-
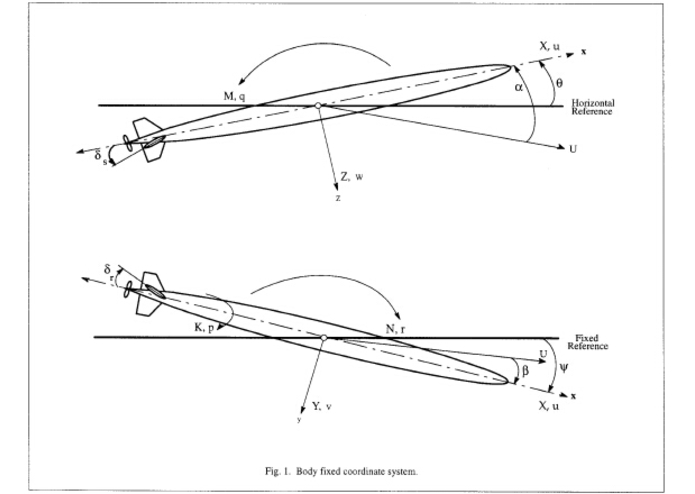
body fixed coordinate system
-
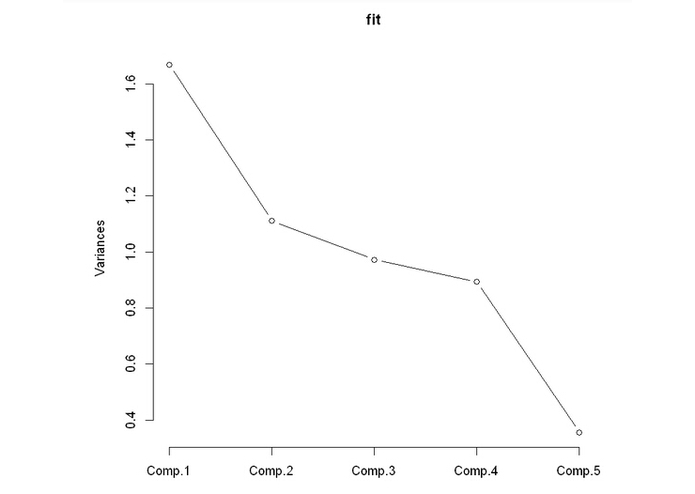
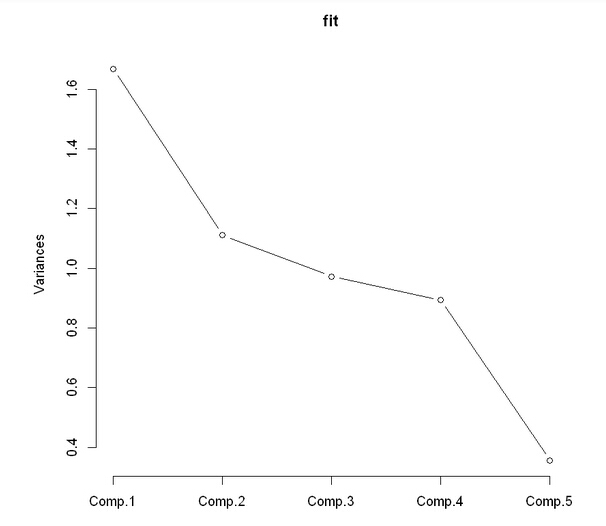
components in PCA based on variance
-
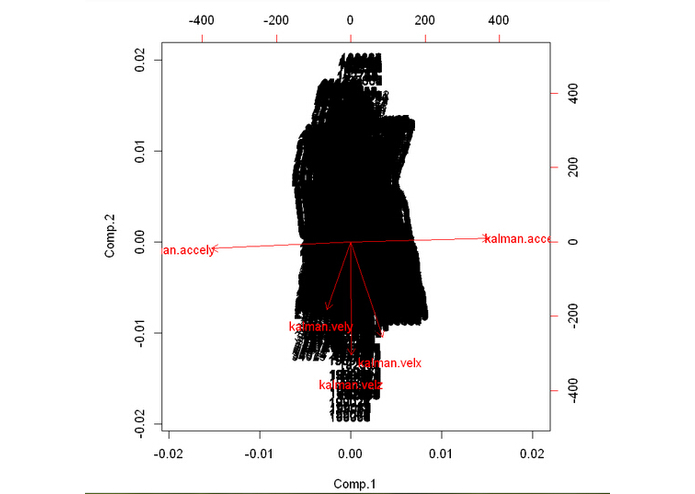
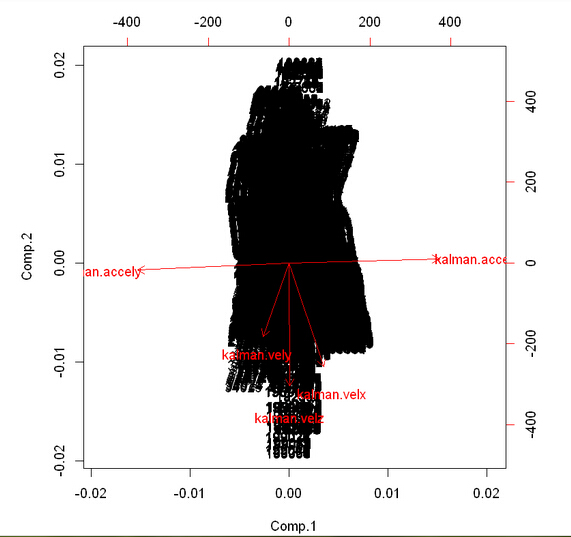
bipot of different components in PCA
Inspiration
For an autonomous vehicle, failure detection and identification are crucial to enable the vehicle to complete its mission successfully. Failure is usually detected through the heading and depth control surfaces and sensors. Data from various sensors are used to determine: 1) whether a failure has occurred, 2) what component has failed, and, if possible, 3) how the component failed. The five sensed values, namely depth, pitch (inclinometer), angle, angle of sideslip, and heading (magnetic compass), are used to check for failures. The challenge is to identify anomalousness in the massive sensor inputs. We will use the redundancy management technique as the failure detection method and use R to analyze the data selected.
Understand failure detection methods
Coordinate systems When analyzing the motions of AUVs, we consider three coordinate systems. The first is an inertial system fixed to earth; the second one is fixed to water current; the third is a body fixed frame with the center at the geometric center of AUV, the positive x axis pointing forward and positive z axis pointing downward. As for failure detection, we only consider the third type of coordinate system because it is the most related to the behavior of the AUV.
Sensed values Directions of up and down are used for depth control. A positive angle of attack also indicates a climb and is given the direction up. The orientation of the body frame with respect to the inertial frame is defined by the roll, pitch and yaw of the AUV. Both heading angle and sideslip angle correspond to directions about left and right.
Redundancy management to detect failure Applying redundancy management, we will compare two independently determined values of a single quantity (e.g. the depth value obtained by sensor and by camera, the depth rate calculated from depth sensor and from the combination of forward velocity, roll angle, pitch angle, yaw angle, angle of attack and angle of sideslip). If there is a significant different between the values, a (full deflection) failure is indicated.
Select useful data
First of all, we looked at the folder of CUAUV dataset. There are two csv files and all the rest are video files. The videos show the the actual situation underwater as well as the sight of targets. They are more useful for location and object classification. The two csv files contain data from sensor and from camera as well as the timestamp. Besides data about speed, acceleration, depth, pitch, etc. in the file “shmlog-minimal.csv”, the file “shmlog.csv” includes more information about the buoys. Since the challenge of failure detection will mainly use data from sensor and camera,, we did not need the video files and extra variables in “shmlog.csv” at all, but just focused on the file “shmlog-minimal.csv”. Also, we saw that some columns of data were not relevant to us, and we just extracted out the columns we thought were useful to detect failures using the five sensed values: depth, pitch, angle, angle of sideslip, and heading. We then generated the trimmed file “shmlog-raw.csv”, and further select the useful columns in each of the three tentative solutions stated below.
Develop solutions
We attemp three different approaches to develop the solutions by using decision tree, liner regression model and principle component analysis. We will further explain the validity of each solution.
Decision Tree We approach failure diagnosis through Decision Tree, which is a learning method used for classification and regression. The goal is to create a model that predicts the value of a target variable by learning decision rules inferred from the data features.
1)Reasons for choosing Decision Tree to approach failure detection:
· It can be used to find the boundary where failure starts to occur, and identify which factors may cause such failure.
· It yields results that are easy for people to understand and interpret, which is important for CUAUV members.
· It requires little data preparation, i.e, we don’t need to normalize different kinds of inputs or create dummy variables for our data manipulation.
· It is able to handle big data.
2)Application of Decision Tree to failure detection:
· Extracting factors leading to component failure: When detecting the failures, we treat the problem as one that finds components that are correlated with failure. More specifically, we train a decision tree to classify the failed and successful sensor inputs that occurred during certain time interval. We then process the paths that lead to failure-predicting nodes and extract relevant components.
· Identifying potential deviations from the path planned: In order to distinguish potential deviations, we want to manually introduce an error input that has a huge deflection from the other data in the same category. The representation of this error in the decision tree helps us understand how much deflection is allowed to avoid failure detection. By decreasing the value of the error input, we will finally be able to determine the boundary values at which a failure is detected. Therefore in the future, if any input goes over that value, we may report a potential deviation.
· Identifying new rules for failure detection and identification: With the decision tree model and the failure boundary specified above, we can import the dataset to be processed, run the decision tree model, look for the inputs whose values go beyond the failure boundary, and detect potential failure.
Linear Regression Model We attempted the relatively easy method: linear regression model. We tried to construct a linear regression model for each of the five values detected by the sensor. We only tried to construct a linear model of pitch with other variables, such as karlman.velz/karlman.vely. However, the slope of pitch with respect to the velocity tangent is so small that it does not contribute to the prediction of pitch much. At the end, we did not manage to find a satisfying linear model with a large enough r-squared value. While we were not too familiar with R and other regression techniques, such as logistic regression, we gave up on this method.
Principle Component Analysis A possible approach to identify the factors is through principle component analysis (PCA), which takes the possibly correlated variables and outputs linearly uncorrelated variables by using certain transformation. The first component in PCA is related to the largest eigenvalue of a matrix whose rows represent different repetitions of experiment (i.e. data under each timestamp in this case) and columns are the particular kinds of features. We directly use the princomp() in R on five vectors, kalman.velx, kalman.vely, kalman.velz, kalman.accely and kalman.accelx. The proportion and biplot show the relations between components in PCA and the five vectors. According to the plots, we can conclude that in the hyper-dimension coordinates with each feature as axis, data is more likely to follow the direction of kalman.accely and kalman.accelx. Therefore, if there is a significant deviation away from that direction in certain data of the five sensed values, we can say that it is likely to have a failure.
Technical story
During hackathon, the biggest challenge for us was to find out which models to use to interpret the relevant data for failure detection and realize failure identification. More specifically, by studying the meanings and effects of the five sensed values that check for failure, we decided to compare the actual values obtained by camera and the values of kalman inputs from the sensors. But we were not sure how to implement the comparison. We researched some failure detection methods, such as counting aberrations, consistency checks, defining tolerances, but none of them provides comprehensive formulation of the problem. We also brainstormed possible approaches to handle failure detection with mentors and eventually got some inspirations. In the end, we decided to implement the comparison of the data through three different models: Decision Tree, Linear Regression model, and PCA. We made such decision because we would like to see how the results of these three different models differ from each other, and what we can learn from such differences. Even though this hackathon was indeed a challenge to us because we were not very familiar with machine learning, we were able to pick up multiples approaches to the challenge within hours. We enjoyed the experience of "learning while using" a lot.
Business story
The field of autonomous underwater vehicle has a huge economic potential. The market for autonomous underwater vehicles (AUVs) is expected to grow from USD 211.8 Million in 2016 to USD 497.9 Million by 2022, at a CAGR of 15.31% between 2016 and 2022. The U.S. Navy has proposed about $319 million for the development and purchase of underwater drones in the president’s budget for the coming fiscal year. It envisions them stealthily gathering intelligence on opponents, detecting and neutralizing mines, hunting submarines and charting the ocean floor. Failure detection and prediction play an important part in enabling the AUVs to function and accomplish the mission. Therefore, the new approach to detect failure using redundancy management with five sensed values will increase the functionality of AUVs with great market potential.
Reference
Orrick A., McDermott M., Barnett D.M., Nelson E.L., Williams G.N., Failure Detection in an Autonomous Underwater Vehicle, Retrieved from http://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=518650
Masunage S., (2016 Aug), Say hello to underwater drones: The Pentagon is looking to extend its robot fighting forces. Los Angeles Time. Retrieved from http://www.latimes.com/business/la-fi-adv-underwater-drones-20160722-snap-story.html
")
Log in or sign up for Devpost to join the conversation.