-
-
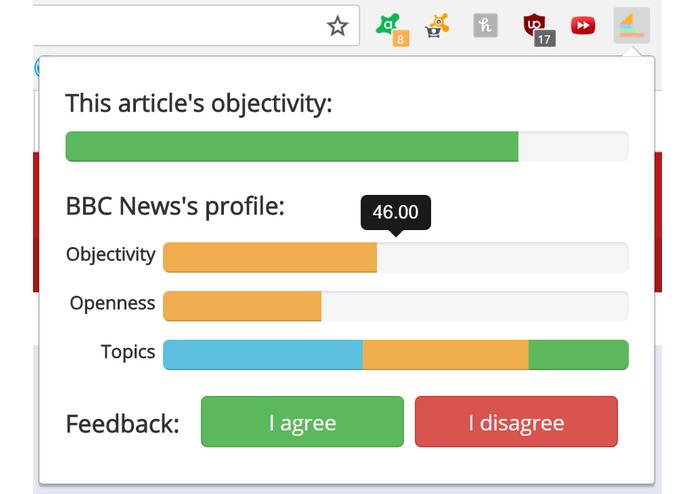
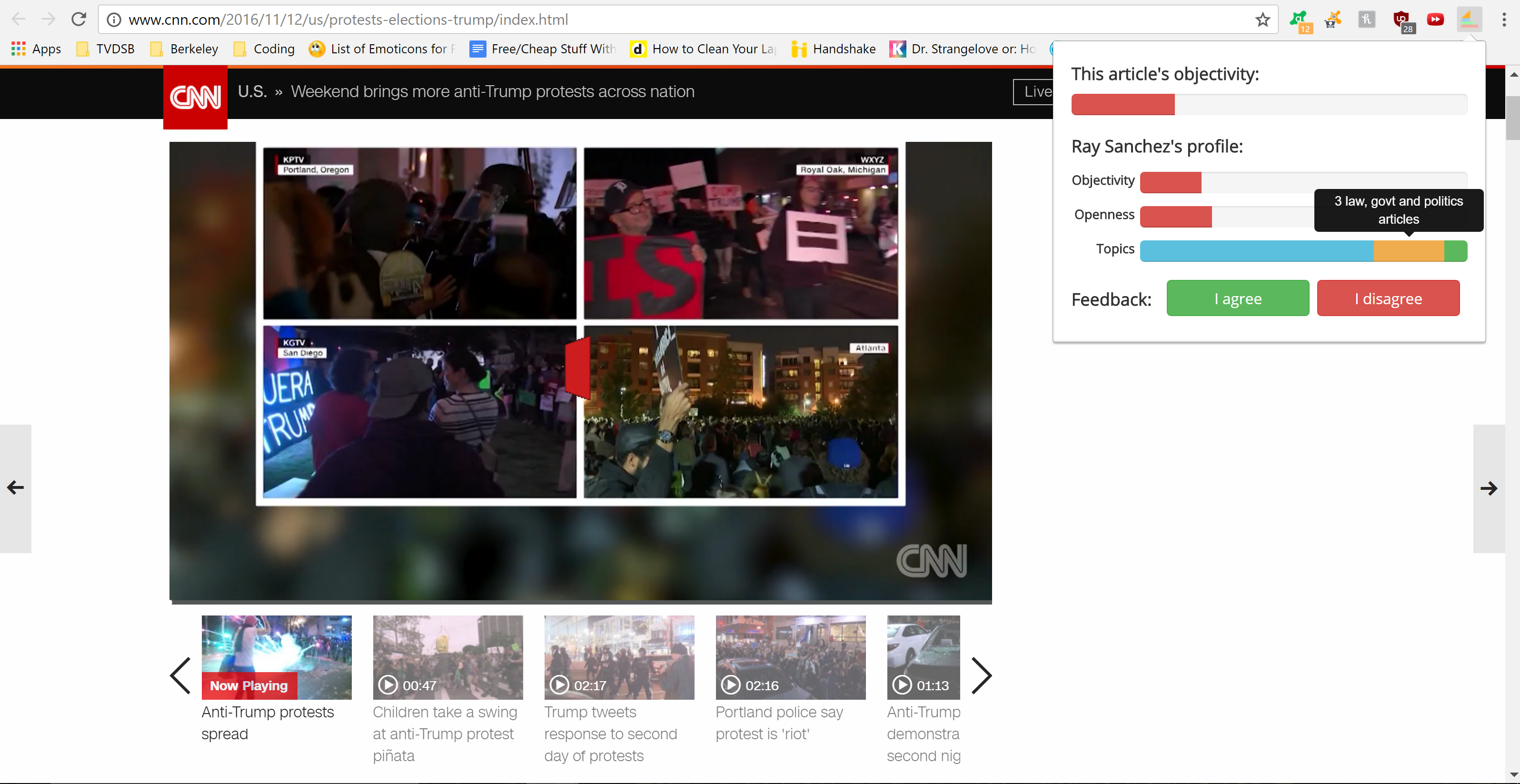
Close-up of pop-up
-
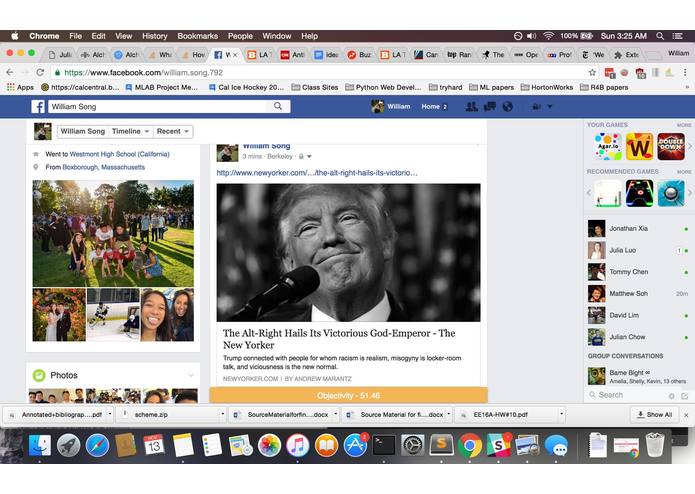
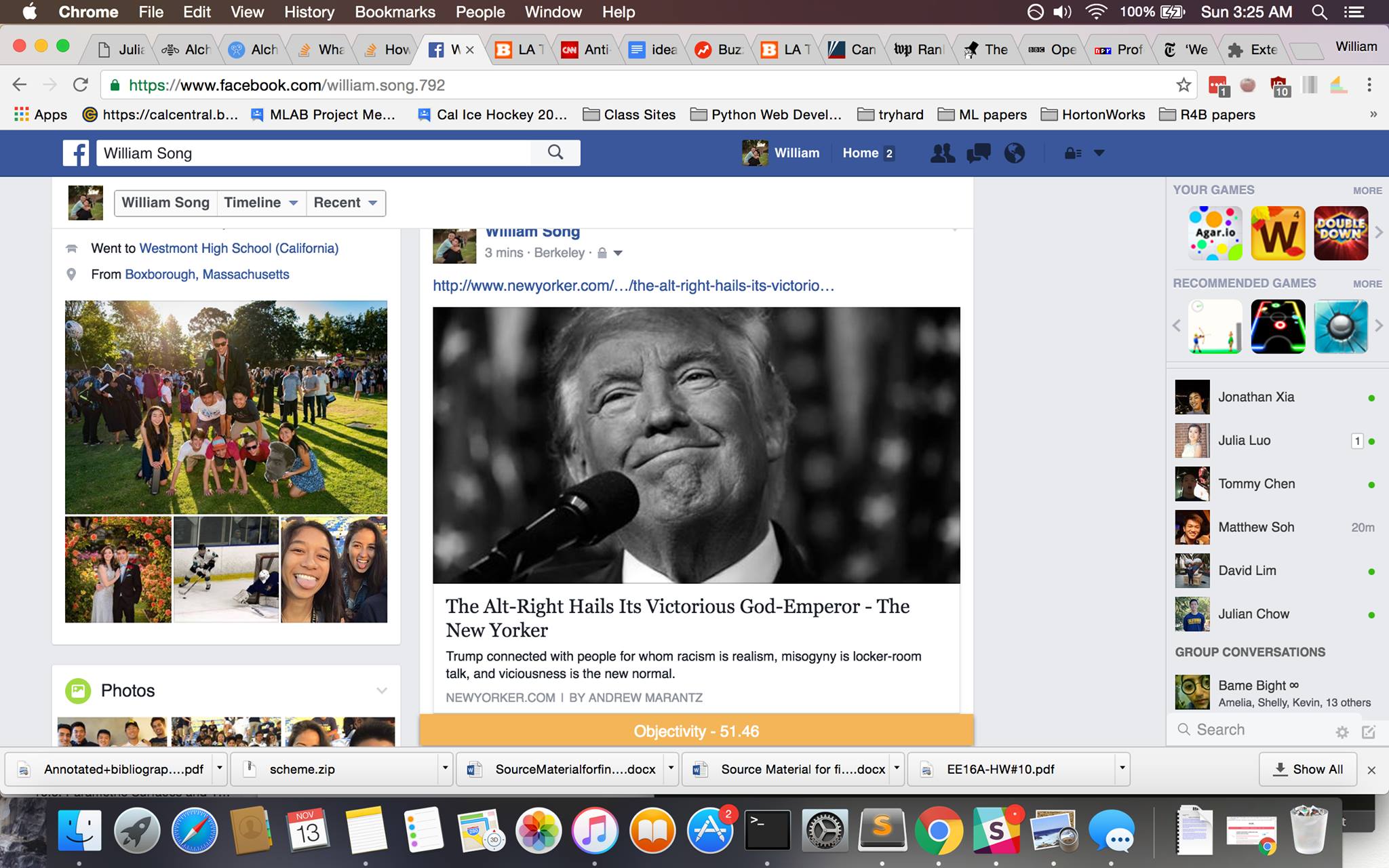
Facebook real-time analysis
-
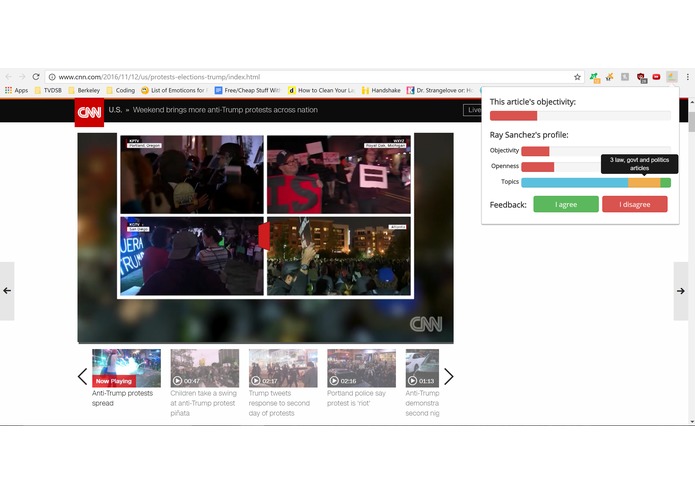
Extension pop-up
Inspiration
November 9th was an eventful day for all, and likely a day that will go down in history. Regardless of which side one is on, there are many lessons that must be learned. We saw the power of the media firsthand, as journalists published article after article in a deluge of political news, rhetoric and prediction, a chaotic echo chamber that did no one any good. We want to raise the standard of journalistic integrity, and remind everyone of how easily we can be biased and swayed. That inspired us to build Ethos, an automated tool that analyses the words we consume. It’s easy for humans to be unobjective, and so we hope that the unbiased rationality of computers can be brought in to counter our inherently tinted lenses.
What it does
Ethos is a Chrome extension created to analyze articles for their level of objectivity or bias using natural language processing elements from the IBM Watson API. Additionally, data is searched and compiled from previous articles written by the same author in order to deliver a general report on the author’s bias, openness to different perspectives, and topics of focus. User-interactivity was incorporated through a Facebook scraper that analyzes articles at real-time while scrolling through a news feed.
How I built it
There are two main parts to the project, the client-side Chrome extension, and the Flask API server it contacts. The Chrome extension was written largely in HTML/CSS/JS, doing client-side retrieval of document analysis via the IBM AlchemyLanugage API for low-latency display of data e.g. in the facebook feed. For more involved data processing, the Chrome Extension made AJAX requests to a Flask server hosted on Heroku. The Flask server was responsible for processing authors, aggregating their works, doing personality analysis and incorporating feedback. Authors were extracted via the AlchemyLanguage API and we used the AlchemyDataNews API to search for their past writing, before judging their overall objectivity. To avoid excessive API calls, authors and articles were cached on server in a Postgres database. We used the IBM Watson Personality Insights API to evaluate author personalities for added insight, while accumulating the various taxonomies of an author’s body of work to assess how knowledgeable and familiar they were with a specific area. We also used the Diffbot API to detect if a page contained an article.
Challenges I ran into
The main challenge during this project was manipulating the raw data from the Watson API and displaying it in a user-friendly form. We spent a considerable amount of time trying to represent the intangibility of bias and objectivity in a succinct but also intuitive way, finally settling on a series of elegant bars. Another problem was the detection of articles and the absence of author data, which we detected by running test cases and solved by dispatch bulletproofing.
Accomplishments that I'm proud of
We’re proud of the fact that we were able to pool together our respective skills and develop a product that could potentially bring around change regarding an issue that we all felt strongly about. From dealing with minor issues by consulting each other and friends, waiting through long lines to grab food and snacks, to overcoming huge project workflow hurdles by chalkboarding out large diagrams, we’re proud to say that the project—and us—all came together at the end.
What I learned
We all developed both technical and non-technical skills during the process of this hackathon. In terms of technical skills, we all definitely learned more about website development, specifically JQuery, Flask, and SQL. In terms of soft skills, we learned to collaborate with each other and work with each other’s strengths and weaknesses in order to create with a coherent final product.
What's next for Ethos
We would like to integrate with more social media sites like Twitter and Reddit. Also, we could work on improving the accuracy of article detection and streamline the bulletproofing for cases where Watson has a difficult time analyzing the data. We also want to find ways to compile information from a larger data set without putting such a heavy stress on the Watson Alchemy system. Lastly, we hope to crowdsource more evaluations of objectivity to refine the classifier.








Log in or sign up for Devpost to join the conversation.