-
-

LANDING PAGE
-
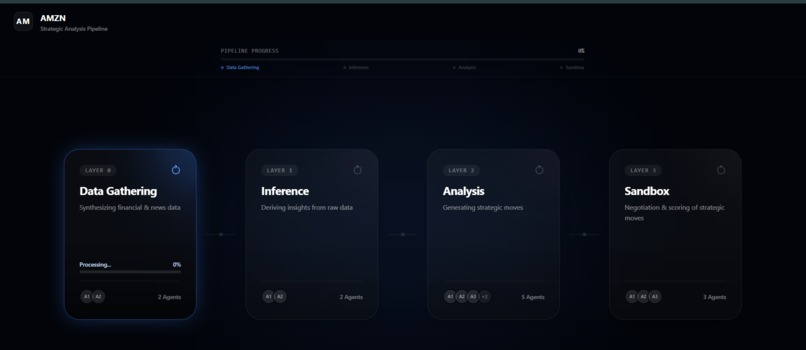
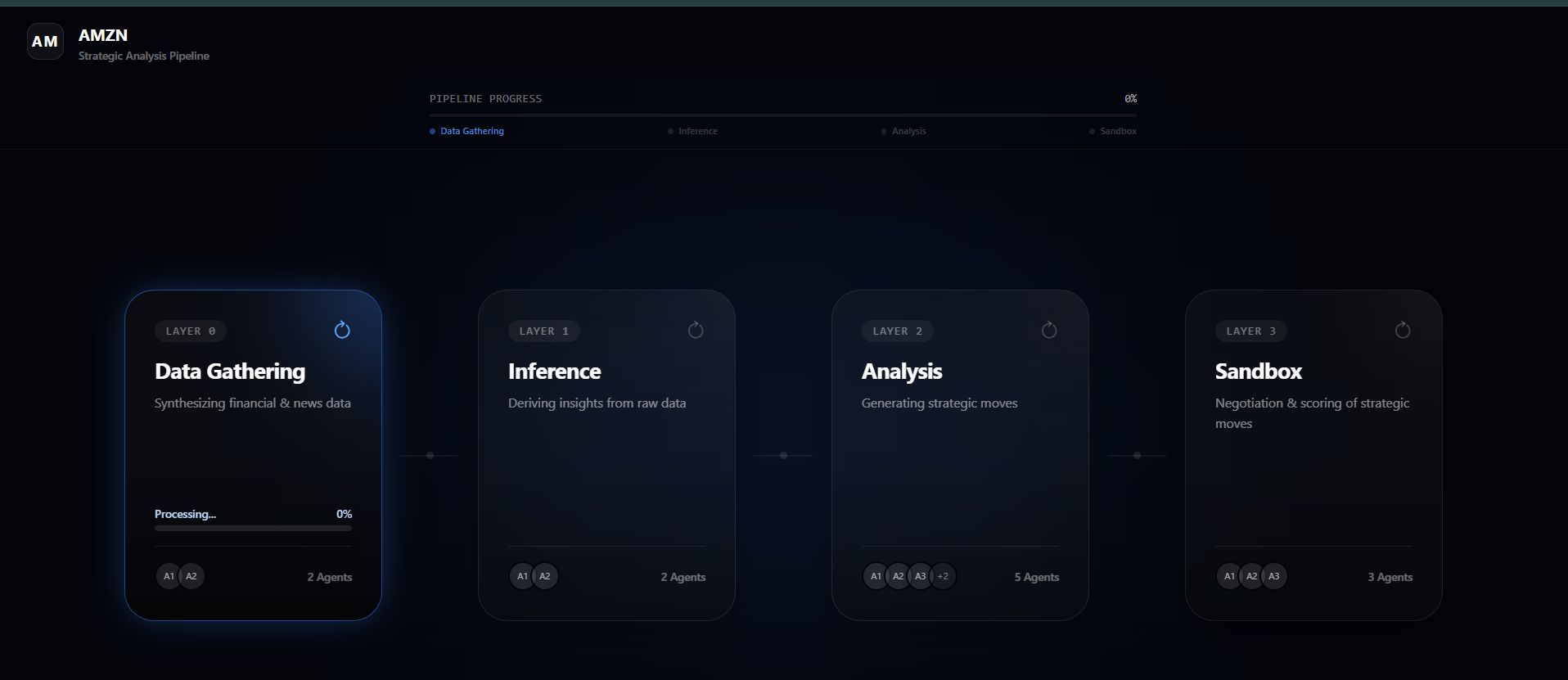
ANALYSIS BEGINS
-
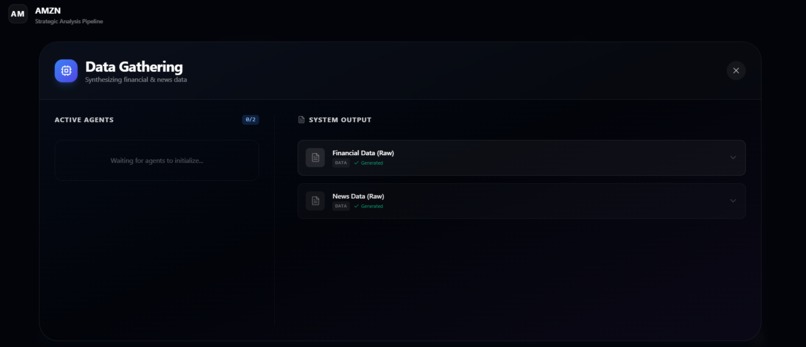
DATA GATHERED
-
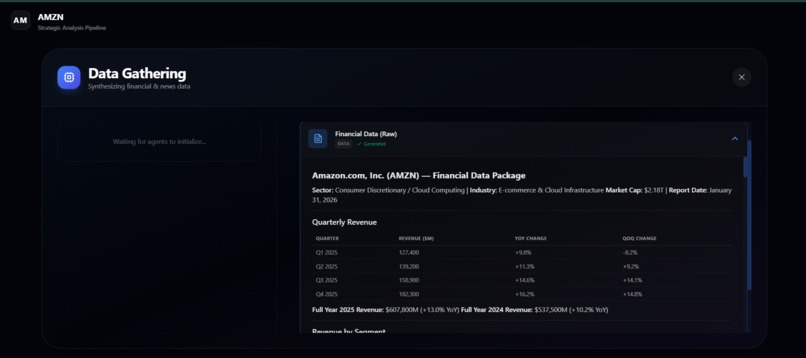
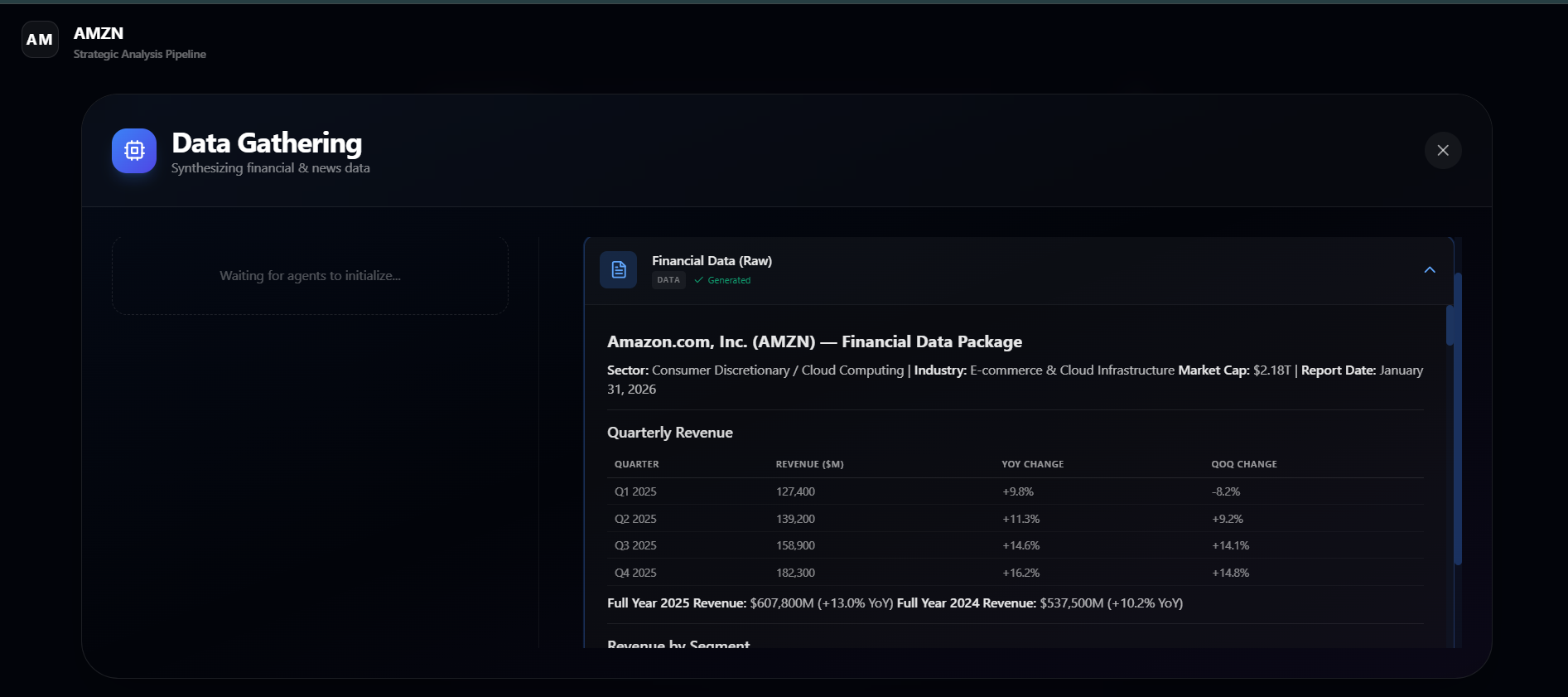
DATA GATHERING IN DETAIL
-
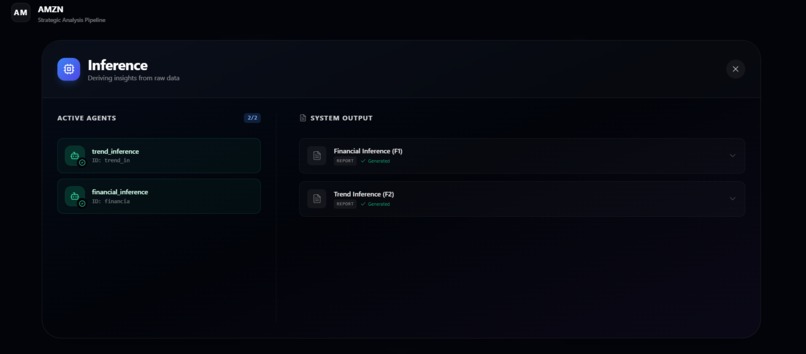
INFERENCE DOCS
-
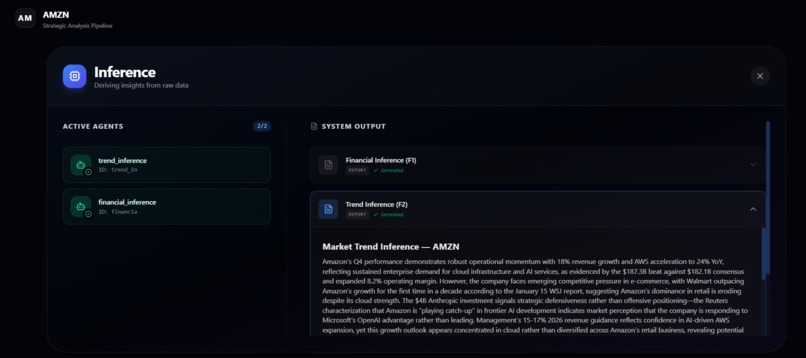
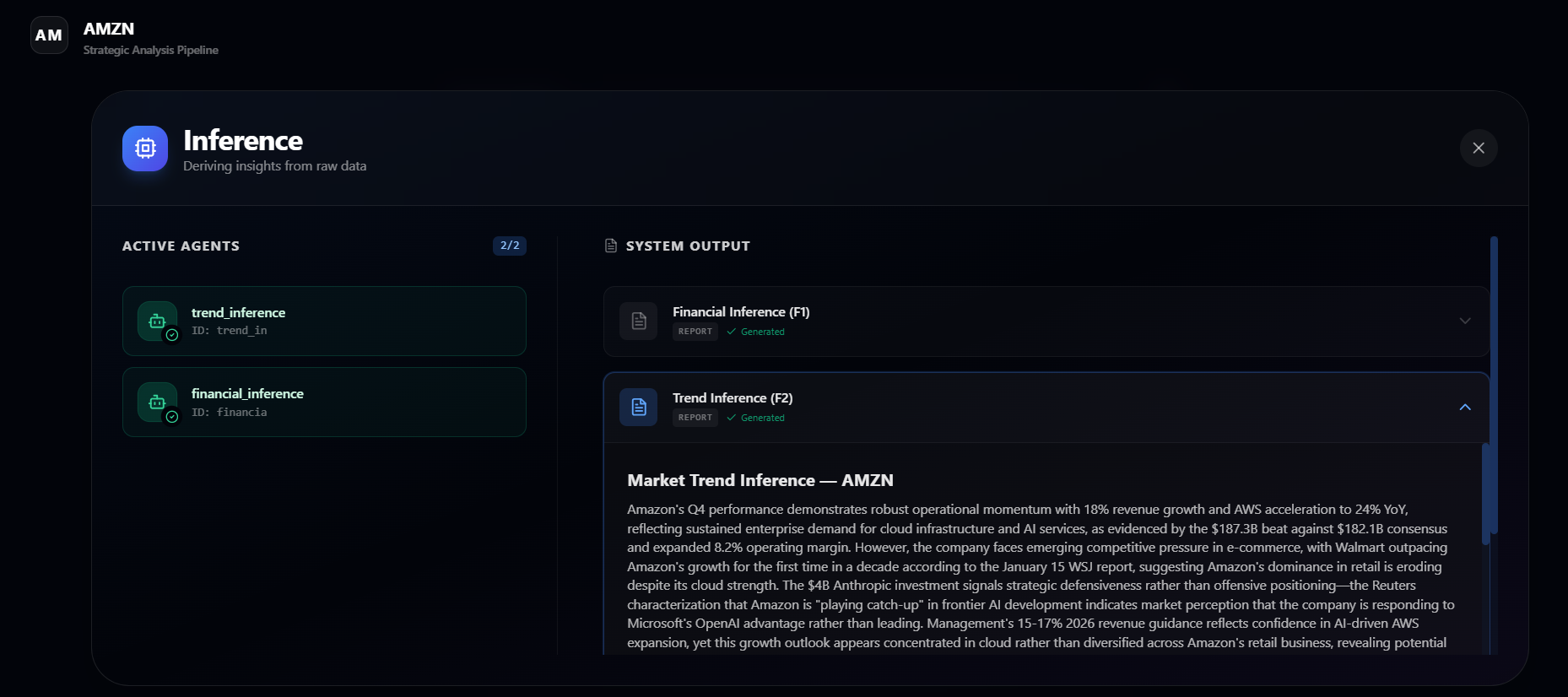
INFRENCE AND MARKET SIGNALS INFO
-
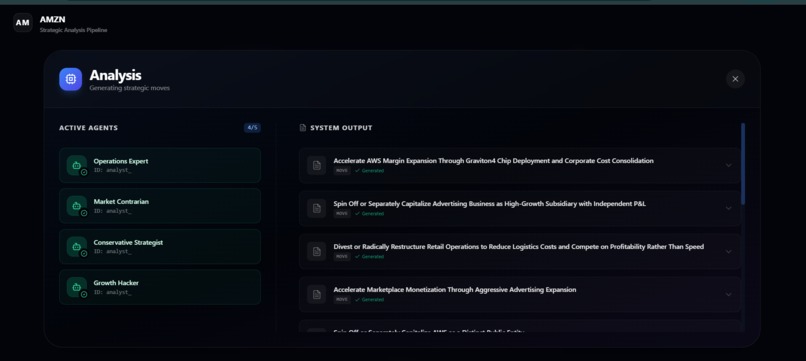
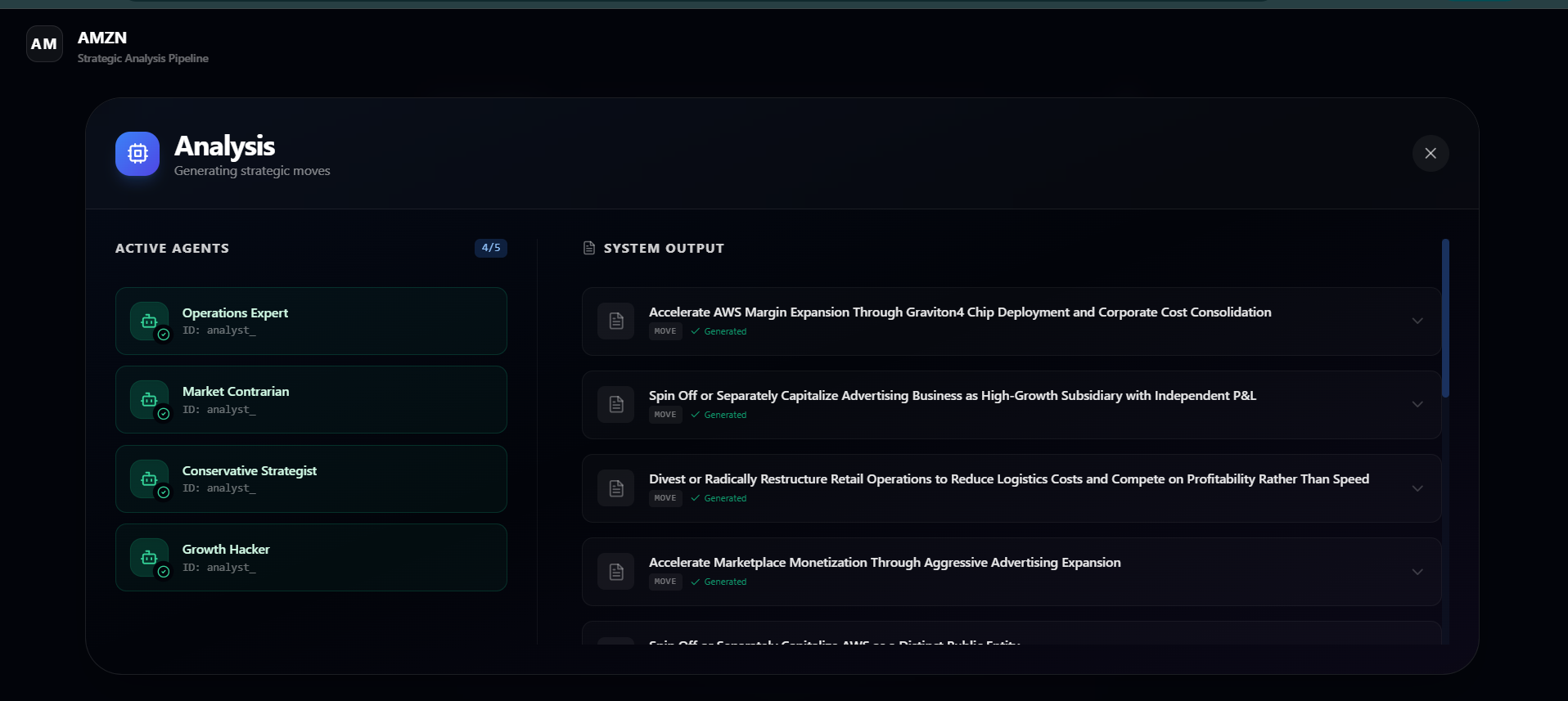
MOVES BEING GENERATED
-
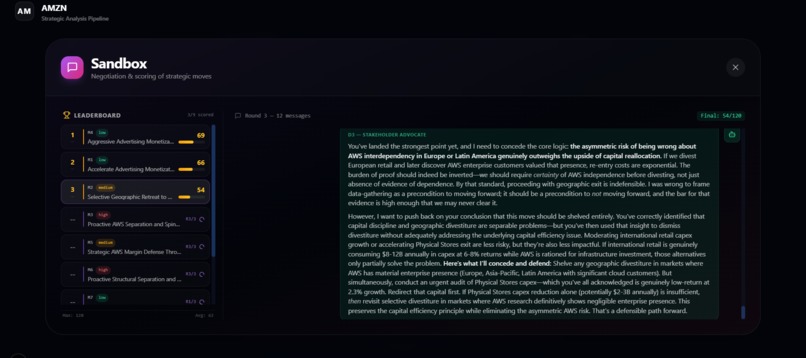
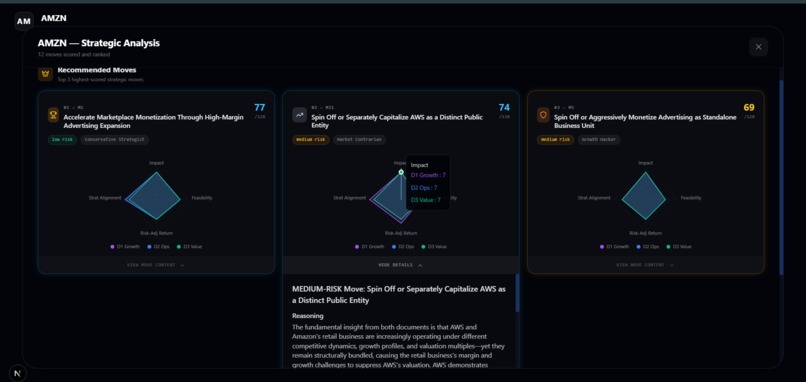
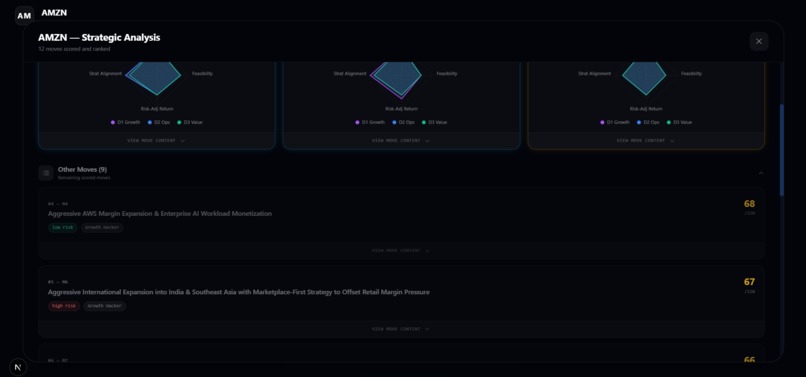
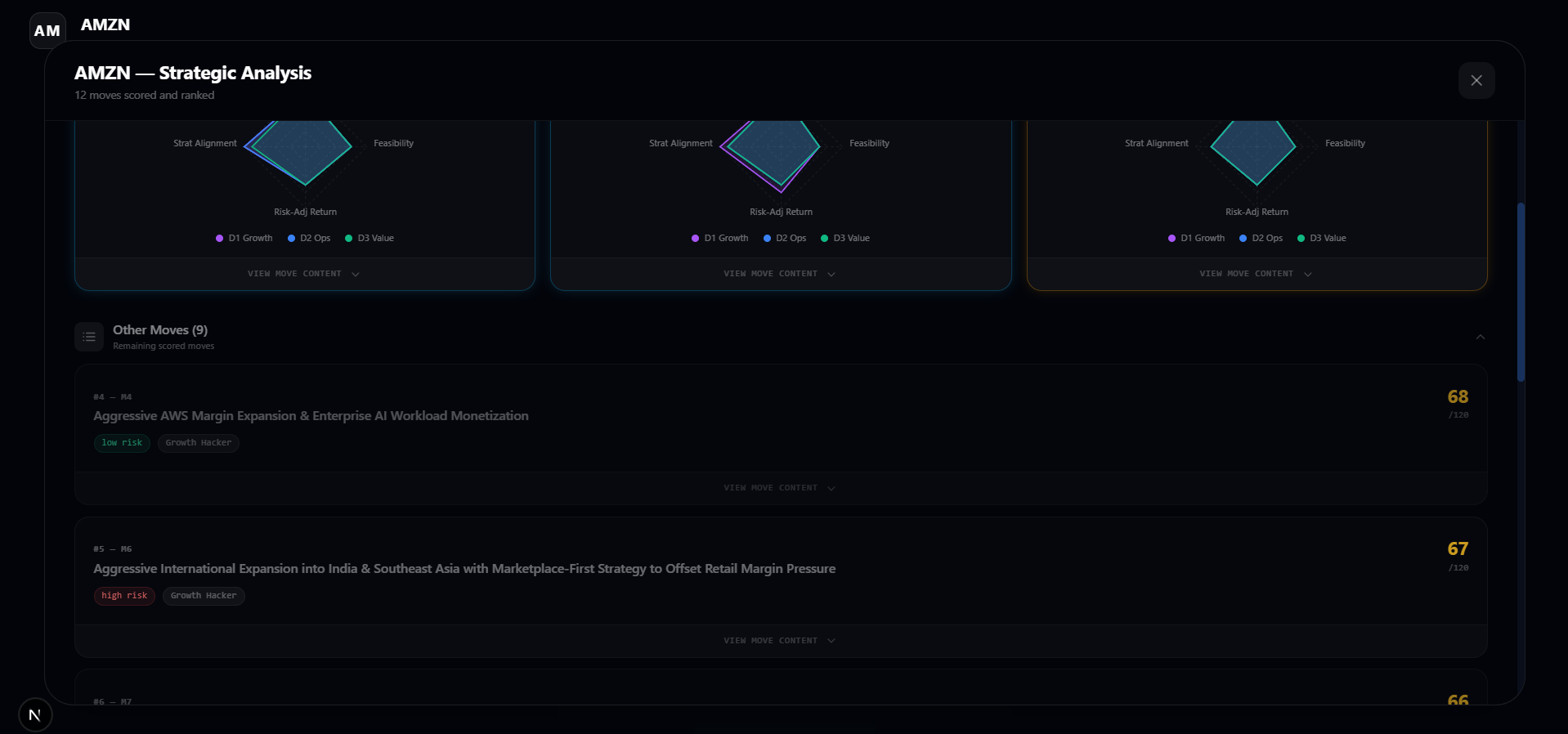
MOVES BEING SCORED ON THE DYNAMIC LEADERBOARD
-
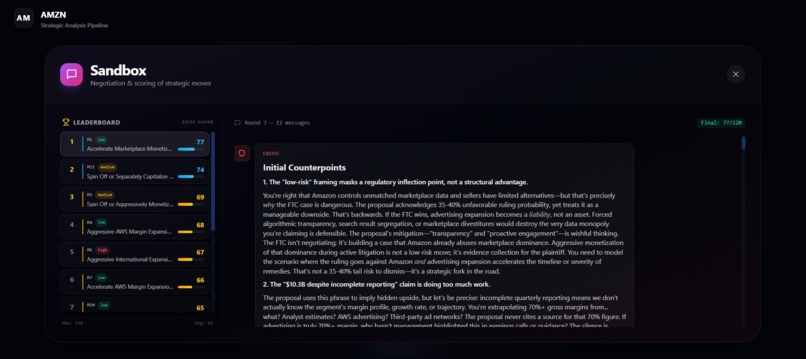
-
-
-

Inspiration
- Watched a 20VC podcast and realized that strategy consulting is a $500B+ industry, yet the core process hasn’t fundamentally changed: analysts still manually gather reports, debate internally in closed rooms, and present recommendations after long turnaround cycles.
- We asked what if we could replicate that entire workflow with adversarial multi-agent AI systems, not a single chatbot.
- That’s when we designed a layered architecture of autonomous agents that mirrors the hierarchy and separation of responsibilities in Big Four-style consulting workflows.
- The architecture is inspired by neural networks: each layer refines the signal from the previous one. We applied that same layered refinement to strategic reasoning.
What it does
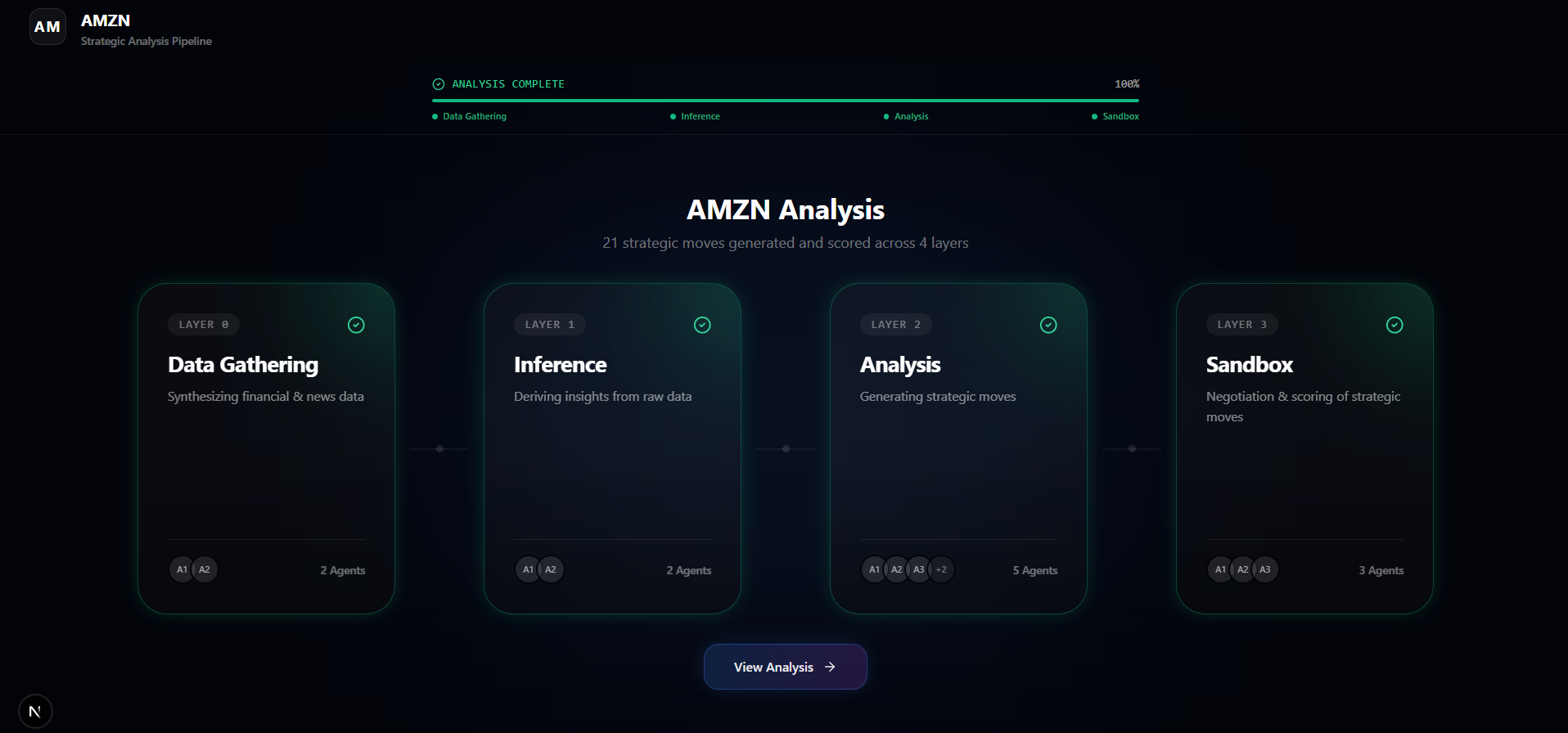
Big4 is an autonomous strategic consulting system. You give it a company ticker (e.g., TSLA, AAPL). It then:
- Builds structured financial and market context through specialized AI agents.
- Derives two inference reports: one focused on financial performance and one on market and trend signals.
- Generates strategic moves from five analyst agents with distinct personas, each proposing low-, medium-, and high-risk options grounded in the evidence.
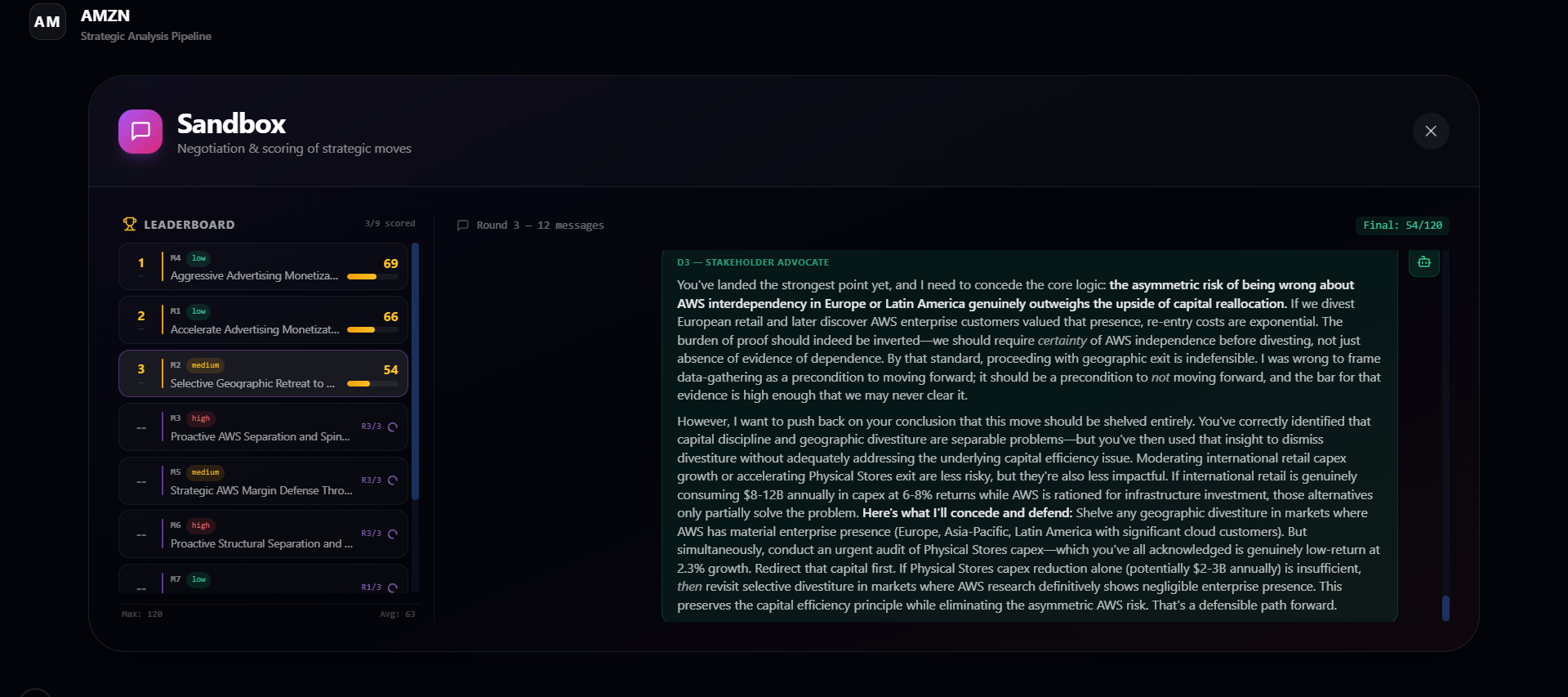
- Stress-tests every move through adversarial negotiation: one Critic agent debates three high-agency decision-makers across multiple rounds (up to 10).
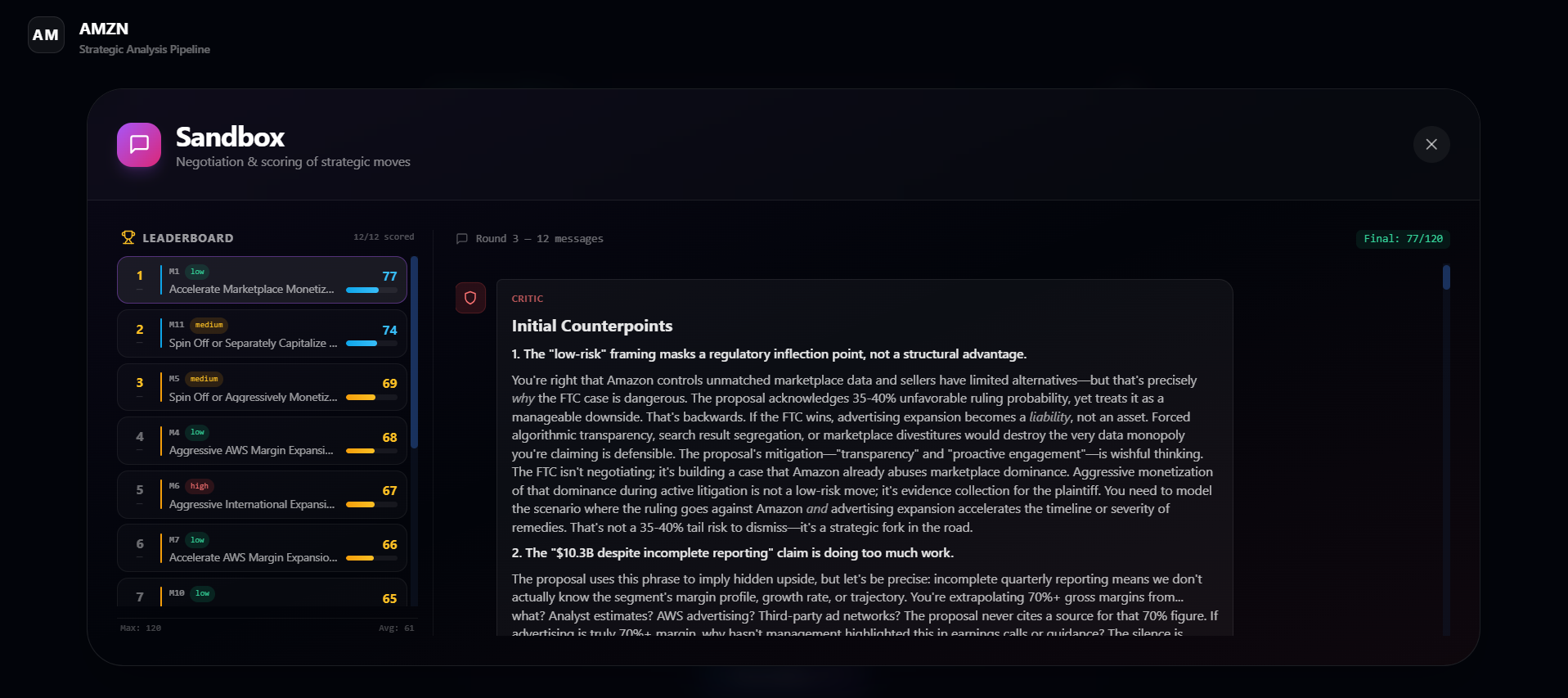
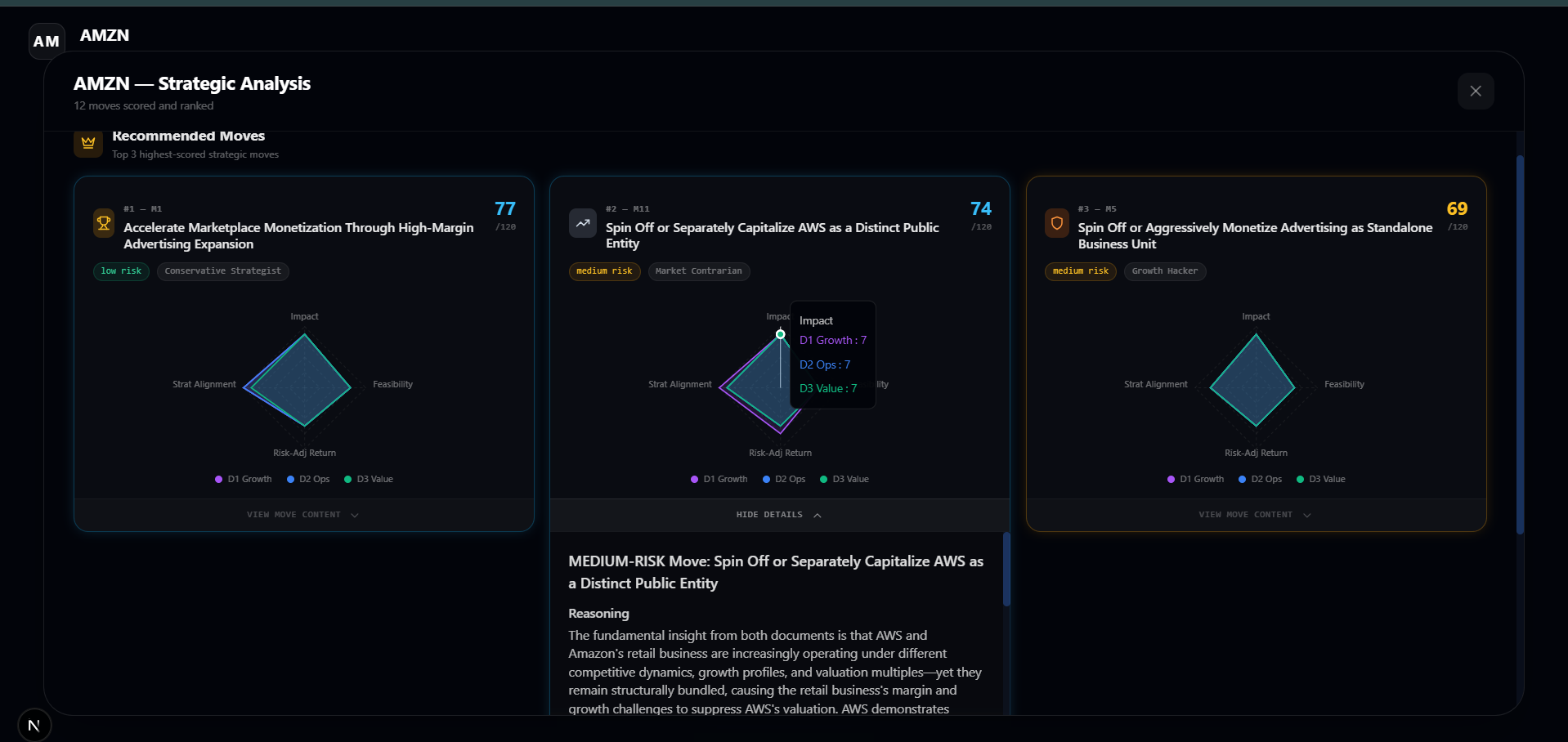
- Scores each move on four metrics (Impact, Feasibility, Risk-Adjusted Return, Strategic Alignment) and recommends the top three moves.
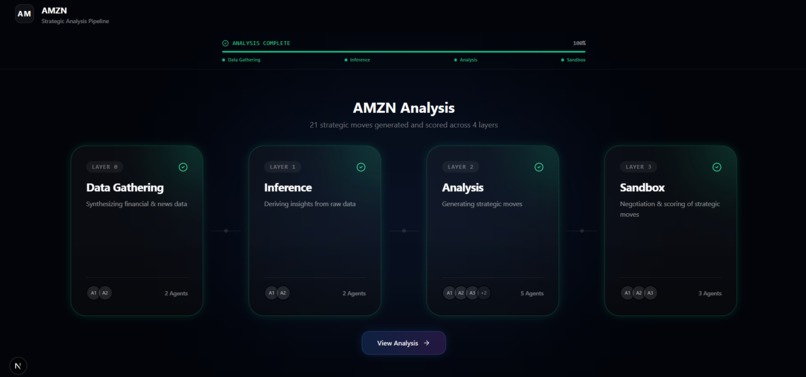
The entire process is observable in real time: users can track each layer’s progress, inspect intermediate reasoning, follow live negotiations, and explore the final ranked strategic recommendations.
How we built it
- Agent Architecture: 4-layer pipeline modeled after neural-network-style refinement. Layer 0 synthesizes context, Layer 1 derives inferences, Layer 2 proposes moves, and the Sandbox (Layer 3+4) runs critic-vs-board adversarial negotiation.
- Backend: FastAPI for APIs + SSE for real-time streaming; LangGraph orchestrates the pipeline and state transitions.
- Parallelism: We use fan-out/fan-in concurrency (
asyncio.gather) so inference agents, analyst agents, and sandbox scoring run in parallel for faster turnaround. - LLM Layer: Anthropic Claude (Haiku) via Python SDK, with persona-specific prompts, retry/backoff handling, and structured score extraction.
- Scoring Engine: 3 decision-makers score each move on 4 metrics (Impact, Feasibility, Risk-Adjusted Return, Strategic Alignment) for a total score out of 120, then we rank top recommendations.
- Frontend: Next.js 16 with live pipeline visualization, negotiation view, leaderboard, and final move breakdown charts.
- Auditability: We persist intermediate artifacts, debate transcripts, and score breakdowns so every recommendation is traceable.
Challenges we ran into
- Total pipeline time: The end-to-end pipeline was painfully slow when negotiations ran sequentially. We parallelized internal sandbox negotiations and sandbox creation itself, allowing us to conduct negotiations on 5 moves in parallel at a time.
- Critic bias: The Critic agent was initially winning every negotiation, which drove all move scores unreasonably low. We re-tuned the personas of the Critic and Decision Makers to make boardroom debates more balanced and fair, ensuring strong moves could survive scrutiny without being unfairly penalized.
- Agent verbosity vs. speed: Early prototypes had agents producing 400-line responses, making 10-round negotiations take 4+ minutes per move. We solved this by capping max_tokens and embedding explicit conciseness instructions in both personas and prompts, cutting negotiation time by 60%.
- Real-time state synchronization: We hit race conditions between streamed SSE events and final
/resultsfetches, where the UI occasionally completed before ranked outputs appeared. We added completion-triggered refetch logic and safer result hydration.
Accomplishments that we're proud of
- 13 AI agents working in concert — with distinct personas, adversarial debate, and transparent scoring. This isn't a wrapper around a single chatbot; it's a full consulting workflow.
- Every decision is auditable — conversation logs, scoring justifications, and intermediate documents are all persisted. You can trace exactly why a move scored 87/120 vs. 64/120.
- The negotiation system actually works — the Critic raises genuine concerns, Decision Makers address them substantively, and scores reflect the quality of the debate. Weak moves get low scores. Strong moves survive scrutiny.
- Real-time pipeline visualization — watching 4 layers light up sequentially, zooming into live negotiations, and seeing spider charts appear on completion creates a compelling experience.
What we learned
- Persona engineering matters more than prompt engineering. The difference between a generic "analyze this" prompt and a Critic who has "seen three companies fail from overconfident strategy" is night and day in debate quality.
- Adversarial agent systems need careful balance. If the Critic is too aggressive, scores collapse. If Decision Makers are too agreeable, debates become echo chambers. We iterated extensively on persona intensity.
- LangGraph is powerful for fan-out/fan-in parallelism but adds complexity for linear pipelines. For the main driver, direct function calls with
asyncio.gathergave us better control and observability. - Real-time streaming (SSE) transforms the user experience. A 3-minute pipeline feels fast when you can see every step happening live.
- We can address the facts that these systems though on a org level sound great, but pilot runs by consulting firms and business orgs in a company should be done on smaller scales such as set of teams to attain proof of concept.
- This might change the initial layers of the architecture by replacing financial and trend inference by team dynamics, client history & relations, and active kanban boards.
- Observability is non-negotiable in multi-agent systems. Without structured logs and persisted intermediate artifacts, debugging parallel agent behavior becomes extremely hard.
- LLM outputs need defensive handling in production-like pipelines. We learned to validate/parse aggressively and add fallbacks when outputs are not perfectly structured.
- Reliability in real-time UX depends on synchronization, not just model quality. Streaming events, partial results, and final result hydration must be coordinated to avoid race-condition glitches.
What's next for Big4
- Live data integration — Replace synthetic data with agent web tool to get SEC filings, real-time updates from Yahoo Finance and other news APIs, and trending topics in space.
- Multi-ticker portfolio mode — Analyze multiple companies and generate cross-portfolio strategy recommendations
- Export to PDF/Slides — Generate presentation-ready output with charts, scores, and key reasoning
- What-if scenario simulator — Test recommendations under macro shocks (rate hikes, regulation changes, supply-chain disruptions).
- Pilot mode for teams — Adapt early layers to team dynamics, client history, and active kanban/project data for smaller internal POCs.
Built With
- anthropic
- asyncio
- claude
- fastapi
- langgraph
- nextjs
- pydantic


Log in or sign up for Devpost to join the conversation.