-

An example from Wikipedia of an unbiased document about abstract mathematical principles.
-

An example of a text with biased language included.
-
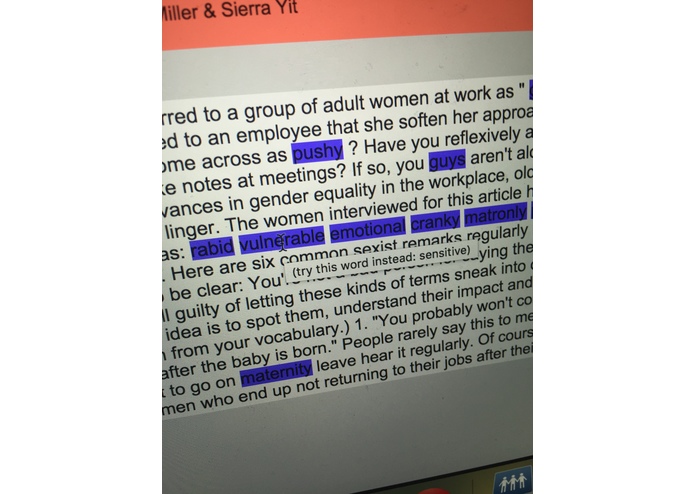
Mousover suggested text of highlighted words



Inspiration
Nobody likes bias, but bias is everywhere. Humans are bad at picking up bias (Recasens et al published on this in http://nlp.stanford.edu/pubs/neutrality.pdf), but machine learning algorithms can detect patterns that we've become blind to - so who better to process our language than an NLP classifier?
What it does
You enter your text into the box on the left, then a classifier assesses your inputs and returns a percentage out of 100 dictating what proportion of your text contains biased language. You also see helpful points on how to moderate your language by mousing over highlighted words to view alternative text suggestions.
How I built it
We take input from the user on the front-end, make a POST request to the Python scripts we wrote, then do some machine learning magic (we trained a statistical classifier on a corpus of biased sources as well as articles from unbiased sources like Wikipedia, which maintains a neutral point of view and edits constantly to maintain it). The classifier and bias measurement scripts return a decimal value that approximately corresponds to how much revision is necessary, then we feed some possible replacements back to the user in the HTTP response.
Challenges I ran into
We had a lot of trouble collecting examples of biased text automatically. While there are plenty of examples out there, categorizing this instantaneously is a challenge (and one we're hoping to tackle with this tool). There are many disagreements on what constitutes bias, and articles discussing unconscious bias aren't, for example, biased (though this can depend on the author and specific writing). Scraping the text of the URLs that we collected consistently got us banned from websites because we are 'robots.' We were able to work around this by seeking a diversity of sources from many websites. Finally, integrating the front and back ends is always nerve-wracking, but it was really exciting and rewarding to see it all come together.
Accomplishments that I'm proud of
After participating in FemmeHacks last year, we reunited to take on a very nuanced and technically complicated project. We made use of supporting libraries, but we built each piece of this ourselves -- the crawler, the scraper, the classifier, the scoring, and everything you see in front of you. We've come a long way in the last year, especially in our Python, JS, and jQuery skills.
What I learned
String encoding is more complicated than one would expect! The internet is an inconsistent place (in string encodings and in points of view). It's easy to get banned from news websites.
What's next for Bias Buster
We'd love to further empower users by allowing manual curation of data. If you know you have a blind spot that we haven't picked up on yet, you could add your own keywords and paraphrases and see them in future revisions.
We'd also like to collect and train on more user inputs, provide a gmail plug-in, and address other types of bias (and extend our feedback to resources that can explain why words were flagged). This is a great way to make the workplace more professional and make people more conscious of their word choices.
Built With
- beautiful-soup
- css3
- flask
- git
- github
- html5
- javascript
- jquery
- markup
- numpy
- scipy
- sklearn
- urllib2


Log in or sign up for Devpost to join the conversation.