-

Our logo
-
Example console code
-

Landing page


Inspiration
In today's political climate, biased and untrustworthy news articles are everywhere. One news site may claim the Democrats are trying to monitor the enitre American populace with Big Government, while another says that the Republicans are busy trying to deport everyone who doesn't agree with their tax agenda. The result is division that prevents bipartisan progress.
What it does
While it is obvious to most people that neither of these two examples are true, it becomes more difficult to distinguish the role of bias in more subtle articles. Most people don't have the time, or sometimes the training to sift through dense political articles to determine what is actually true and what is a product of a manipulative news site. Our app simplifies this problem by doing the work for you.
A Quick Demo

How we built it
Step 1: First, we extract named entities. By this we mean the names of organizations and polititians, for example, Hillary Clinton, Donald Trump, or the NRA. For a more specific demonstration, we will use the headline of this article:
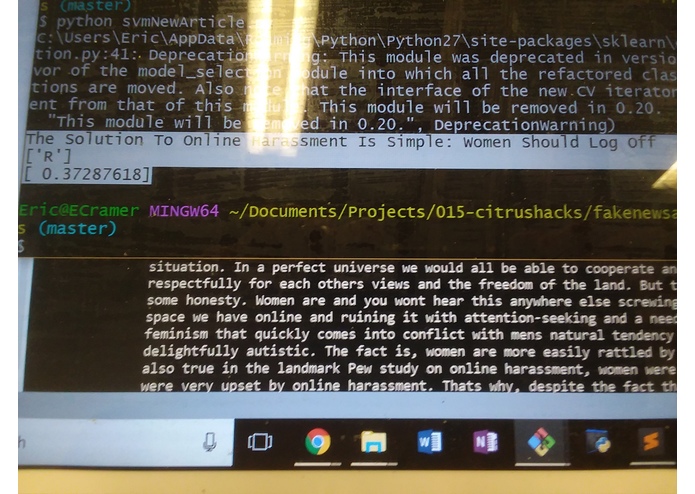
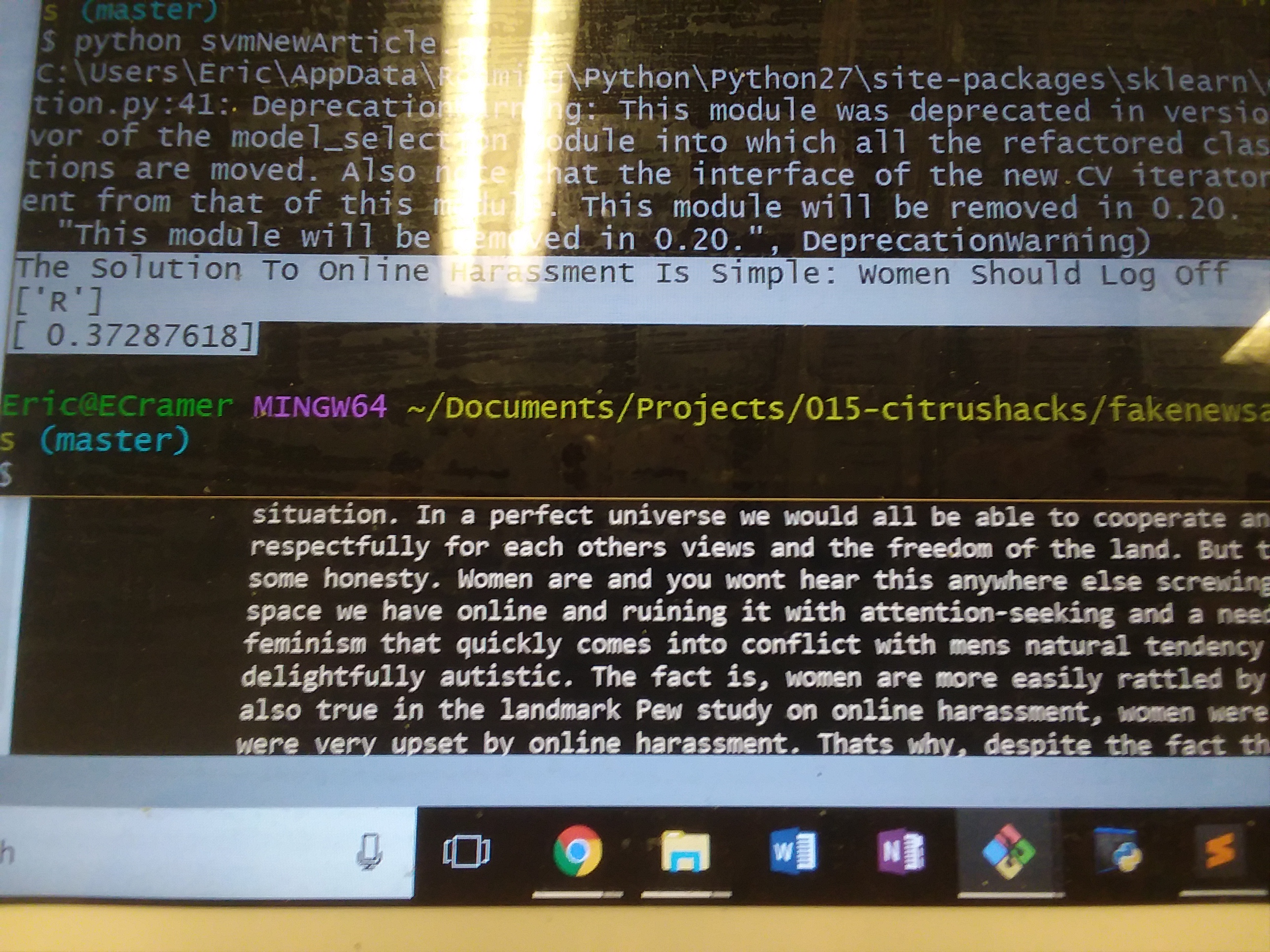
"The Solution To Online Harassment Is Simple: Women Should Log Off"
First, the algorithm breaks down the headline into the entity and adjective phrases. In this case the subject is "women" and the phrase is "should log off".
Step 2: It then uses sentiment analysis to determine if there is a positive or negative feeling about the entity. In this case, the phrase "should log off" is a negative phrase. It conducts Sentiment Analysis for each sentence that an entity appears in and captures its polarity score from [-1,1] as approving or disapproving. Then it applies the polarity score to the entity and calculates the bias metric using scaled sums per named entity in order to see in which ideological direction, Conservative (R) or Liberal (L) the article's bias tends to lean.
Step 3: We use a Support Vector Machine (SVM) with a radial kernel and a "Bag of Words" vectorization of the unstructured article text to boost our algorithm.

Thus it concludes that there is a negative sentiment to this statement, and outputs the following:
["R"] [.996]
The R denotes that the headline is biased towards the Right/Conservative side, while the 0.99 denotes the degree of bias. In this case it is ~99% percent conservatively leaning.
Can you guess who might have published this article?
The answer is: Breitbart News. Breitbart is a well known conservative news outlet, and our program's analysis aligns with the their historically demonstrated ideological bias, heavily right leaning.
Challenges we ran into
One of the more challenging parts of the algorithm, was building a substantial database for the machine learning algorithm to learn from. Each news outlet has their own methods for formatting the articles meaning we had to scrape a variety of webpages and devise a javascript program flexible enough to accommodate all formats. In addition, the limited time meant we only had a small corpus to train our classifier with.
We built our website and server out of javascript and developed our algorithm in python, and ran into problems getting our front end, back end, and algorithm to connect and communicate smoothly and quickly.
Accomplishments that we're proud of
Despite this challenge, as we continued to grow our corpus our accuracy continued to improve until we achieved 65% accuracy classifying unstructured text at the time of submission.
What we learned
None of us had ever built an api in python before, nor an application that runs on runs multiple platforms. Three of our five team members were hackathon rookies and learned how to code in a stack, divide responsibilities, and combine each individual's pieces of code together into a working prototype.
What's next for Bias is Bliss
To advance Bias is Bliss we want to develop a more captivating front end that will draw users and present the findings in a more engaging way, and to grow our corpus for our algorithm to learn from to improve our accuracy.






Log in or sign up for Devpost to join the conversation.