-
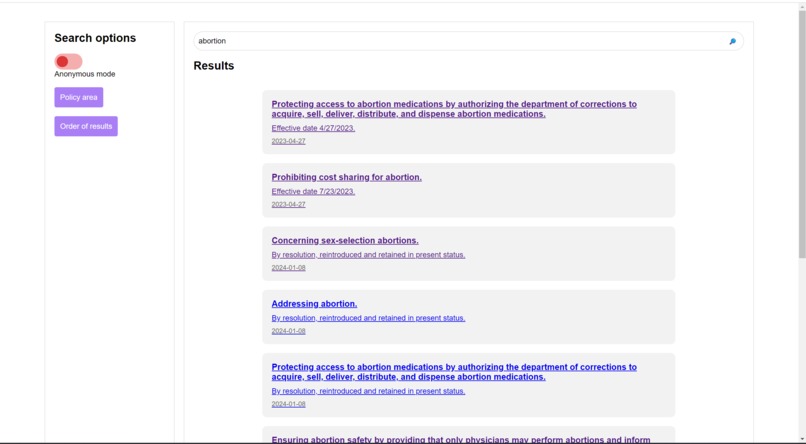
Homepage
-
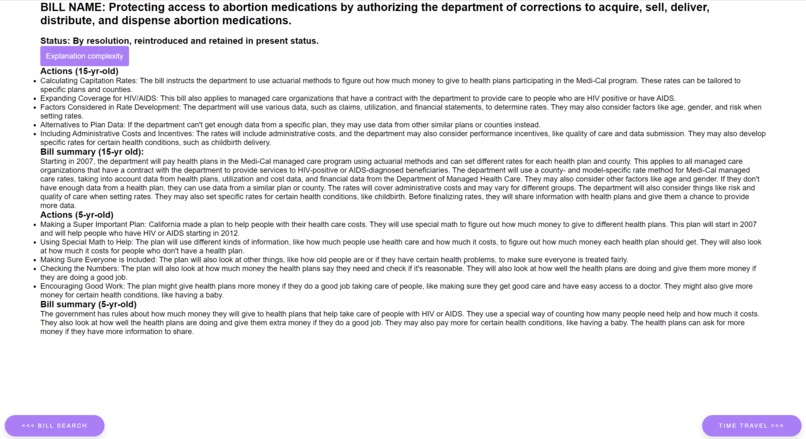
Legislation summarization page
-
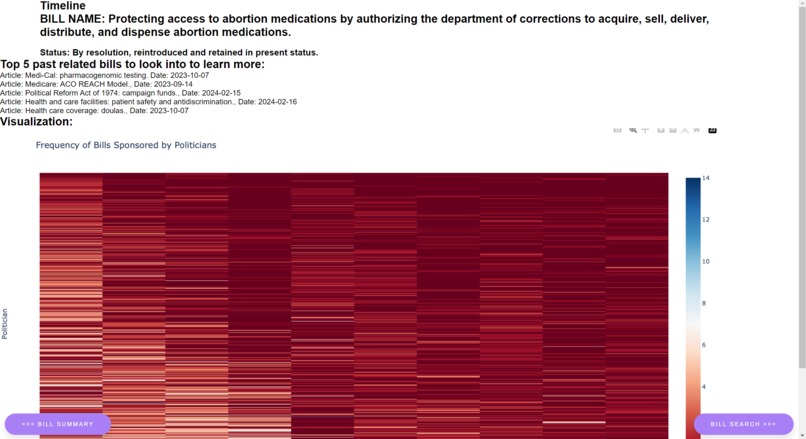
Timeline/Visualizations

Inspiration
All three of our team members spent a considerable amount of time engaging with our local governments (Washington, Illinois, and Indiana) and participating in activities where we spent a lot of time with legislation (debate, mock trial, etc.). Throughout this time, we saw a lot of inaccessibility when it came to understanding and reading legislation; despite years of living and breathing policy, it was so difficult to know where to start when it came to understanding new issue areas and specific policies. And, on top of that, we noticed political bias repeatedly obscuring discussions on bill contents. For the purposes of our debates, as well as our own understanding, we wished there was a way to toggle off identities--in other words, to separate the facts from the rhetoric, and hopefully, much of the bias. We decided to build ourselves, and currently unengaged constituents a solution. billBreak is a form of civic education that presents legislation in a manner that is easier to understand, prettier to look at, less biased, and more accessible than any other currently available tool.
What it does
billBreak increases overall civic literacy by educating users about legislative bills and issues. We do so by explaining bills at a simpler level of complexity and abstracting out political identities to try and create an environment for unpoliticized, policy-first discussions through which citizens can make les rhetorically-polarized decisions about policies. Specifically, we give the user the option to summarize the bills at two different complexity levels: one that summarizes the bill like you are a 5-7-year-old and one that summarizes the bill like you are a 15-17-year-old. Additionally, we include a timeline which displays the top 5 bills most relevant to the original bill to establish the context for the legislation. We also created a visualization of the bias in legislation and hope to create more visualizations to better understand political bias in bills in different categories.
How we built it
Frontend:
- HTML
- CSS
- Jinjas
Backend:
- Flask
- Python
- LegiScan API
Machine Learning and Data Visualization:
- Python
- OpenAI
- Sckicit-Learn
- Numpy
- BERT
Deployment:
- Git
Challenges we ran into
We ran into errors when integrating. Specifically, some of the code was not the most recent version on the GitHub for some of our team members. Thus, we were not able to launch the right app on some of our devices. Additionally, we had issues with dependencies and installation.
Accomplishments that we're proud of
We are proud that we made the basis of the frontend. We are also proud of how we got a good NLP model working that was able to summarize bills accurately. Lastly, we are proud of how much we learned and accomplished during this time.
What we learned
This was the first hackathon of two of our team members-- so, we learned a lot! Specifically, different members of our team learned different skills. Tia learned how to create data visualization and use Flask, Siya learned how to vectorize and create cosine similarity scores, and Medhya learned how to use the LegiScan API and integrate generative AI. This process also helped us understand how to manage our time when making a project in a short timeline and how to break the project down effectively.
What's next for billBreakdown
We plan to continue fleshing out and adding more features to billBreakdown. Specifically, we would like to create more visuals to understand how bills relate to another. We also would like to create a summary of all the comments the senators have made on the bills. We'd also like to explore the addition of user interactivity (perhaps with forums for political discussions, accounts and the ability to save interesting bills). There is potential for billBreakdown usage data to benefit social scientists who are studying policy-based voting by creating an environment where we attempt to control for polarization. Lastly, we want to improve the AI we used to find similar bills by developing more sophisticated models, like RoBERTa, to see if we can improve on our current cosine similarity metric.
Built With
- flask
- html
- javascript
- legiscan
- openai
- python
- sckit

Log in or sign up for Devpost to join the conversation.