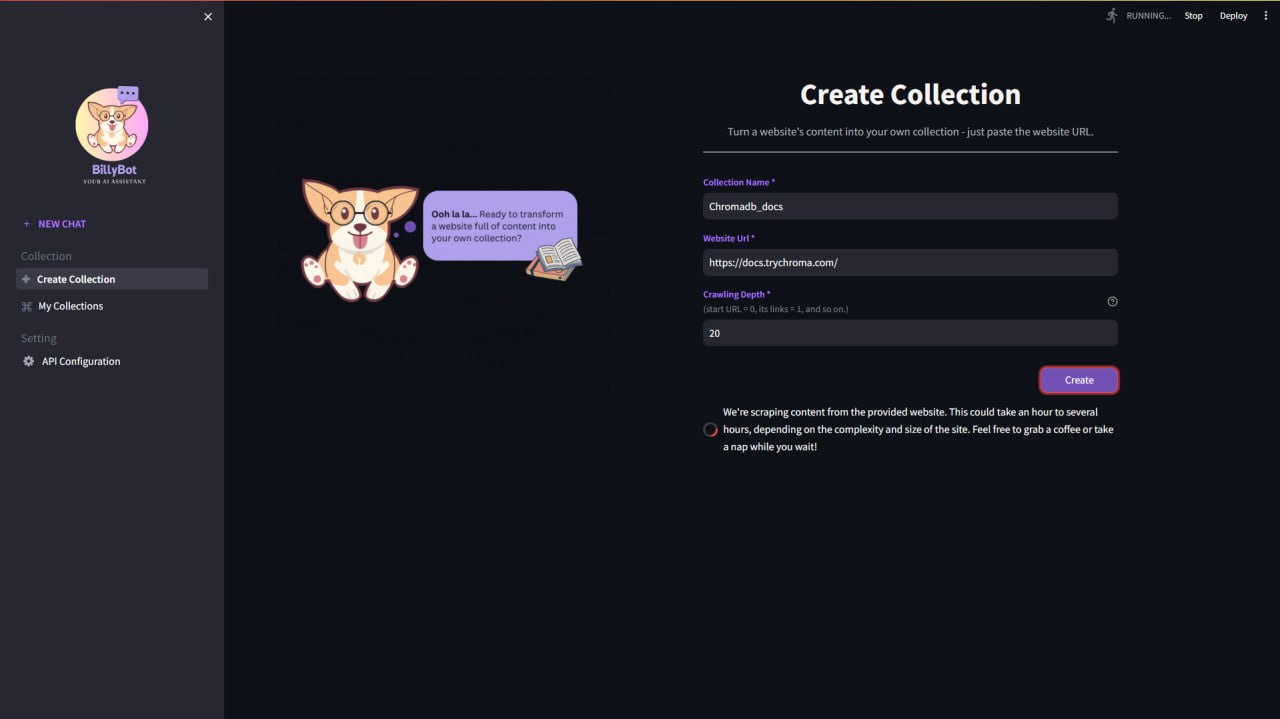
Create Collection

Inspiration
Recognizing the frustration caused by inadequate search tools within official documentation, we envision an AI assistant that revolutionizes information retrieval. Our solution enables the creation of tailored collections from official sources. This facilitates targeted, natural-language queries, empowering users to extract the specific knowledge they seek.
What it does
Our AI assistant empowers users to effortlessly navigate complex official documentation. It curates your selected documentation sources into organized collections within a database. This allows you to search intuitively using natural language questions and receive precise, relevant answers directly from the documentation – streamlining your search process and saving valuable time.
Key Features
- Targeted Web Scraping: Collects and structures content specifically from official documentation websites.
- Document Retrieval: Intelligently retrieves the most relevant sections of your documentation based on your query.
- Contextual Understanding: Processes retrieved information along with your question to generate a tailored response.
- Evidence-Based Answers: Provides answers that are grounded directly in the official documentation you've selected, ensuring reliability and consistency.
How we built it
- Web Scraping: Apify
- Vector Database: ChromaDB
- LLM and Embedding Models: Google AI, Vertex AI
- Frontend: Streamlit
Challenges we ran into
As professionals dedicated to our careers, finding additional time to collaborate and advance this project has been a significant challenge. Initially, one of our primary hurdles was brainstorming a competitive idea. The market is saturated with LLM-based applications, and finding a unique concept proved to be difficult. Additionally, we faced technical challenges during development, particularly with the efficiency of web scraping, as it currently takes an excessive amount of time to process large websites. We are committed to addressing and improving this in future updates.
Accomplishments that we're proud of
Throughout this project, we've achieved something we're truly proud of. We've created a solution that empowers users to overcome the frustrations of navigating complex official documentation.
Key Accomplishments:
- Streamlined Information Retrieval: Our system curates documentation into organized collections, enabling users to easily find relevant information using intuitive natural language queries.
- User-Centric Focus: The emphasis on providing a convenient solution tailored to those who rely on official documentation demonstrates our commitment to solving a real need.
What we learned
We learned how to simplify Gen AI app creation using Vertex AI and Google AI.
What's next for BillyBot
During this period, we successfully completed the initial version of our project. However, we've identified several enhancements and additional features we aim to implement. We plan to categorize collections using tags to improve organization and accessibility. Additionally, we intend to expand support for more models within our app. Currently, scraping webpages for large websites takes several hours, and we are looking into solutions to accelerate this process. Lastly, we’ll try to provide seamless chat experience.

Log in or sign up for Devpost to join the conversation.