-
Our Aims and Mockup
-

Our Poster


Inspiration
The information we consume sculpts our reality: it dictates what we care about, how we act, and how we view the world. Yet, this foundation is cracking. Modern news is increasingly polarised, and we are drowning in a sea of misinformation—a fire now fueled by generative AI.
We know that neutrality is often a myth; every story has a frame. But while we read the news, we often miss the invisible architecture of persuasion beneath the text. Worse, the existing AI tools designed to detect this bias are "Black Boxes." They offer opaque scores without explanation, effectively just swapping the journalist's bias for the model's.
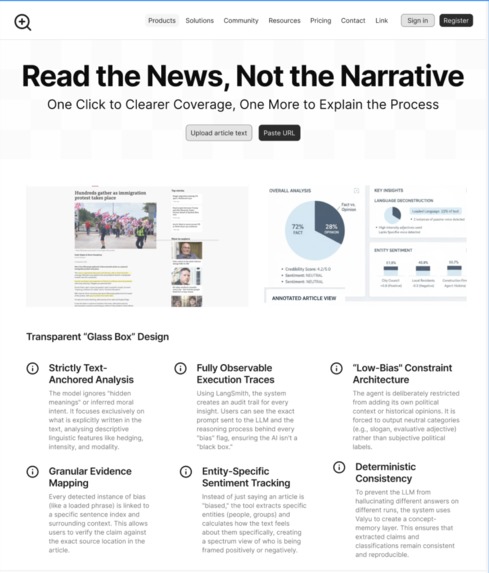
We built this tool to be a Glass Box. It is a tool that refuses to tell you what to think. Instead, it shows you exactly how the text is trying to make you think it.
What it does
BiasSphere is a transparent news-analysis agent that reveals how language shapes perception within an article. It evaluates the ratio of verifiable, evidence-based claims compared to subjective or speculative commentary, giving readers a clearer sense of how much of the text is grounded in fact versus opinion. The system highlights loaded or emotionally charged language, such as spin, dog whistles, and subtle evaluative phrasing, so users can immediately spot wording designed to influence rather than inform. It also maps entity sentiment to show exactly how specific people, groups, or institutions are being framed throughout the article. Every insight is fully traceable: each claim, tone assignment, and detected phrase is linked directly to the exact sentence it came from, ensuring that readers can always see the original context and understand how the model reached its conclusions.
How we built it
We built BiasSphere as a low-bias, fully observable LLM pipeline designed to focus strictly on what is written in an article rather than what the model “thinks” about it. The system begins by taking the raw text and extracting entities, claims, and sentiment using Claude, but with strict constraints to prevent it from inferring political intent or adding outside context. It identifies loaded or emotionally charged phrases and pinpoints their exact positions, surrounding sentences, and tone. For every claim or flagged phrase, the system calls Valyu to retrieve neutral external sources that represent both positive and negative perspectives. These sources are then fed back into Claude to ground its analysis and reduce reliance on the model’s internal assumptions. Every step of this process is tracked through LangSmith, which records all prompts, outputs, evidence sentences, spans, and decision paths, allowing us to see exactly how each classification was made. The final structured output is then sent to our NiceGUI interface, where the article is reconstructed with highlighted phrases and hover-based explanations. This architecture ensures that the entire reasoning process is transparent, reproducible, and anchored directly to the text and verifiable sources instead of opaque model intuition.
Challenges we ran into
One of the biggest challenges we encountered was ensuring that the analysis of loaded phrases did not introduce additional bias from the LLM itself. Large language models have a tendency to infer missing context or apply their own prior assumptions, which risked shaping the outcome instead of objectively identifying bias in the article. To overcome this, we integrated Valyu as a grounding layer. Rather than relying on the LLM to judge the validity or strength of a claim, each loaded phrase was paired with external sources retrieved through Valyu. This forced the model to consider multiple viewpoints, reduced the influence of its own inherent patterns, and ensured that the system relied on verifiable evidence rather than internal speculation. This approach helped us maintain fairness and transparency while still allowing the model to analyse text meaningfully.
Accomplishments that we're proud of
We are particularly proud of building a system that can read an article, extract its key entities and claims, and highlight loaded or emotionally charged language directly within the text. The model not only identifies where bias may be present, but also explains why those phrases could influence the reader. The interactive interface allows users to hover over highlighted sections to see context, explanations, and supporting evidence. This transforms bias detection from a vague, subjective process into a clear, traceable, and intuitive experience. Bringing together entity extraction, sentiment analysis, evidence retrieval, and UI visualisation into a cohesive pipeline is something we are genuinely proud of.
What we learned
Throughout this project, we learned how to design and orchestrate an AI agent capable of performing complex reasoning tasks in a controlled, observable way. We became familiar with integrating a large language model, using LangSmith to trace model behaviour, and analysing how prompts, tool calls, and decisions flow through the system. We also gained experience building and deploying a full-stack solution that addresses a real societal problem: media bias and misinformation. The process taught us not only technical skills such as LLM grounding, FastAPI integration, and NiceGUI development, but also how to think critically about responsible AI, fairness, and the importance of transparency in automated decision-making.
What's next for us
The next phase for us is to move beyond a standalone web page and integrate our system directly into the user’s browsing experience through a Chrome extension. This will allow people to scan articles instantly as they encounter them online, making the tool far more accessible and practical. In the future, we plan to enhance the grounding process, expand to multilingual articles, refine our bias scoring approach, and introduce more advanced models capable of detecting deeper forms of framing, omission, and rhetorical influence. By integrating directly into the browser and continuing to strengthen the model’s transparency and robustness, we aim to make BiasSphere a reliable companion for anyone trying to navigate today’s complex information landscape.



Log in or sign up for Devpost to join the conversation.