Project Story
Inspiration
I'm a French speaker. My English is decent I understand most things but there's a difference between understanding and being yourself.
Every pitch meeting, every client call, every conference abroad: I was performing. Not selling. Not connecting. Performing. Translating in my head, second-guessing every word, missing the rhythm of the conversation. While my English-speaking competitors were freestyling, I was processing.
I tried every translation tool on the market. They all work the same way: you talk, you wait, it translates, the other person waits, they respond, you wait again. By the time the tool finishes, the conversation is dead. Good luck closing a deal with a 3-second lag after every sentence.
What I wanted didn't exist: a live agent that sits inside the conversation not after it. Something that translates my voice as I speak, so smoothly that the person on the other end doesn't even realize I'm not speaking their language natively. Something that lets me be me my energy, my humor, my sales instincts in any language.
When Amazon announced Nova Sonic with native speech-to-speech capabilities and tooling support, I saw the opportunity to build exactly that leveraging the ultra-low latency of Nova Sonic's bidirectional audio streaming to create a real-time translation layer that feels invisible.
So I built Bijou (NOVA GUARD).
What it does
Bijou is a real-time AI live agent powered by Amazon Nova Sonic (voice) + Nova Lite (vision) that translates your voice, analyzes your screen, and coaches you all during the conversation, not after.
🗣️ al-time voice translation I speak French, my client in Tokyo hears Japanese. My client in Madrid hears Spanish. 21+ languages including Wolof, Arabic, Mandarin, Portuguese. Nova Sonic's native speech-to-speech means no separate STT→LLM→TTS pipeline. One model. One hop. Minimal latency. Just conversation.
👁️ Livecreen analysis NOVA GUA sees what's on screen via Nova Lite vision sidecar. Share your AWS console during a client call? She detects misconfigurations, flags compliance gaps, generates production-ready Terraform remediation code. In a terminal overlay. Deployable, not pseudocode.
🕵️ Stealth annel While you'repeaking publicly, NOVA GUARD simultaneously whispers tactical intelligence only to your screen. "Client claims SOC2 compliance. Screen shows unencrypted RDS instance flag this." Your client never sees it. Zero tells.
📊 Smart pitch dk Slides change aumatically based on conversation context. Client asks about architecture → the right slide appears. No manual clicking.
✉️ Instant post-meetg Click Stop → summaryaction items with assignees and deadlines, follow-up email ready to send. Before the client closes their laptop.
The real endgame? I'm turning NOVA GUARD into a universal translator for:
- Video conferences Zoom,eet, Teams NOVA ARD joins as your live translation layer
- Earbuds for pitches real-ti whispered translatn directly in your ear during in-person meetings
- Travel airports, hotels, restaunts slanguage stops being a barrier and everyone can truly be themselves and be understood
How we built it
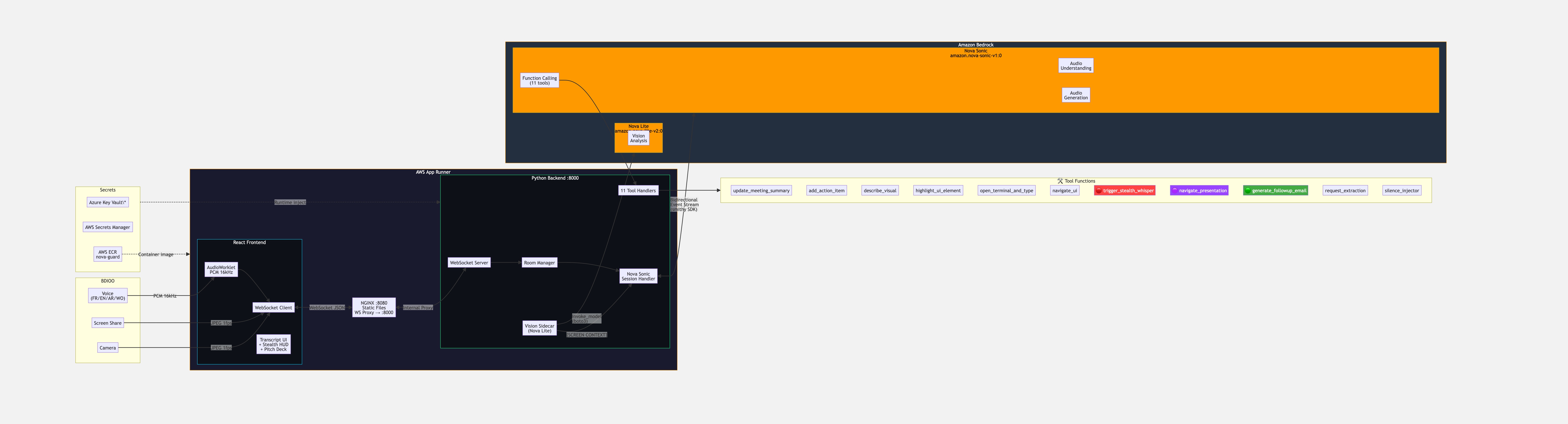
Architecture: React → AudioWorklet →ebSocket → Python asyncio → Amazon Nova Sonic (voice) + Nova Lite (vision) → 11 Tool Functions → dual-channel response
- Audio Capture: Custom
pcm-procesr.jsudioWorklet eodes directly to 16-bit PCM at 16kHz not the standardgetUserMediawith its buffering lag - Video Capture: Screen/camera frames at 1 FPSs JPEG, sent ongside audio via WebSocket
- Backend Bridge: Python asyncio WebSocket server idges the browr to the Nova Sonic bidirectional streaming API via the
aws-sdk-bedrock-runtimeSDK (smithy-based, not boto3) - Amazon Nova Sonic (
amazon.nova-sonic-v1:0): Nativepeech-to-speech birectional streaming. Audio frames in → audio+text+tool calls out. No separate STT/TTS pipeline. - Amazon Nova Lite (
amazon.nova-lite-v2:0): Vision sidec that analyzes seen captures (JPEG) and feeds context back into the voice session as[SCREEN CONTEXT]messages - 11 Tool Functions: Each triggers a specific frontend action ighlight vulnerabity, generate code, change slide, write email, stealth whisper)
- Dual-channel routing:
triggerstealthwhisperroutes to host's WSocket ONLY never badcast - NGINX: Reverse proxy + WebSocket upgrade + static file serving in a ngle ntainer
- AWS App Runner / ECR: Containerized deployment with secrets from Azure K Vault + AWS Secretsanager
- Event-based protocol: Nova Sonic uses JSON event streams (
sessionStart,ctentStart,audioInt,toolResult, etc.) completely different from REST APIs
Wire protocol (typed JSON over WebSocket):
bijouresponse→ transcript + tranated audiostealthalert→ private whisr to host onlyuihighlight→ red bounding box on detected vulnerabilityuiterminal→ terminal overlay with typewriter code animationslidechange→ auto-navigate presentationfollowupemail→ post-meeting emailsummaryupdate/actionitem→ live intelligence panel
Challenges we ran into
Nova Sonic SDK is NOT boto3 The biggest surprise. Amazon Nova Sonic uses
aws-sdbedrock-runtimea smithy-bas Python SDK that's completely separate from boto3. The API is event-based with bidirectional streams, not request/response. Required learning an entirely new SDK ecosystem (smithy-core,smithy-aws-core).Event-based streaming protocol Nova Sonic communicates through structured JSON event(
sessionStart,contentStart, udioInput,textInput,toolResult,sessionEnd`). Each event has specific fields and ordering requirements. Getting the event sequencing right especially for tool calls interrupted by audio was the hardest engineering challenge.Dual-model orchestration Nova Sonic handles voice but doesn't natively process images. Blding a vision sidecar withova Lite that captures screen frames, analyzes them, and injects context back into the voice session as text events required careful async coordination to avoid blocking the audio stream.
Stealth channel isolation The dual-channel guarantee means stealth whispers MUST route only the host's WebSocket. Implenting per-role routing inside the room manager while keeping generic fan-out for everything else required careful session state design.
AudioWorklet latency Standard
getUserMediaintroduces 200-400ms of startup lag. Building a cusm AudioWorklet that ences PCM directly and sends synchronous chunks via WebSocket brought latency under 200ms.Staying focused on the human problem The hardest challenge was resisting the urge to build another cersecurity tool and remembering why I srted: I just wanted to stop feeling like a foreigner in my own meetings.
Accomplishments that we're proud of
- Nova Sonic speech-to-speech eliminates the traditional STT→LLM→TTS pipeline one model, one hop, lower latency
- The stealth channel works flawlessly NOVA GUARD detects a claim, flags it privately, I pivot the conversation naturally
- Dual-model architecture (Sonic + Lite) provides both voice AND vision in real-time
- All 11 tools work coherently in a live session without conflicts
- Post-meeting email is ready before the call disconnects
- Built and deployed a production multimodal live agent using Amazon's newest models
- My mom tested it. She spoke Wolof. The client heard English. She cried.
What we learned
- Amazon Nova Sonic is a paradigm shift native speech-to-speech streaming means you're not chaining services, you're having a conversation with a model that natively understands and produces voice
- The smithy-based SDK is powerful but requires learning a new mental model vs. traditional boto3
- Vision doesn't need to be real-time 1 FPS is enough for Nova Lite to detect misconfigurations on screen
- Event ordering in bidirectional streams is everything one out-of-sequence event and the session breaks
- The best technology disappears. When the translation is fast enough, you forget it's there. That's when you start being yourself again.
What's next for NOVA GUARD
- Earbuds integration Bluetooth earpiece for in-person pitches with real-time whispered translation
- Conferee mode Multi-partipant rooms where everyone speaks their native language and hears theirs
- Video coerence plugins oom, Google Meet, Teams integration as a translation layer
- Travel mode Lightweight mobe version for airports, tels, restaurants
- More languages Expanding beyond 21 to coververy langua where someone feels limited by translation
- Voice cloning with va Your transted voice sounds like you, not a robot
- Amazon Bedrock Agents integration Full agentic woflows with guardrails
Built With
- amazon.nova-lite-v2:0
- amazon.nova-sonic-v1:0
- app
- aws-sdk-bedrock-runtime
- docker
- ecr
- python
- react
- runner
- tailwind
- typescript
- vault


Log in or sign up for Devpost to join the conversation.