Inspiration
Politics, especially partisan politics, have reemerged in the news in recent times. From the democratic primaries to the impeachment inquiry of President Trump, the public is being flooded with new information. One of the largest sources of this information is Twitter, which is also the preferred form of communication for President Donald Trump. So, we wanted to do something to better understand the information stream of twitter, and we immediately thought of replicating the tweets are a way to discern, as an information consumer, what is false and what is true.
What it does
Our creation allows users to understand their inherent bias, as well as the leanings of twitter. It is a novel way for users to understand the queries that they otherwise would just enter into the search bar of Twitter. Ultimately, Bias allows readers to understand Twitter-and themselves.
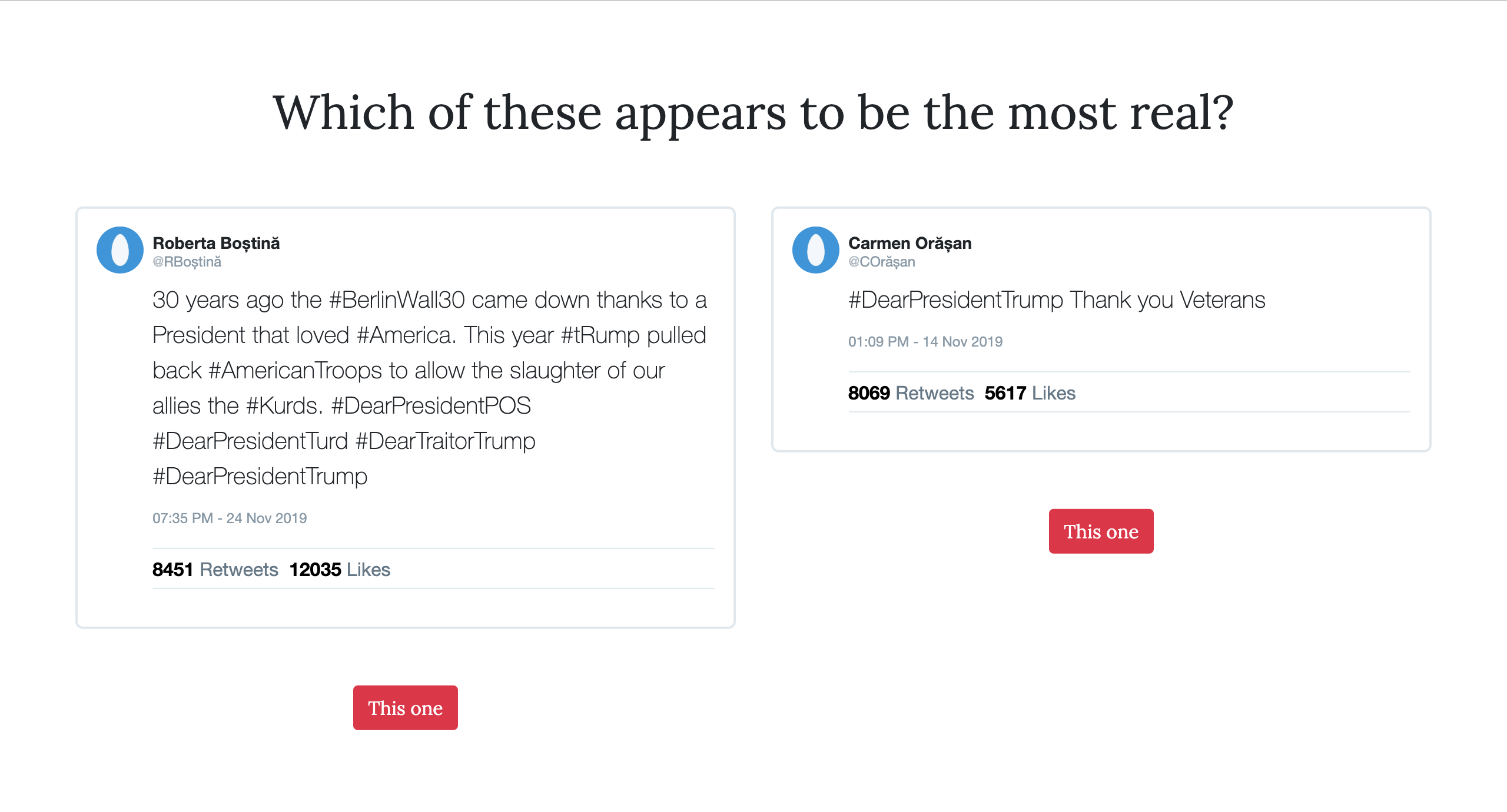
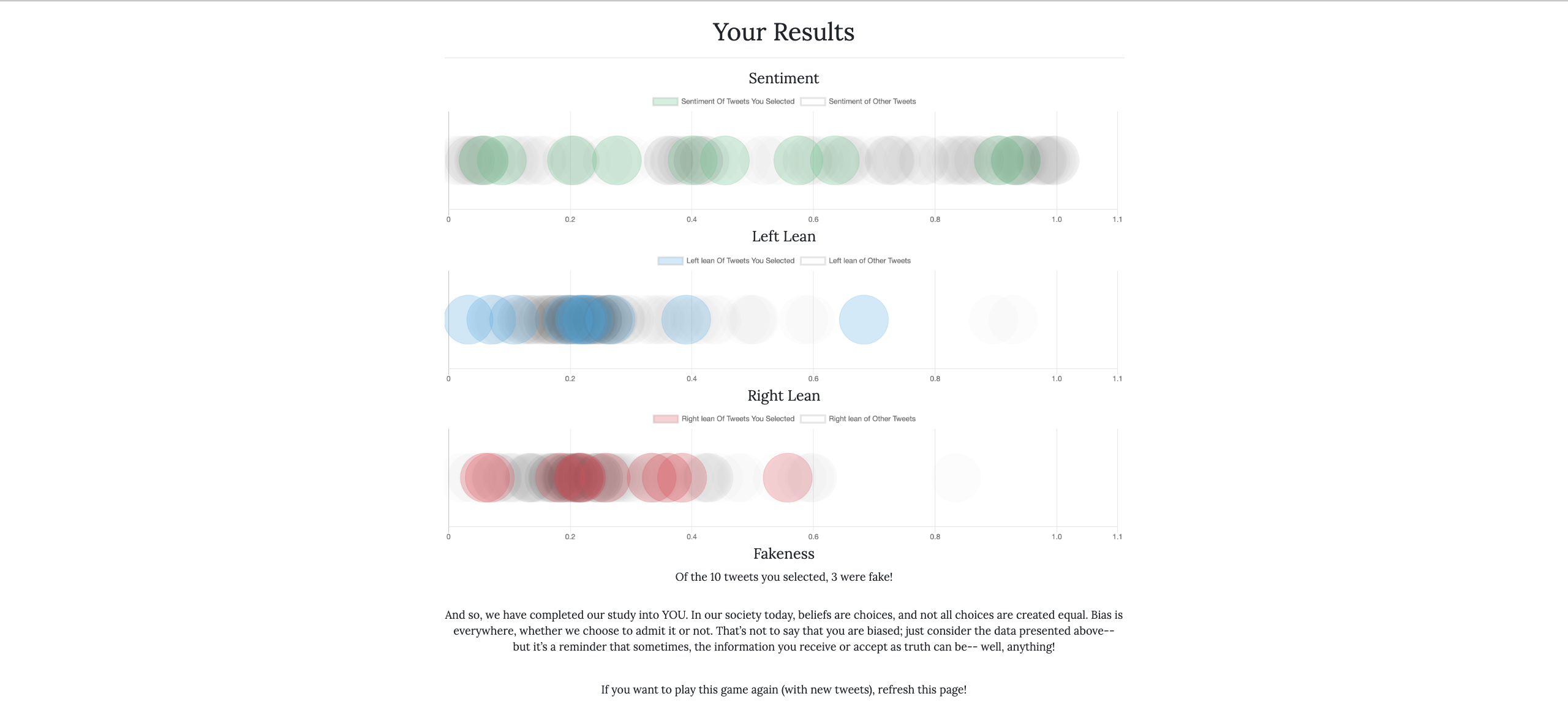
The user is prompted to enter search queries, from which results are pulled and fake data created. The user then enters this game-like scenario in which they have to choose whether or the tweet is real. In the end, the user is shown a comparison of the sentiment of their favored tweets, as well as the liberal and conservative leanings, as compared with their choices. In the end, they also receive an accuracy score of how accurate they were at discerning what is right and what is wrong.
How we built it
The application itself is built on Flask and then hosted locally. The user search query is passed to the Twitter API, from which tweets containing the word are selected. From this corpus of relevant tweets, Markov chaining is used to generate semantically similar tweets. The output is displayed using Charts.js and presented to the user.
Challenges we ran into
For us, the largest challenge was the segmentation of what we were trying to do. We knew that together, the various parts of the creation (from the fake tweets to the sentiment analysis) would be technically impressive but from a social perspective, meaningless. We knew that each part we could reasonably get running, but we wanted to create a cohesive end product that included all of these parts to best represent how inherent bias affects the understanding of how Twitter information is perceived.
Accomplishments that we're proud of
We are most proud of the integrative system and the game-like mechanism for comparison. We think that asking the user to label tweets would have been boring, and taken away from the individual accuracy of some of the fake tweets. So, we wanted to highlight not just the individual tweets but also the aggregation of the data that gives insight into the user, and having this two-page system allows for that. We are also very happy with the believability of these fake tweets, which surprised us after running the Markov chain generator multiple times. This is especially impressive considering the fact that we had to handle hashtags and mentions, which are very common on Twitter.
What we learned
What we learned most was about the UI. Working with the JSONs was not particularly difficult (although keeping track of them was), and thus, we made a concerted effort to try and make the project look good for the user. From the flying scrambling animation after each choice to the words floating on the first page, we learned a lot about animations and making them smooth. Similarly, we learned a lot about the charts and how they function, we wanted to present our data in a visually appealing way, and after lots of thinking, we settled on the overlapping information.
What's next for Biasd
The next step for Bias will be to expand the features that we can glean from the information we get. In keeping to a Twitter base, we can also get information about the other types of political parties, such as libertarians or socialists. We don’t want to characterize information as either liberal or conservative, as this is a dichotomy that we hope to break and also inherently part of our bias as developers. We’d also potentially want to expand beyond the Twitter corpus and move to other text-based systems such as Reddit, for example.
And of course, we’d like to put this out on the web, where everyone can enjoy it, not just us!



Log in or sign up for Devpost to join the conversation.