-
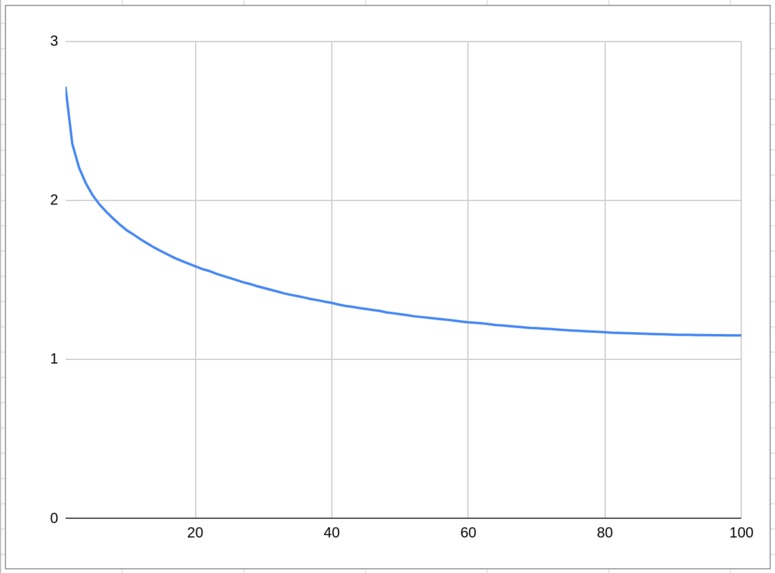
validation loss curve of our model
Inspiration
Legal documents are often exceedingly difficult to parse. Our society is governed by countless laws, yet the language they use is so opaque that most people can't properly understand what they're reading, and must rely on someone else to interpret it for them. Natural Language Processing (NLP) models have become very effective at summarizing documents, but they are often incredibly cumbersome; too large to be run on consumer hardware. We built a tool that uses a lightweight NLP model-- that can be run on nothing more powerful than a laptop-- to digest legal documents, and summarize their salient points, greatly alleviating the task of trying to understand laws and bills as someone unfamiliar with legal vernacular.
What it does
Bill Nom takes a URL from the MN Revisor's Office as input, scrapes it using Beautiful Soup 4 (BS4), digests it with a T5 NLP model implemented in PyTorch, and outputs a condensed summary of the bill's most important points.
How we built it
We scraped several hundred bills and their pre-existing summaries from the MN Revisor's Office-- specifically bills from the 2023 session-- and trained our model to take the language of a bill as input, and output a summary. The bills are scraped using a python script with Beautiful Soup 4 to parse XML into raw strings, inputting them into a NLP model, and output using Plotly's Dash for the front end. To train the model, we used PyTorch in a Jupyter Notebook.
Challenges we ran into
- Generating a sufficiently large data set from the Revisor's Office website, as there is no good way to request a large number of documents at once.
- Training a model that is lightweight enough to run on low-end hardware, yet has good enough loss scores against human-generated targets to truly be effective.
- Building an android app to run the model (unfinished)
Accomplishments that we're proud of
- Web scraping to build our data set of 2000+ newly introduced legal documents, in absence of any API to interface directly with the data.
- Making use of said data to fine-tune a pre-trained transformer model
What we learned
- Common NLP models
- Networking between Android devices (Kotlin), Python, and Java
- Determining targets and conditioned inputs
What's next for Bill Nom
- Take locally-stored legal document files as input and digest them
- Output leyperson-readable rewordings of current summaries



Log in or sign up for Devpost to join the conversation.