-
-

AI Video Generated
-
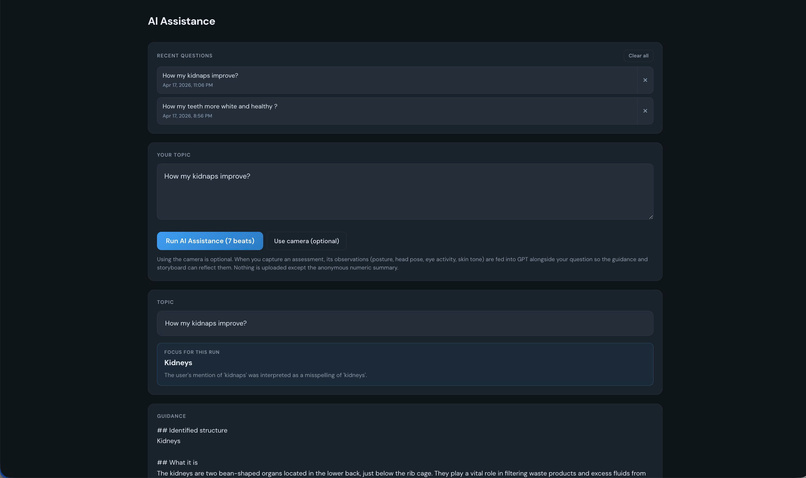
Asking for the answer
-
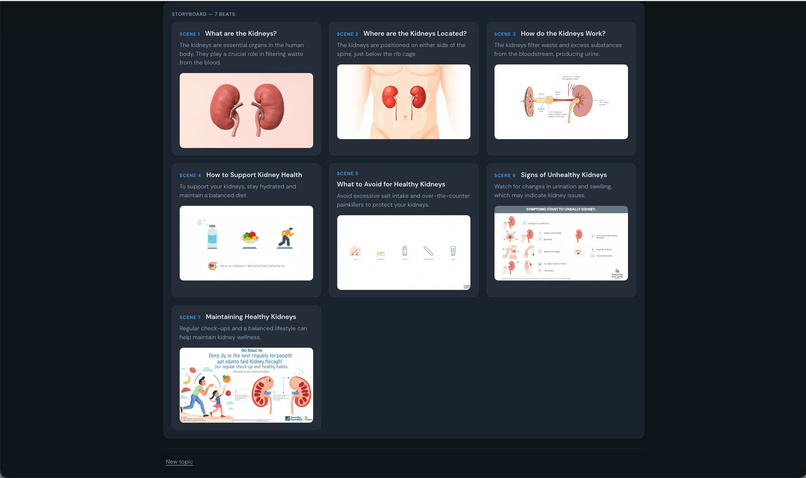
Images explaination

- Inspiration
Building an AI assistant for healthcare is one of the most practical and impactful real-world applications. However, text alone is often not memorable.
Receiving only text-based responses is less effective than seeing visual explanations through images or videos. The lack of visual context makes it harder for users to fully understand what is happening inside the body.
People are far more likely to remember a visual like “bacteria hiding inside a kidney tubule” than a paragraph describing the same concept.
That’s why we decided to build an AI assistant that generates images and videos based on users’ health-related questions. When a user asks about a specific part of the body, the system provides visual explanations along with clear, informative answers.
- What It Does
When users ask questions such as “How can I make my teeth whiter and healthier?”, the assistant not only provides a detailed answer but also generates relevant images and videos. These visuals demonstrate:
How bacteria affect teeth How to properly clean and maintain oral hygiene Which products or methods can help improve dental health
If a user asks something like “How can I improve my neck and kidneys?”, the system delivers:
Visual explanations of those body parts Educational content about how they function Guidance on improving health and preventing issues Additionally, users can enable camera-based AI assistance. This feature allows the system to: Track body movements Analyze posture and motion Detect abnormalities (e.g., incorrect neck angles) Provide real-time feedback and recommendations
- How We Built It
We built the system by combining multiple AI models and technologies: Large Language Models for answering health-related questions Image and video generation models (e.g., Stable Diffusion) Motion tracking and analysis using computer vision Open-source models from platforms like Hugging Face (e.g., Qwen, MiniMax)
This hybrid approach allows us to deliver both high-quality explanations and rich visual content.
- Challenges We Ran Into
One of the biggest challenges was managing computational resources and API costs. Generating images and videos at scale requires significant processing power and credits.
- To overcome this, we:
Optimized prompts to reduce unnecessary computation Combined multiple open-source models instead of relying on a single paid service Leveraged efficient architectures from Hugging Face Balanced performance and cost to ensure sustainability Accomplishments That We’re Proud Of Successfully built a multimodal health assistant that combines text, images, and videos Created a more engaging and memorable learning experience for users Integrated real-time motion tracking for personalized health insights Reduced operational costs by leveraging open-source AI models Delivered a scalable solution that can be expanded to multiple health domains What We Learned Visual content significantly improves user understanding and retention Combining multiple AI models can outperform relying on a single solution Cost optimization is critical when working with generative AI systems Users value personalized and interactive experiences, especially in healthcare Simplicity and clarity in explanations are just as important as technical accuracy What’s Next for Bidget Health – Feel Your Health
- Our next steps include:
Expanding video generation capabilities for more detailed medical explanations Improving motion tracking accuracy for better posture and movement analysis Scaling the platform to support more health topics and conditions Publishing educational content on social media to spread basic health knowledge Building a community-driven ecosystem for continuous learning and improvement
Built With
- amazon-web-services
- claude
- gpt
- java
- minimax
- python
- qwen
- typescript

Log in or sign up for Devpost to join the conversation.