-
-
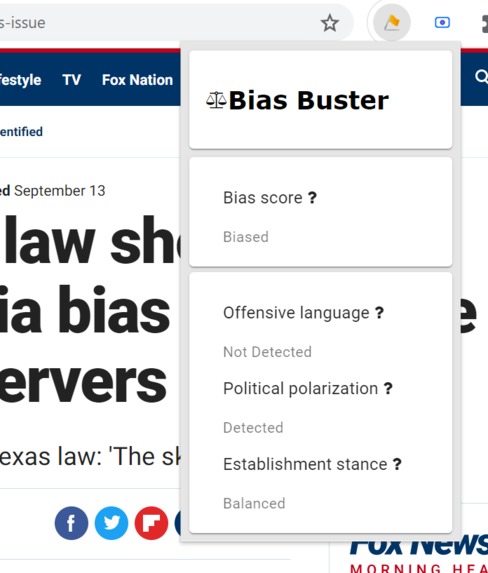
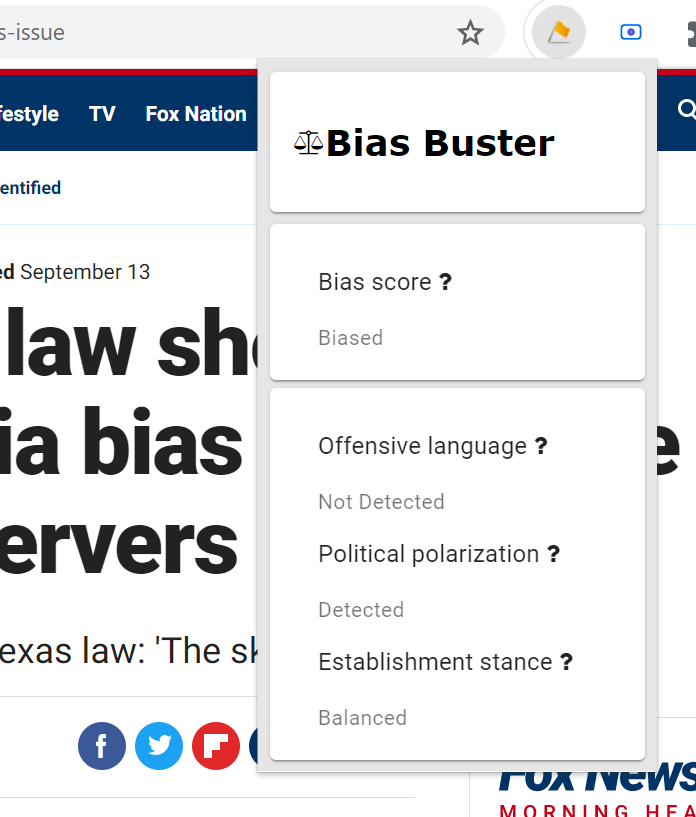
Bias Buster Chrome Extension in action
Inspiration
Since 2005 the number of internet users has increased from 1.1 billion to 4 billion in 2021. The open nature of the internet means four billion voices, opinions, and angles available online and competing for your attention. To make matters worse, powerful people with great influence and resources push their agenda, against the benefit of the average person.
Research shows that media bias is a colossal problem and current solutions are not up to the task. For instance, many media outlets decided to implement fact-checking systems to deal with misinformation. But because those systems are created by the same media outlets, they are subjected to the same biases. To make matters worse, user trust in these solutions is low, because they are not transparent enough.
We are certain that there is a strong need for an independent and data-driven solution that could identify bias, hate speech, and misinformation to alert the user and give her the tools to make an educated judgment about the publication she is exposed to.
What it does
Bias Buster is a data-driven technology that measures the bias of online articles and produces an accessible and simplified report of its findings, alerting the reader to the potential risks. Bias Buster is a convenient Chrome extension, enabling the reader to assess the bias of the article simply by looking at the color of its icon or allowing the user to dive into details by simply clicking on that icon.
We came up with a bias score that assesses the article’s bias in light of the following criteria:
- Balance of viewpoints,
- One-sidedness,
- Misleading information,
- Biased text,
- Strongly biased.
Unfortunately, this does not always paint a full picture of the bias in the article. Therefore, we also provide more specialized measures, such as detection of offensive language, political polarization, and establishment stance.
How we built it
Bias buster consists of a UI client in the form of a Chrome extension and four backend services.
Users of Bias Buster will interact with its Chrome extension. It utilizes the native API provided by the Chrome engine to load the required information about the current page and pass it to a backend service that is responsible for the calculations. After getting a response, the icon of the extension changes color based on the results of the analysis. Later, users can interact with the data by looking at the details that are available in the simple popup. When it comes to technicalities, the frontend part has been implemented using Typescript and Svelte framework that allow rapid prototyping while giving plenty of components out of the box or by utilizing third-party libraries.
All the analysis and bias computation take place in our backend services. We placed the core of the project in a middleware app, which shares an API with the UI client and orchestrates computations. The remaining three apps are called detectors. They are responsible for hosting our machine learning models. There is one machine learning model per application to speed up both the development process and calculations. Detectors only communicate with middleware, which is responsible for aggregating the data and sending it to the UI.
For server capabilities, we used the Flask framework. To coordinate setting up different environments and communications, we used docker-compose. One of the reasons for multiple applications was the different dependencies (and Python versions) that were needed to run models. Thanks to that, we successfully deployed all of our backend services in Azure's virtual machine.
Bias buster uses machine learning models to make predictions. We used three open-sourced (MIT and Apache 2.0 licenses) models:
- HateXplain to measure hate speech
- Longformer to detect political polarization
- UCL’s Fake News Challenge Submission to detect establishment stance The first two use Pytorch and Transformers libraries, and the third one uses Tensorflow.
Challenges we ran into
Our first major challenge was making sure that our predictions were not biased. This was so important, as it is the fundamental difference between our solution and what is available on the market. To accomplish that, we had to carefully analyze the data we trained the models on. We dedicated extensive effort to find models trained on quality datasets. In our case, datasets were labeled by humans, which means they contain some biases. That being said, although it is just a prototype, we firmly believe our solution is a big step in making the process primarily data-driven and getting rid of human-related biases.
When it comes to technical challenges, the biggest one was the Chrome extension. Although the heavy lifting was happening mostly at the backend side, it was the coordination of multiple asynchronous tasks in the extension itself that was causing us a lot of difficulties. As a matter of fact, Chrome provides a lot of possibilities and quite powerful APIs, but as usual with great power comes great responsibility, and to handle the complexity provided by multiple kinds of scripts within the extension is an adventure of its own.
Accomplishments that we're proud of
Combined 3 different machine learning models into one, easily readable and comprehensible result Served 3 models that were trained on big sets of data. Deployed the solution on Azure (thanks to the help from people from Microsoft) Build a Chrome Extension in a new technology that is quite promising and has the potential to be the tool of the future. Provided End to End solution that can be easily extended and used by, so-called, average users.
What we learned
The main lesson that we have learned, as trivial as it sounds, is that finding a proper threshold between biased and unbiased text is quite tricky. While developing our solution, oftentimes we were seeing really unexpected results, like heavy political bias on stackoverflow.com, to establishment stance on football sites. To make things even more complicated, one of our models, designed to explore hate speech, was constantly failing to find any examples of that behavior. Although it makes us happy that there is less and less of that type of content on the Internet, from a technical perspective it was causing us a bit of a problem. Nevertheless, after this exercise, we are even more convinced that automated fact-checking is the area that has quite a lot of potential and the possibilities are virtually endless.
What's next for Bias Buster
We see our prototype as a starting point for a more advanced and user-oriented solution. As we gained the confidence that the idea is promising and can extend into something mature and ready-to-be-used, we see possibilities in adding different types of models that can improve the outcomes and provide users with more detailed information about the website’s content. When it comes to actual frontend opportunities, we would like to provide users with information about, what exactly caused the models to return given data - was it because of the phrasing, the style used, or something else - maybe we would even be able to attach some information as to the actual HTML content!
We managed to bootstrap an “engine” for measuring bias in articles. During the hackathon, we focused on bringing its capabilities to everyday users through a Chrome extension, but we think organizations may benefit from it as well. News sites, website aggregators, blogging platforms, and many others could gain a lot of value from this technology. Especially, as the EU and many states are working on tackling fake news and hateful speech online, our solution can be used by smaller publishers, who do not have the funds to develop their own technology to meet new legal requirements.
Built With
- chrome
- flask
- python
- pytorch
- svelte
- tensorflow
- typescript

Log in or sign up for Devpost to join the conversation.