-

disCOVER logo
-
Data Schematic

Inspiration
disCOVER was born out of a collective necessity. As students just starting in our professional journeys, we have begun to write the first in an endless ocean of cover letters and resumes for ourselves. As such, we've all encountered our individual difficulties with the process. A web app that could tailor a cover letter based on a job listing and a resume would not only give us practice in skills applicable to our careers, but also help us come up with the cover letters to get those careers in the first place!
What it does
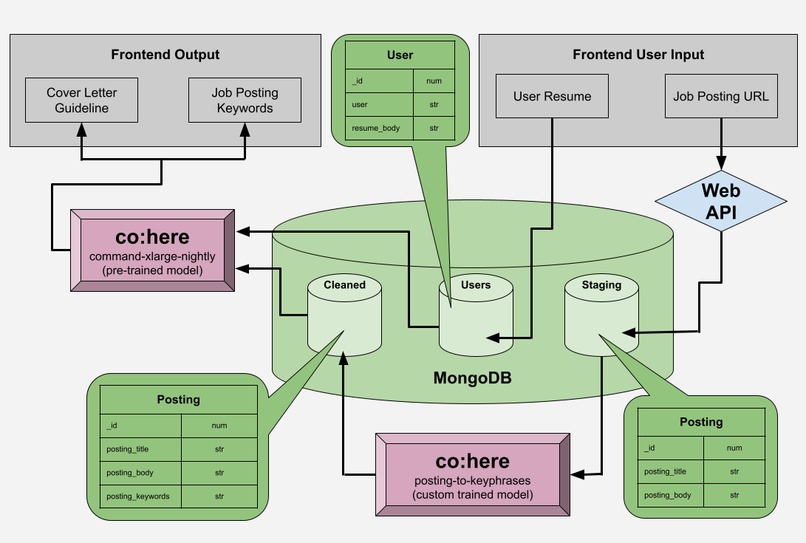
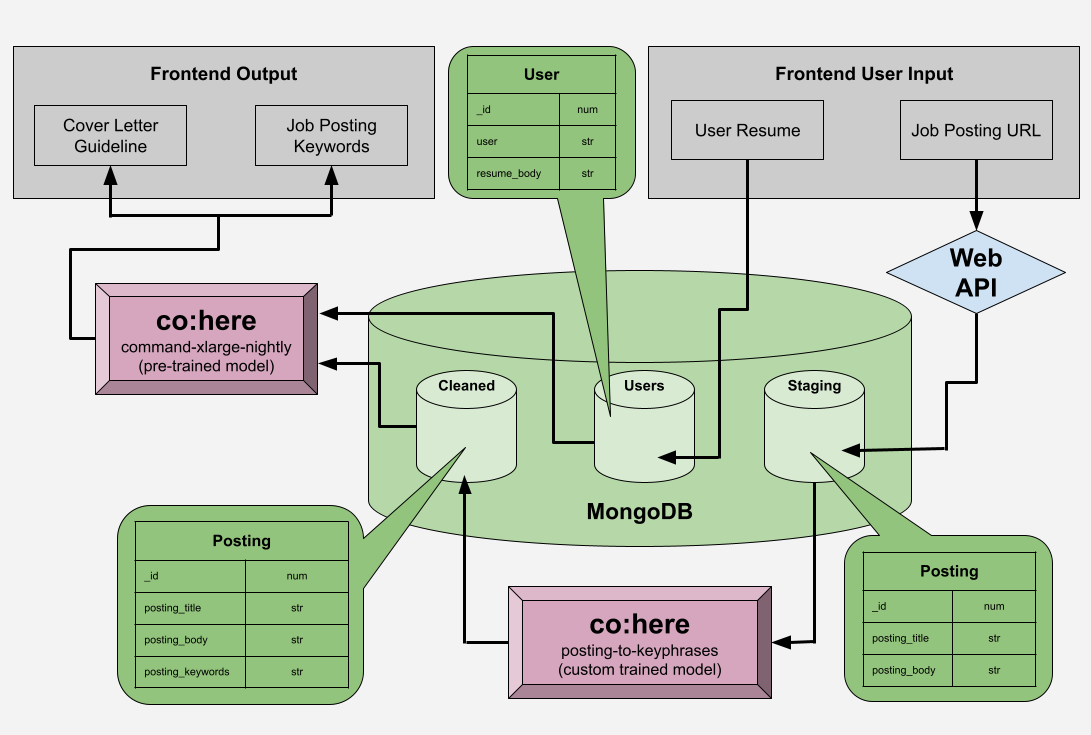
Using a job listing and a resume provided by a user, disCOVER goes through several stages of language cleaning and processing to generate the guidelines of a cover letter. The main processes in this cycle involve the use of two Co:here NLP models.
posting-to-keyphrases is our own custom language model that was created and trained for this project. Unlike the pre-trained language models, this model was trained using 32 job postings taken from Indeed.com that were directly copy-pasted and labeled manually with keywords and phrases. The intention was to train a model that was not only more fixated on the language of job applications and corporate onboarding, but also one that was more familiar to the many styles of job posting and resumes.
command-xlarge-nightly is the pre-trained language model given by Co:here which we used in the process to generate our cover letter guidelines. We used this language model over a custom trained language model as it needed to be more familiar with traditional literature and letter/email writing which is something we could not accurately train better than an existing model.
These two models work hand in hand. post-to-keyphrases serves more as a cleaning model that breaks down job postings (and in the future hopefully resumes) into their component skills and required proficiencies. We hope to build disCOVER around this function and in the future use various data analysis and comparing/matching techniques to help our users explore and expand their job prospects.
How we built it
We started off by implementing the MERN stack and React native, as we thought an app would be more used than a website. However, after a few hours, we decided it would be more practical as a web app, as most job applications are made on a computer. We used create-react-app for the frontend, alongside express.js, node.js, CORS, .env, MongoDB, and axios for various other parts of the stack. We had previously heard of one of the sponsors, Co:here, and were excited to try to use their API, which we spent many hours learning how to do. We custom-trained one of their language models to extract keywords from job listings, as well as used an existing model to analyze resumes alongside the keywords to generate a cover letter. Initially, we tried very hard to send fetch requests to the backend to interface with the Co:here API (with little to no success), but before giving up, we managed to connect to the API through a fetch request only on the frontend.
Challenges we ran into
This was our first time attempting to use the MERN stack, as well as using APIs so extensively. As such, we ran into many, many errors along the way, which oftentimes took hours to even track down the exact source of. Additionally, learning how to use Co:here was a bumpy process too, especially given that their models are constantly being updated as well.
The downside to training your own model is that you must be careful it is not worse than an existing one. Procuring and labelling a ton of data is incredibly time consuming and we did not have time to do more than the minimum 32 data fields.
Accomplishments that we're proud of
We are thrilled to have implemented the full stack as well as trained our custom Co:here model. We're also proud of the webpages that we managed to finish, especially the styling. In the end, the development goal we set for ourselves was to get all of the important moving components in working order. We're all too familiar with the concept of "integration hell" and didn't wanna get caught up in that and end up with only partial promises and concept documents of our idea.
What we learned
We learned that planning and writing scalable code is something that has to be kept in mind at every step, otherwise, a lot of time would be spent parsing other people's code and fixing errors.
Additionally, many applications use technologies and datas from all over and getting them to all talk to each other is incredibly difficult. Each has an ideal format and environment to work in and it's our job to find a middle ground or ease the means of communication between them.
Finally, for the majority of our team members, this was a first dip into the world of machine learning model training. While we can't say we nailed it on the first try, we see a clear path of improvement and a new road to disCOVER-y before us.
What's next for disCOVER
As of now, we only have one 'service'. We'd like to expand that functionality to include searching through multiple job listings, choosing from different language models for extraction or generating, more sophisticated data extraction capabilities so users can upload files instead of copy-pasting in text, as well as user accounts and authentication so users can save their resumes and job listings they're applying for.
Our model can always be expanded and trained further to increase its accuracy. In the future, we'd hope that this model is also trained to do the same with resumes. This allows us a common category between resumes and postings. We hope that in doing this, skills and key phrases become almost a form of filter. Users will be able to upload their resume and we could find them postings that would be a good fit for their skill set. Or users could even choose a skill they wanna learn and we'd be able to draw a bridge for them using their existing skills and finding a new career path along the way.
Built With
- axios
- cohere
- express.js
- mongodb
- node.js
- react.js



Log in or sign up for Devpost to join the conversation.