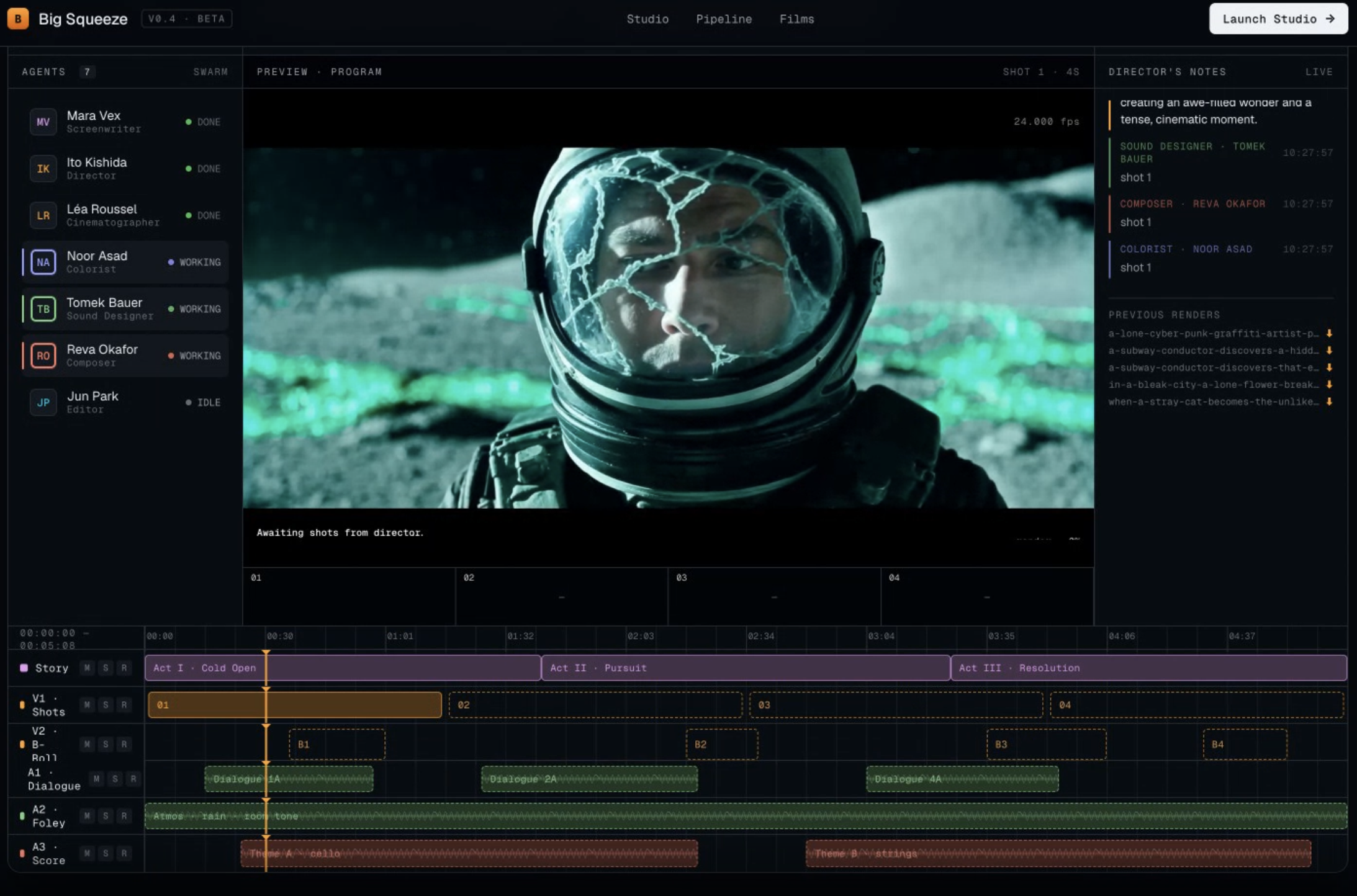
Big Squeeze — Agent-Swarm Filmmaker
Inspiration
Filmmaking is a miracle of collaboration — but it's also slow, expensive, and locked behind a wall of specialized tools and people. A screenwriter types words. A director imagines shots. A cinematographer frames them. Sound designers build worlds from silence. Composers score emotions. Colorists paint light. An editor makes it breathe.
We wanted to know: what if you could collapse that entire production pipeline into a single web page?
The idea was simple: paste a logline. Watch a swarm of AI agents — each with a distinct filmmaking identity — plan, generate, and assemble a short film in real time. No crew, no cameras, no months of post. Just your idea, seven agents, and a live timeline you can watch fill up.
Built for the DevNetwork AI+ML Hack 2026.
What it does
Big Squeeze is a full-stack agent-swarm filmmaker. You type a one-line movie idea (a "logline") like "A getaway driver gets one last job — but the cargo is alive" and press Generate. Behind the scenes, a LangGraph StateGraph orchestrates 7 agents:
| Agent | Role | What they produce |
|---|---|---|
| Mara Vex (Screenwriter) | Expands the logline into a treatment | Logline + synopsis + 3–5 story beats |
| Ito Kishida (Director) | Blocks coverage | Ordered shot list with camera moves, moods, durations |
| Léa Roussel (Cinematographer) | Frames each shot | Text-to-video prompt for AI video models |
| Tomek Bauer (Sound Designer) | Designs audio | Atmos, foley, and mix notes per shot |
| Reva Okafor (Composer) | Scores the film | Theme, instrumentation, tempo per shot |
| Noor Asad (Colorist) | Grades each shot | Palette, contrast, grade direction |
| Jun Park (Editor) | Reviews the cut | Pacing notes, transitions, final assessment |
As the pipeline runs, events stream via Server-Sent Events to a DAW-inspired live timeline UI — you see agents go from IDLE → WORKING → DONE, shots appear on the timeline, and the preview viewport shows each render progress in real time. When the last shot is done, ffmpeg assembles everything into a downloadable MP4.
How we built it
Stack
- Next.js 16 (App Router) — full-stack framework
- LangGraph (LangChain) — state machine orchestrating the 7-agent pipeline
- Vercel AI SDK — LLM calling with structured output (
generateObject/generateText) - Groq / OpenAI / AI Gateway — swappable LLM providers
- fal.ai — LTX-2 and Seedance 2.0 for video generation
- ffmpeg + rsvg-convert — shot assembly (concat MP4 segments, SVG→PNG→MP4 fallback)
- Pure CSS — DAW-inspired dark theme with OKLCH colors, no Tailwind in components
- TypeScript (strict mode, ES2022)
Architecture
The pipeline is a LangGraph StateGraph with 8 nodes and 2 conditional routers:
START → Screenwriter → Director → Cinematographer → Renderer → PostProduction
│
┌─────────────────────────┘
▼
QC Router
├── retryShot → Cinematographer (retry)
└── advanceShot → Advance Router
├── Cinematographer (more shots)
└── Editor → END
The orchestrator runs the graph as a background promise while a polling loop drains a shared event channel at 50ms, yielding PipelineEvent objects as an AsyncGenerator. The API route wraps this in a ReadableStream and emits SSE lines (data: {...}\n\n). The Studio UI reads via fetch + ReadableStreamDefaultReader.
Dual-path agent design
Every agent has two code paths:
- LLM path — calls the configured provider (Groq, OpenAI, or AI Gateway) via the
aiSDK. Handles rate-limit retry with exponential backoff, JSON-schema-aware routing, and per-agent model selection (each agent can use a different model). - Fallback path — produces deterministic output using seeded data arrays. This means the entire pipeline runs with zero API keys — perfect for demos, CI, and hackathon judging.
Provider abstraction
Video generation is abstracted behind a VideoProvider interface:
interface VideoProvider {
generateShot(input: GenerateShotInput): Promise<ShotRender>;
}
Three implementations:
SimulatedVideoProvider— keyless, produces animated SVGs with gradient backgrounds, text overlays, camera/mood metadata. The pipeline's default.FalVideoProvider— calls fal.ai's LTX-2 or Seedance 2.0 for real AI video with audio. Supports reference-image conditioning for shot-to-shot consistency.RunPodVideoProvider— stub for self-hosted inference.
Switch with VIDEO_PROVIDER env var. No code changes.
UI
The Studio is inspired by DAWs (Ableton, Pro Tools) — dark, dense, information-rich:
- 6-track timeline (Story, V1 Shots, V2 B-Roll, A1 Dialogue, A2 Foley, A3 Score) with playhead, clips, and clickable shot regions
- Agent panel — 7 named personas with IDLE/WORKING/DONE status lights
- Preview viewport — REC indicator, timecode, camera metadata, render progress sweep
- Director's Notes — scrolling log of all agent activity with timestamps
- Configurable output — 6 aspect ratios, 4 resolutions, 10 target runtimes
- Provider selector — swap between simulated / Seedance / LTX-2 on the fly
Challenges we ran into
Shot-to-shot consistency
AI video models generate each clip independently — characters, settings, and style vary wildly between shots. We tackled this with reference-image conditioning: the first frame of each completed shot is extracted (via ffmpeg) and fed as an image_url to the next shot's generation request. It's not perfect, but it creates a visible visual thread.
Rate limits and retries
The Groq free tier has an 8,000 TPM limit. Our post-production node runs Sound Designer, Composer, and Colorist sequentially (not in parallel) to stay under the limit. The LLM wrapper has exponential-backoff retry with rate-limit detection (parses try again in Xs from error messages).
Video model quirks
LTX-2 and Seedance 2.0 have completely different parameter schemes:
- LTX-2 uses
duration(int 6/8/10) andresolution(1080p/1440p/2160p) - Seedance uses
duration(string "4"–"15"),resolution(480p/720p), andaspect_ratio
We built model-specific parameter mappers and resolution-validity guards.
ffmpeg even-dimension constraints
libx264 requires even width and height. We added automatic parity correction at every stage — SVG dimension parsing, fallback generation, and output — after spending an embarrassing hour debugging "width 405 not divisible by 2."
Real-time streaming UX
The SSE stream needed to feel alive without overwhelming the browser. We batch events at 50ms polling intervals, parse incremental buffer chunks (SSE messages can split across TCP segments), and handle unmount safety (clean up timers, abort in-flight requests).
Making the keyless demo feel real
Without real LLM calls, agent outputs needed to be varied, context-relevant, and cinematic — not repetitive. We seeded deterministic fallbacks with rich arrays of cameras, moods, palettes, and themes, and the simulated video provider adds per-shot hue variation via FNV-1a hashing of the prompt text.
Accomplishments that we're proud of
Full pipeline runs with zero credentials — keyless simulation mode means anyone can visit the site and see the full 7-agent pipeline, complete with animated SVGs, live timeline, and a downloadable MP4. No
.envsetup required.7 named agents with distinct creative voices — each agent has a name, initials, role, and accent color. The pipeline treats them as actual collaborators, not just function calls.
DAW-grade UI in pure CSS — the timeline, transport controls, shot strip, and agent panel are entirely hand-styled. No component library, no shadcn, no Tailwind in components. 1,287 lines of globals.css with OKLCH color interpolation.
Real-time transparency — you don't just get a film at the end. You watch every creative decision: the writer's beat sheet, the director's shot plan, the cinematographer's prompts, the sound designer's foley notes. The "Director's Notes" log captures it all.
6 aspect ratios, 4 resolutions, 10 runtimes — from 9:16 phone vertical to 2.39:1 cinema scope, 360p to 1080p, 5 seconds to 10 minutes. The pipeline dynamically adjusts shot count and duration scaling.
22 curated preset loglines — daily-seeded random selection of 4 presets so the demo always feels fresh.
Reference-image conditioning — automated ffmpeg frame extraction feeds the previous shot's first frame as a visual reference for the next shot, creating shot-to-shot consistency without manual intervention.
What we learned
LangGraph is remarkably well-suited for agent orchestration. The StateGraph pattern with typed, mergeable annotations made it natural to add new fields (shot revisions, per-shot results, reference frames) without refactoring existing nodes. The conditional edge system lets us build a QC loop (retry failed shots up to 3 times) that cleanly routes back through the generation pipeline.
Provider abstraction is worth the overhead. The VideoProvider interface let us develop and test the entire pipeline with simulated video, then swap in real fal.ai generation with a single env var change. When Seedance 2.0 came out mid-hackathon, adding support was a new adapter class — zero changes to agents, graph, or UI.
SSE is still the simplest real-time protocol. WebSockets would have been overkill for one-directional event streaming. A ReadableStream + TextEncoder + "data: ...\n\n" format is trivially debuggable (you can curl the endpoint), works through any proxy, and the browser's fetch streaming API handles backpressure automatically.
Fallback-first development is a superpower. Building every agent with a deterministic fallback path meant we could iterate on the pipeline logic, UI, and assembly without waiting for LLM responses or burning API credits. The fallback path is not a downgrade — it's a first-class development and demo strategy.
AI video models are powerful but chaotic. LTX-2 and Seedance produce remarkable clips, but they're effectively random seeds given the same prompt. Shot-to-shot consistency is the open problem. Our reference-image approach helps but doesn't solve it — the output reads as an animatic / concept visualizer, which is an honest and useful niche.
What's next for Big Squeeze
Near-term
- RunPod provider — self-hosted LTX-2 for sovereign/private generation (sponsor-aligned)
- Pre-rendered fallback films — cached demo outputs for stage presentations where latency is critical
- Audio generation — proper music bed and foley synthesis instead of descriptive notes
- Longer film support — beyond 10 minutes with scene-level parallelism
Medium-term
- Real-time iteration — pause the pipeline, tweak a shot's prompt or duration, resume
- Shot re-ordering and editing — drag-and-drop the shot strip to reorder before assembly
- Multi-modal input — accept full screenplays (.fountain, .fdx) and reference images
- User accounts and history — saved projects, shared films, public gallery
Long-term
- Custom agent personas — let users define their own crew with custom model assignments
- Consistent characters — fine-tune or LoRA a video model on generated character images for true visual continuity
- Branching pipelines — explore multiple creative directions in parallel and pick the best cut
- Collaborative directing — multiple users watch and annotate the same live timeline
Built With
- ai-gateway-(vercel)
- css-(oklch)
- fal.ai
- fal.ai-(ltx-2-/-seedance-2.0-text-to-video)-media:-ffmpeg-(concat
- ffmpeg
- frame-extraction)
- groq
- langchain
- langgraph
- langgraph-(langchain-stategraph)-ai/ml:-vercel-ai-sdk
- ltx-2
- next.js-16-(app-router)
- node.js
- node.js-?24-frameworks:-next.js-16-(app-router)
- openai-api
- pnpm
- react-19
- rsvg-convert
- rsvg-convert-(svg?png)-infrastructure:-pnpm-10
- seedance
- server-sent-events-streaming-standards:-zod-(schema-validation)
- typescript
- typescript-(strict)
- typescript-6-strict-mode
- vercel-ai-sdk
- vercel-deployable
- zod

Log in or sign up for Devpost to join the conversation.