-
-
Biased clinical data is used for training models
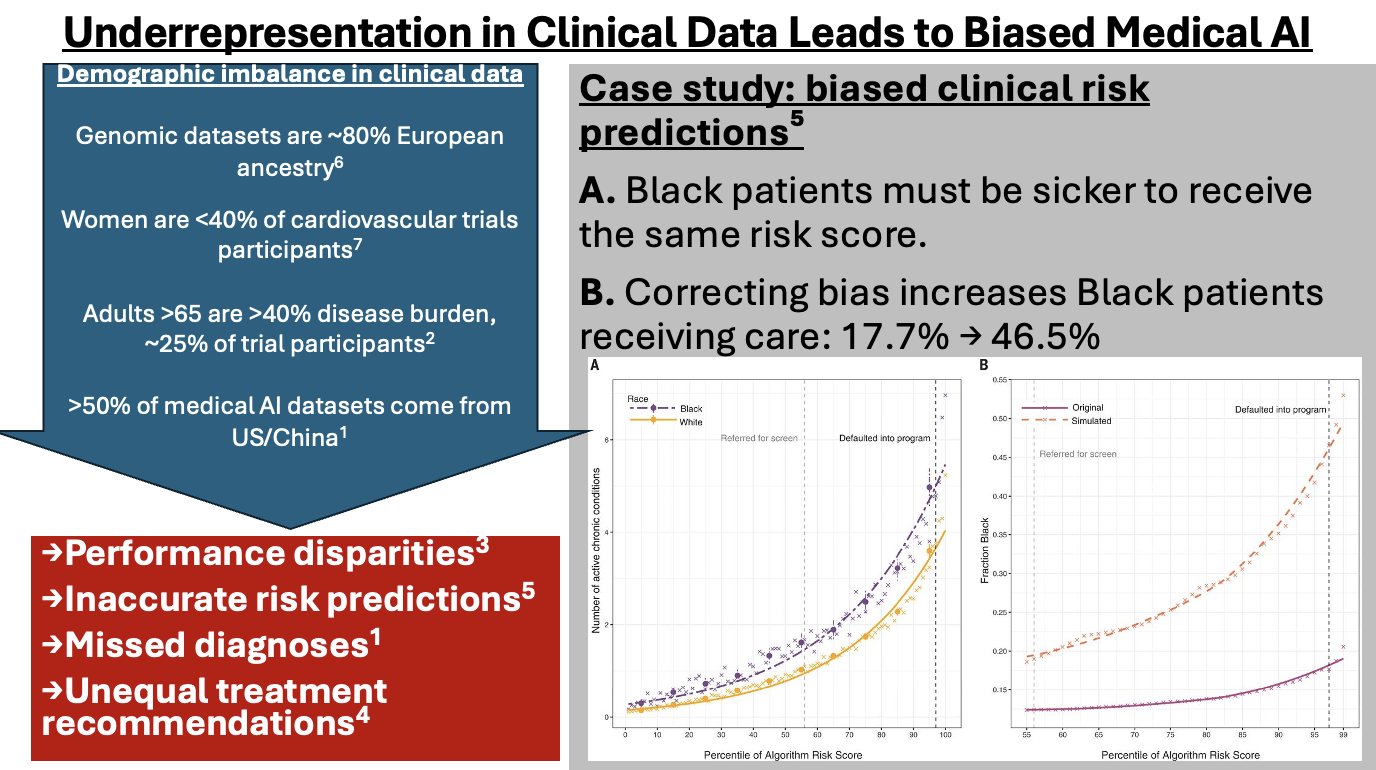
Problem Clinical machine learning has advanced rapidly. Model architectures have improved, benchmarks have increased, and predictive performance continues to rise. Yet translation into real-world clinical impact remains inconsistent. A central issue lies upstream. Clinical datasets such as MIMIC-IV Clinical Database, oncology registries, and electronic health records are not neutral representations of patient populations. They are shaped by healthcare access, documentation practices, and systemic inequalities. Celi et al. (2022) demonstrated that over half of clinical AI datasets originate from a limited number of countries, primarily the United States and China. This constrains representativeness and limits generalisability. Similarly, Obermeyer et al. (2019) showed that proxy variables such as healthcare spending can encode structural bias, leading to systematic underestimation of illness severity in Black patients. These issues are rarely addressed before model training. Data are typically assumed to be “clean enough.” That assumption is unsafe.
Solution BiasLens is a pre-processing and inspection layer designed to evaluate clinical data before it enters machine learning pipelines. Rather than building another predictive model, the system focuses on a neglected stage: data readiness for equitable and reliable AI. Given a clinical datapoint, BiasLens: • constructs a structured representation • identifies missing demographic and contextual variables • detects proxy features that may encode inequality • highlights known bias patterns (e.g., sex-based disparities in cardiovascular disease) • assesses generalisability across populations and settings • predicts likely downstream failure modes • produces a final risk classification for model training The output is designed for researchers and clinicians, not only engineers. Importance The prevailing bottleneck in clinical AI is not solely model performance. Increasingly, it is the quality, completeness, and representativeness of the data being used. Models trained on biased or incomplete data do not simply perform worse in aggregate. They fail selectively. Certain groups experience reduced diagnostic accuracy, delayed treatment, or inappropriate risk stratification. BiasLens addresses this by making hidden risks explicit before they scale. This aligns with recent work emphasising that healthcare AI must be evaluated on real-world impact, not just technical metrics (Celi et al., 2024). It also supports emerging efforts to standardise dataset transparency and documentation.
Implementation Context The system is designed to integrate into existing workflows, including: • clinical research pipelines using MIMIC-style datasets • oncology data platforms such as GENIE and Flatiron • hospital EHR preprocessing pipelines • clinical trial cohort selection processes BiasLens is model-agnostic. It does not replace downstream systems. It constrains and informs them.
Conclusion BiasLens introduces a missing layer in clinical AI systems. It does not attempt to correct models after deployment. It evaluates whether the underlying data should be trusted in the first place. This shift is necessary. Without it, improvements in model architecture will continue to yield diminishing returns in real clinical settings. The full system was originally implemented using a backend pipeline in a different programming environment; however, a lightweight HTML-based interface was developed for the demo to ensure reliability, responsiveness, and clarity during evaluation.

Log in or sign up for Devpost to join the conversation.