-
-
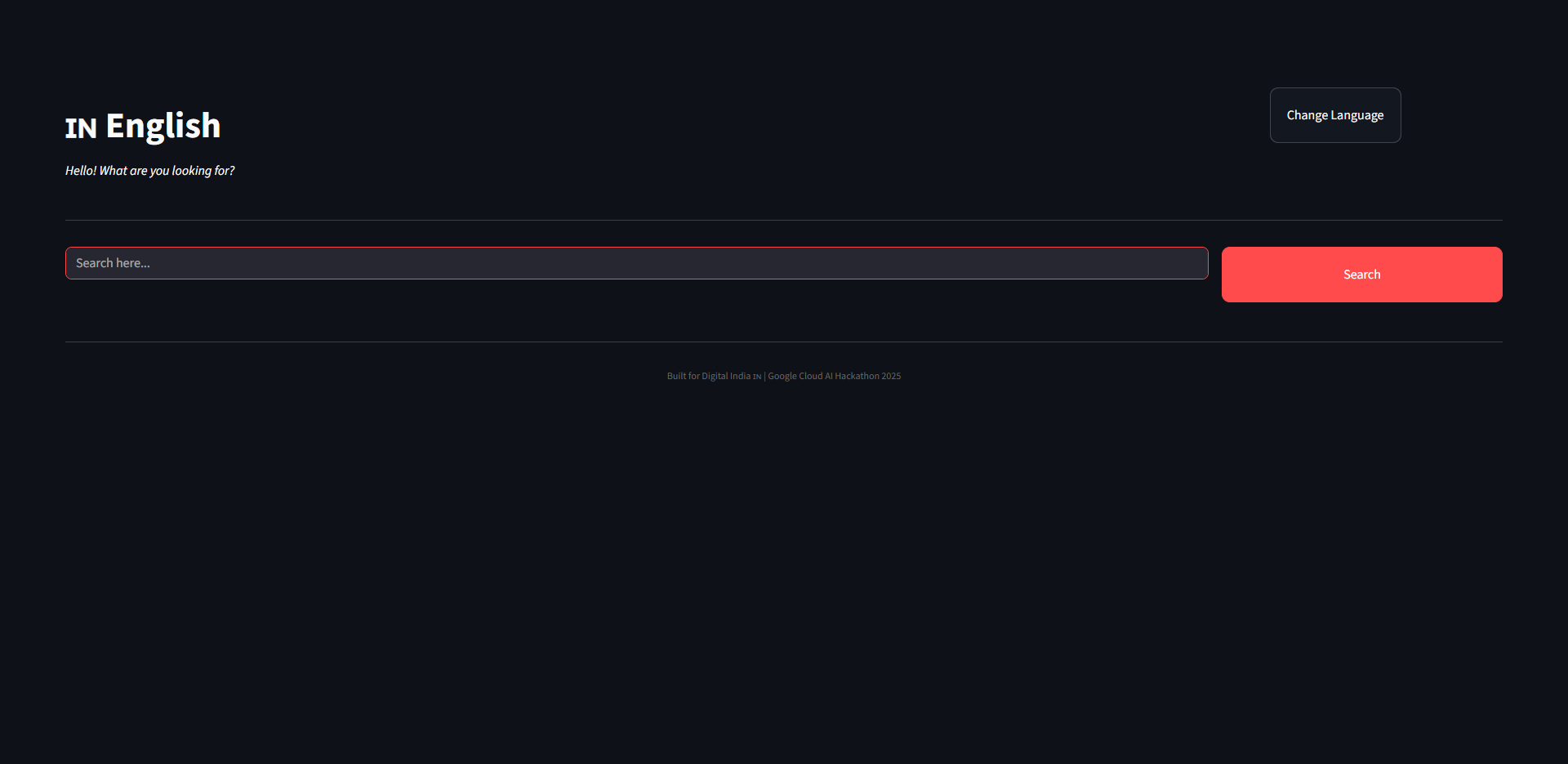
Home
-
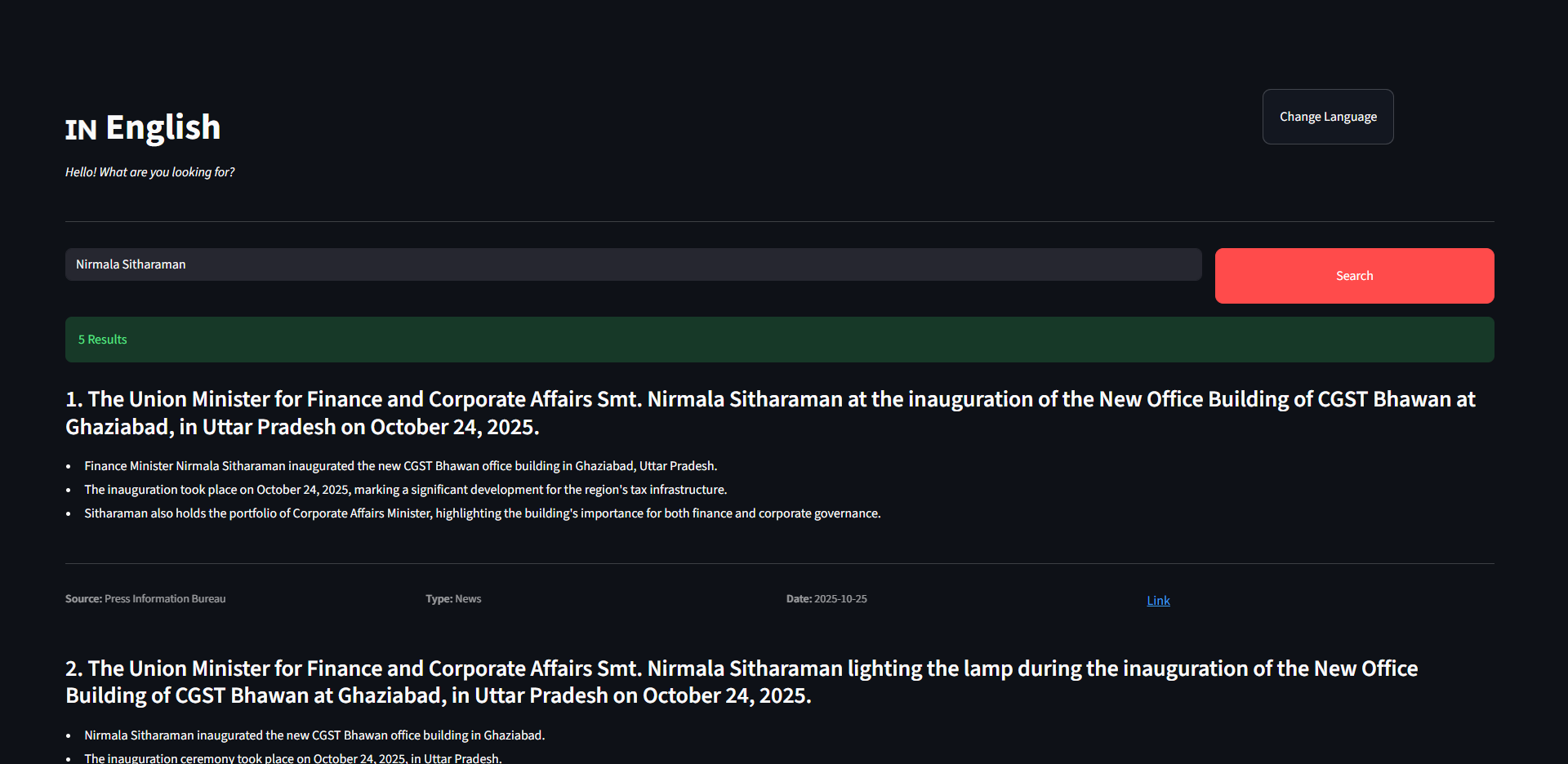
Searching in English
-
Home
-
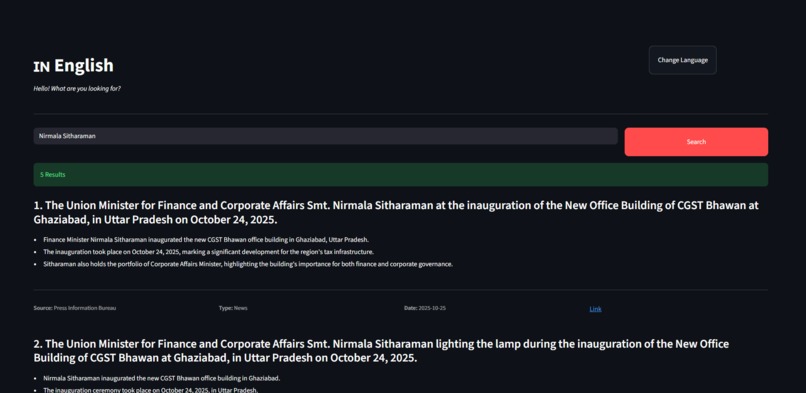
Search in English successful
-
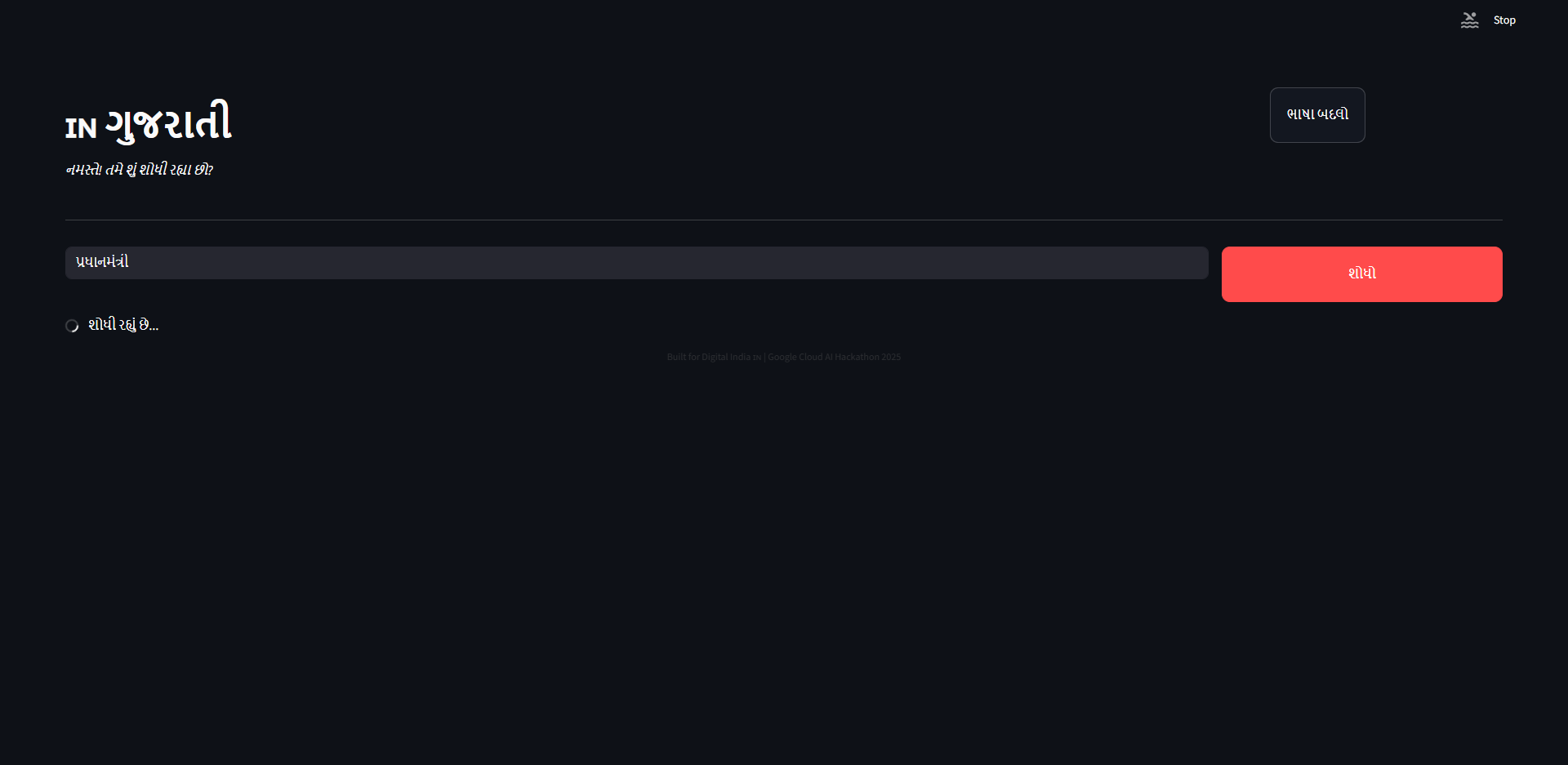
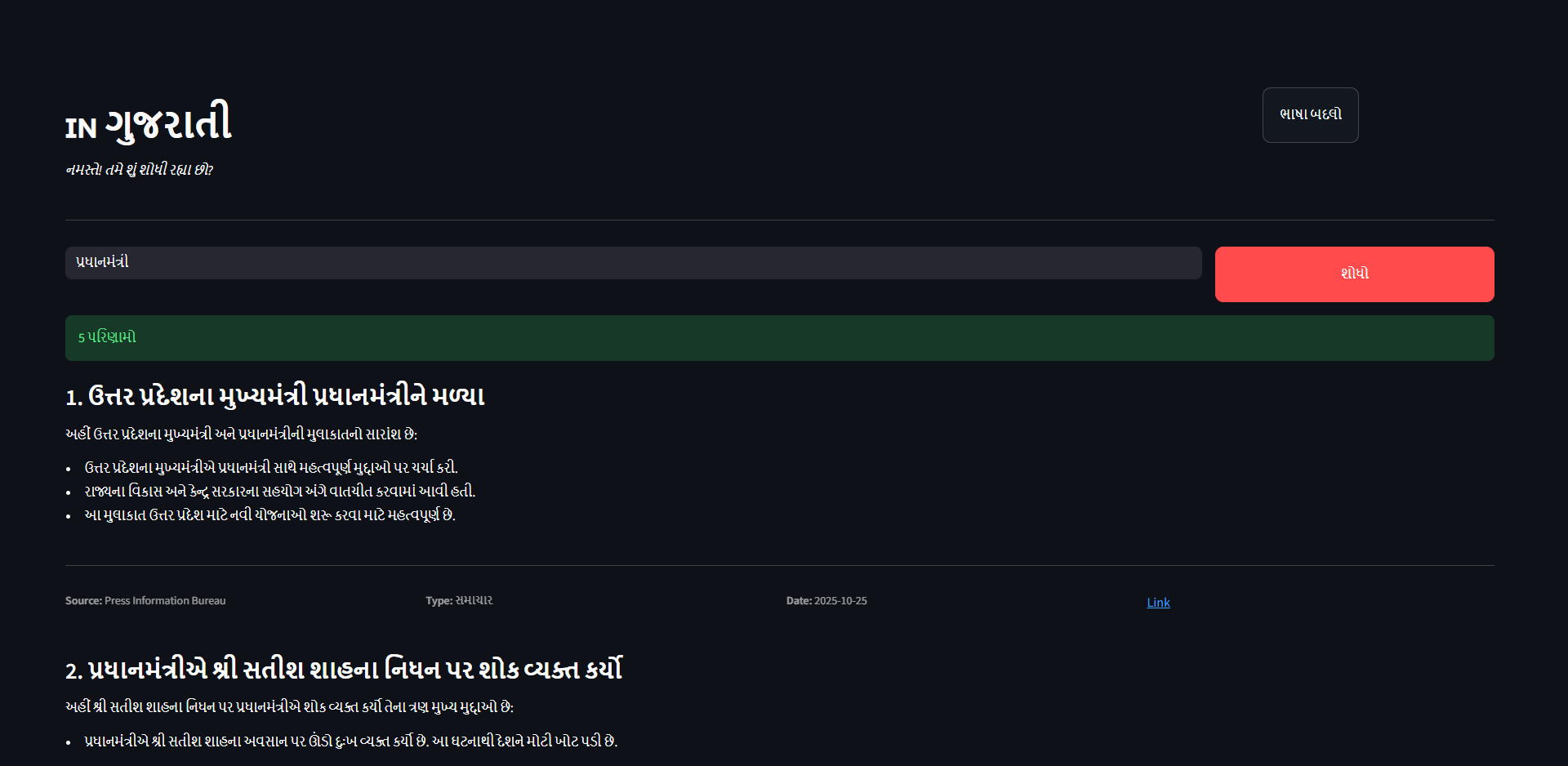
Searching in Gujarati
-
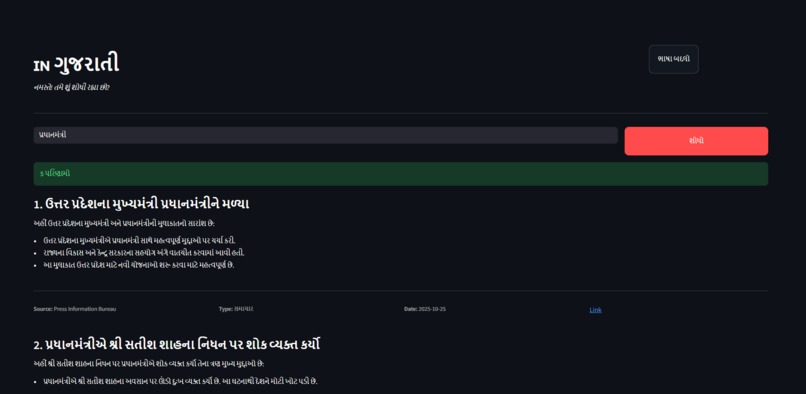
Search in Gujarati successful
-
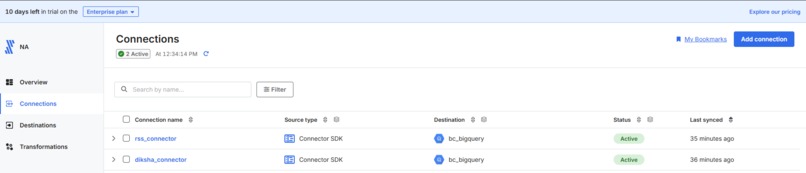
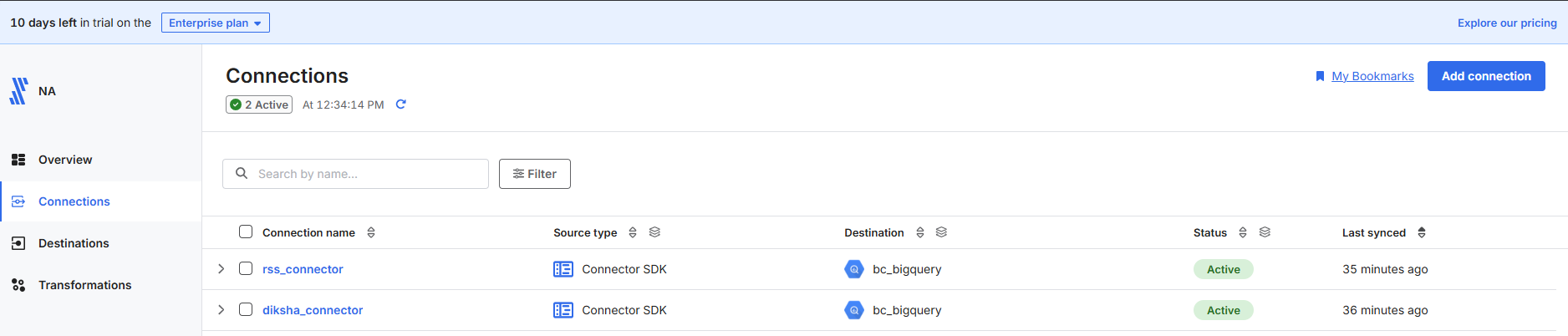
Connectors in Fivetran
-
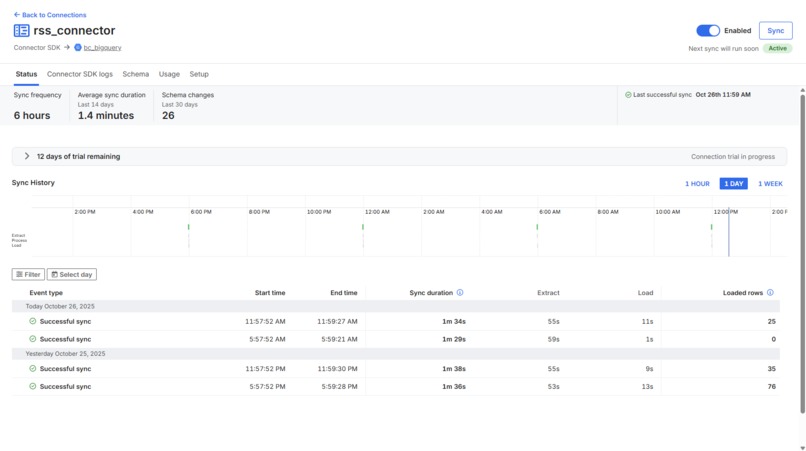
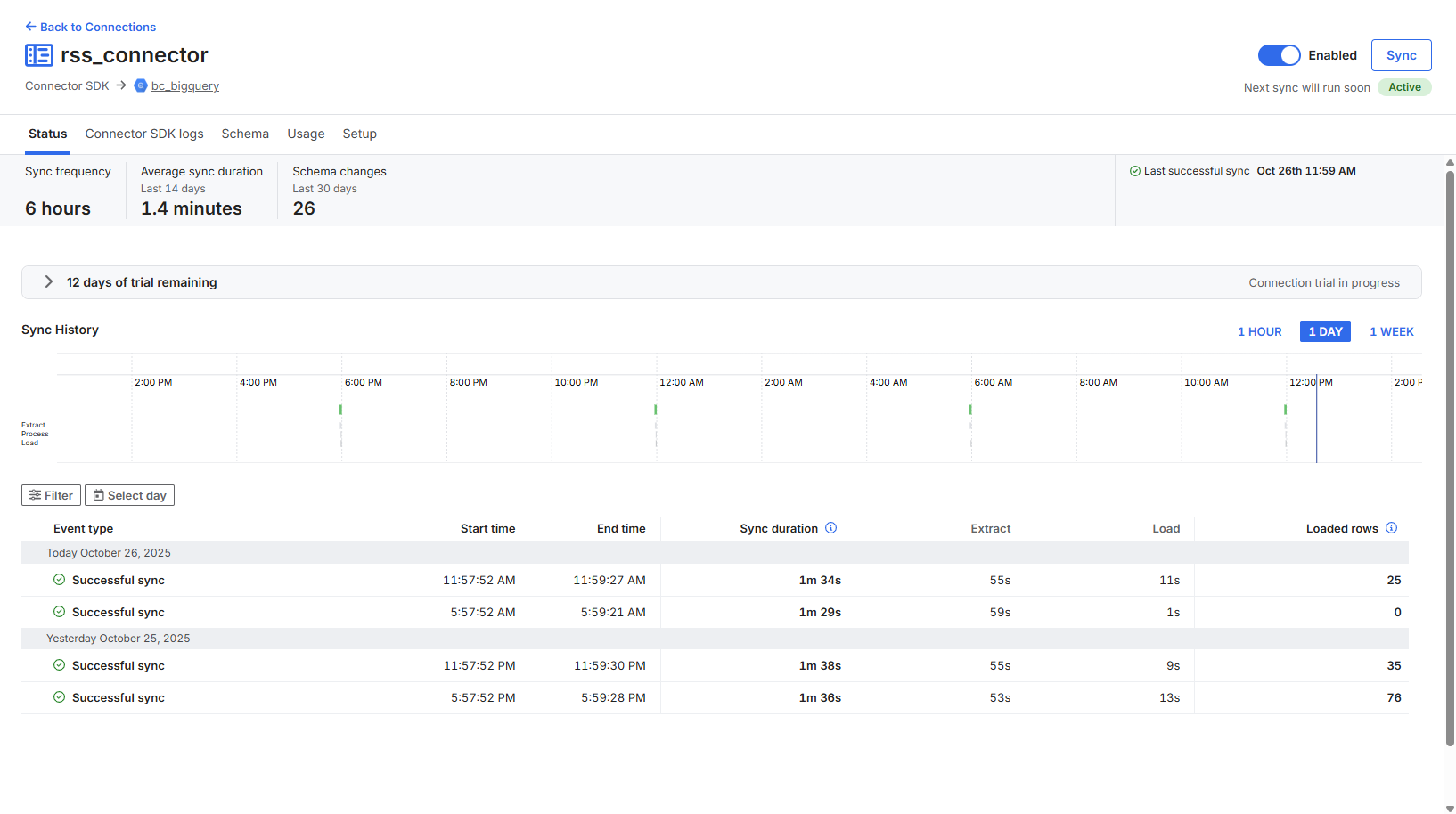
RSS Feed Connector
-
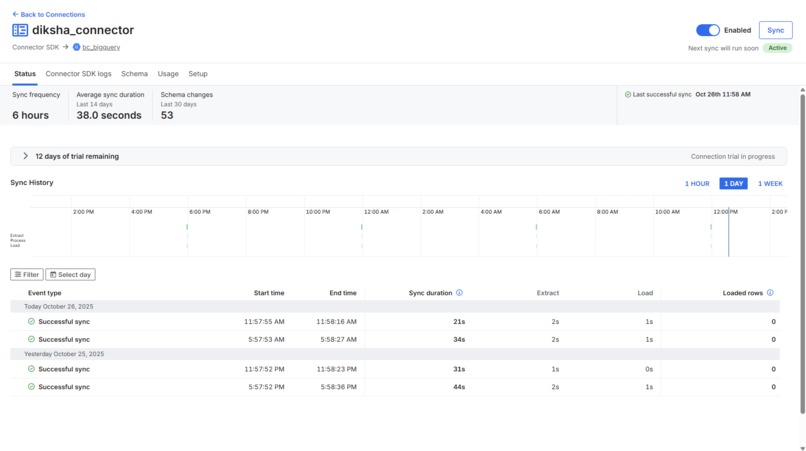
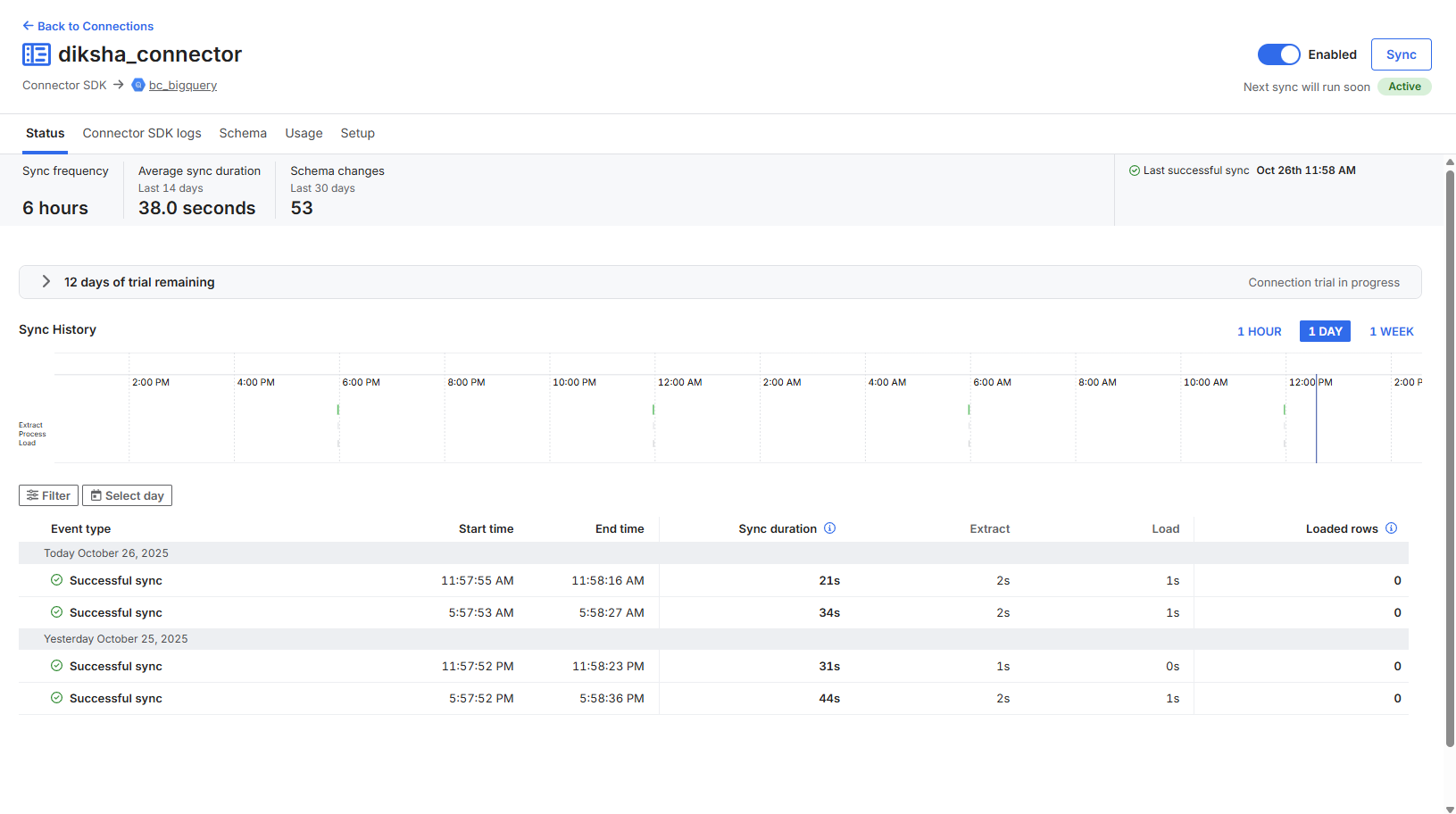
Diksha Data Connector
-
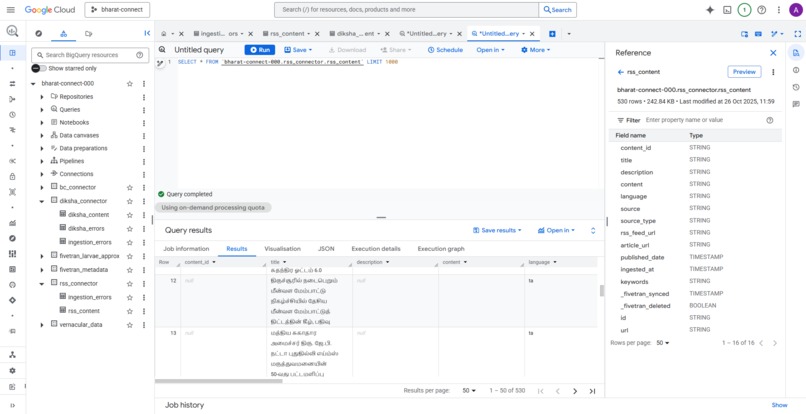
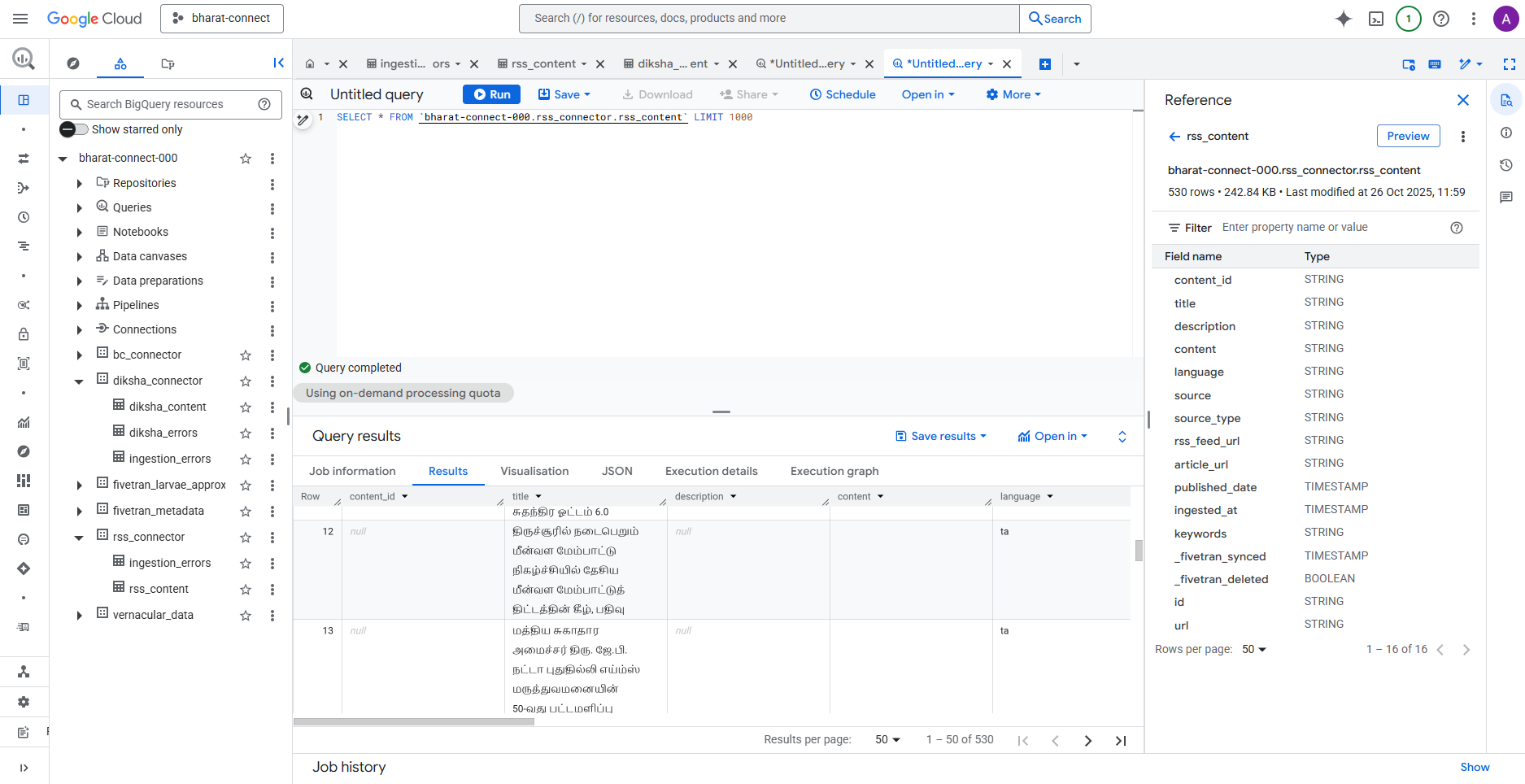
RSS Table in BigQuery
-
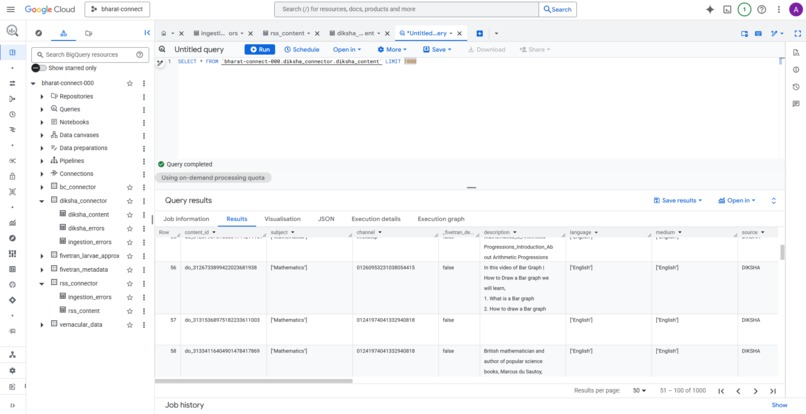
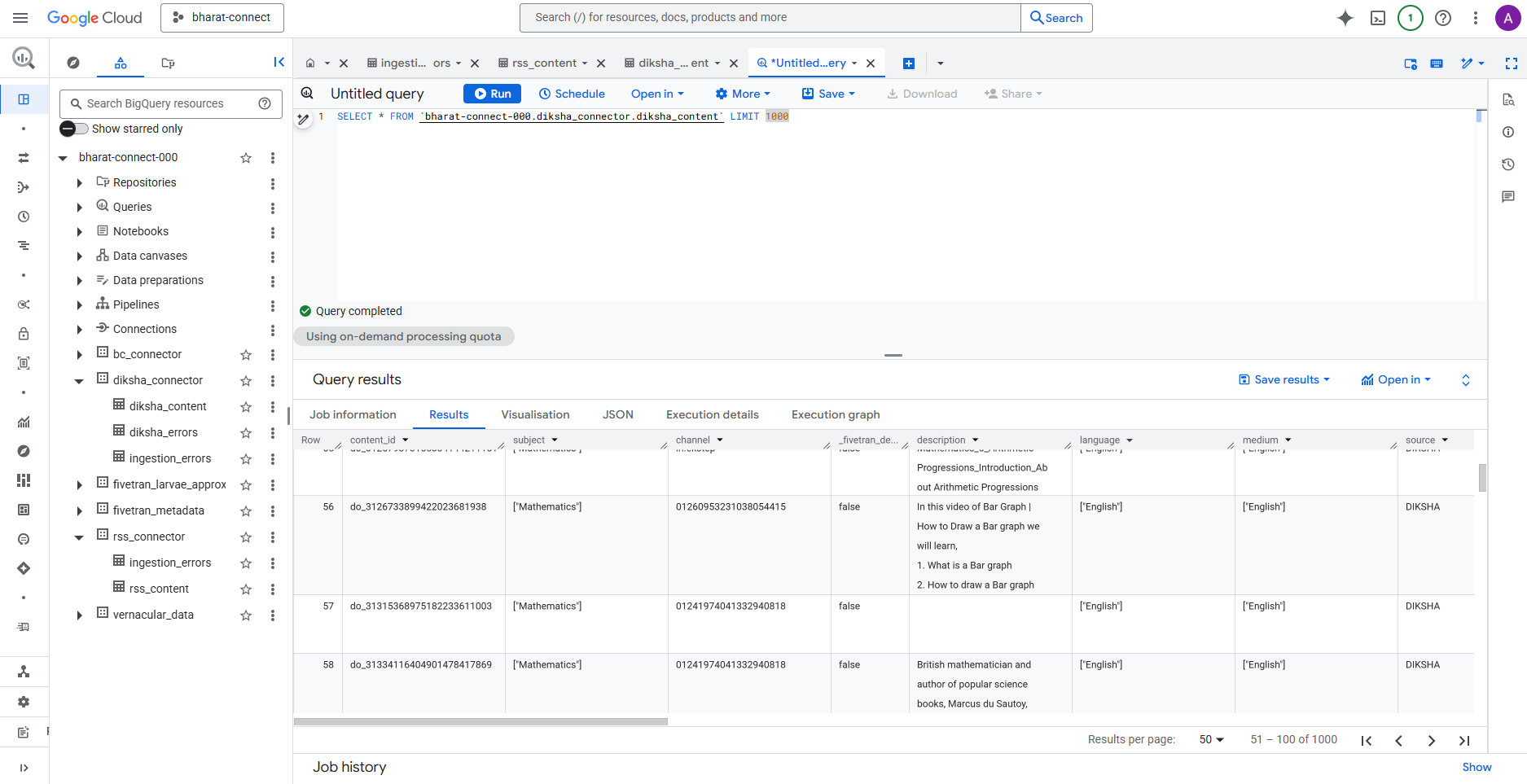
Diksha Table in BigQuery
Inspiration
India is home to 22 official languages and over 1,600 dialects, making it one of the world's most linguistically diverse nations. Yet, this diversity has created a digital divide—government announcements in Hindi don't reach Telugu speakers, educational resources in English remain inaccessible to rural students studying in their native languages, and critical information gets siloed by language barriers.
During the recent pandemic, I witnessed firsthand how language barriers prevented millions from accessing crucial health information. A farmer in Tamil Nadu couldn't understand government schemes announced in Hindi. A student in West Bengal struggled to find NCERT resources in Bengali. This linguistic fragmentation inspired me to build BharatConnect—a platform that breaks down these barriers using AI.
My vision: Every Indian, regardless of their language, should have equal access to government information and educational resources.
What it does
BharatConnect is an AI-powered cross-language content discovery platform that automatically ingests, indexes, and translates government news and educational content across 10 Indian languages.
Key Features:
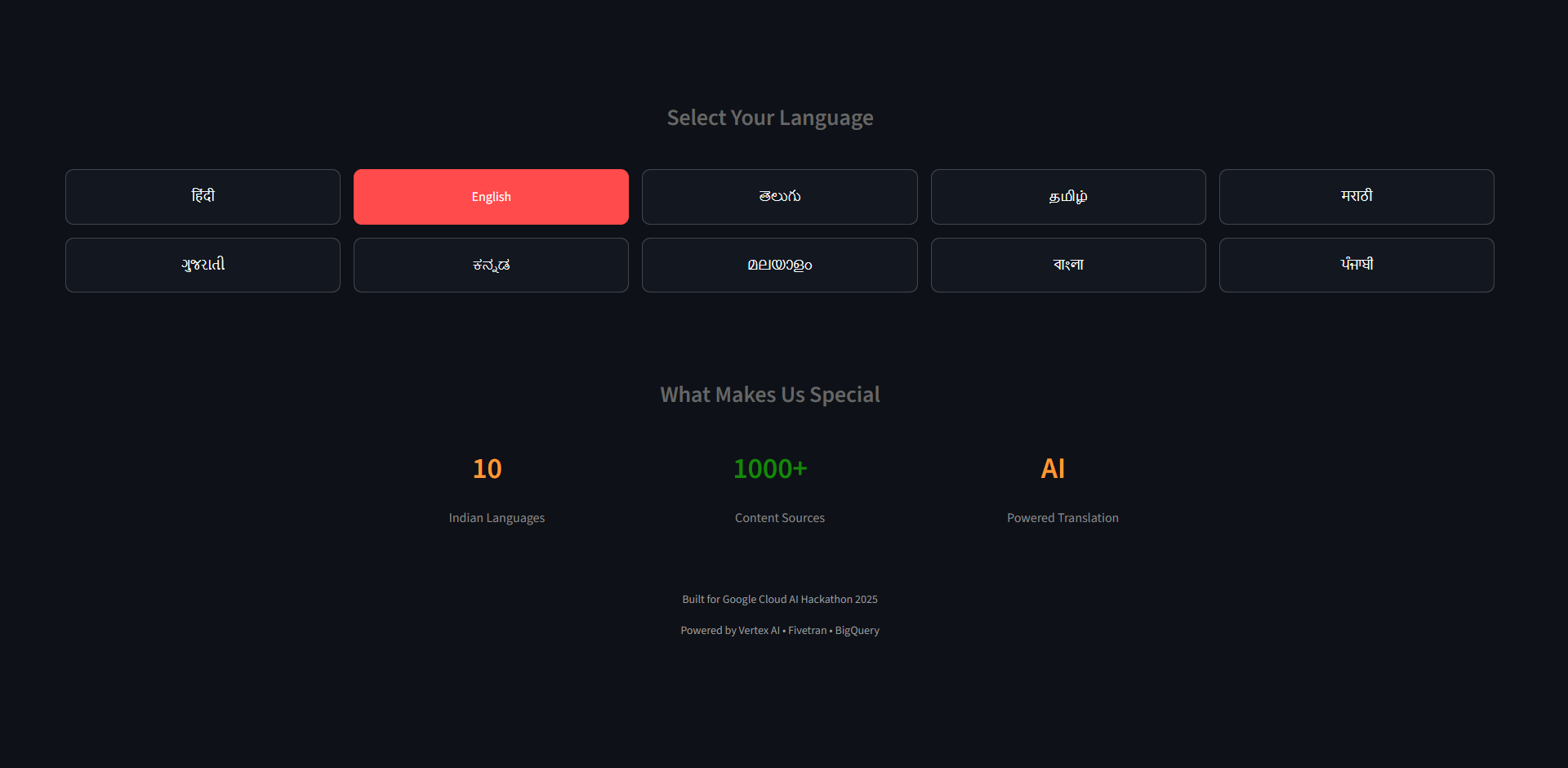
1. Cross-Language Search
- Search in Hindi, discover results in Telugu—seamlessly
- AI automatically translates and summarizes content from any language
- Supports Hindi, English, Telugu, Tamil, Marathi, Gujarati, Kannada, Malayalam, Bengali, and Punjabi
2. Dual Content Sources
- Government News: Press Information Bureau (PIB) RSS feeds across regional offices
- Education: DIKSHA platform's vast repository of NCERT textbooks and educational materials
3. Smart Translation & Summarization
- Powered by Google's Gemini 2.0 Flash model
- Generates 3-bullet summaries for quick comprehension
- Indicates original language and translation status
4. Automated Data Pipeline
- Multi-agent system discovers and validates RSS feeds daily
- Fivetran connectors sync data to BigQuery automatically
- Real-time updates ensure fresh, relevant content
5. Interactive UI
- Beautiful language-circle visualization
- Filter by content type (News/Education)
- Language-specific or cross-language search modes
How I built it
BharatConnect is built as a 5-layer architecture with complete automation:
Layer 1: Data Ingestion
Multi-Agent System (MAS) for RSS Feeds
5 specialized agents working in coordination:
- Intelligent Feed Agent: Discovers RSS feeds using web scraping
- Validator Agent: Validates content quality and feed consistency
- RAG Agent: Retrieval Augmented Generation for pattern recognition
- Learning Agent: Learns from historical patterns
- Coordinator: Orchestrates all agents with state management
DIKSHA Discovery Agent
- Scrapes educational content from DIKSHA public API
- Batch processing with rate limiting
- Multi-language content classification
Layer 2: ETL & Data Warehouse (Fivetran-Powered)
Why Fivetran Was Essential
BharatConnect's architecture centers around Fivetran as the bridge between dynamic content sources and BigQuery. Here's why Fivetran was critical:
- Automated Sync Reliability: Government RSS feeds update unpredictably—Fivetran's scheduling ensures we never miss updates
- Schema Evolution: As RSS feeds add new fields, Fivetran automatically adapts our BigQuery schema
- Incremental Updates: Only syncs new/changed content, preventing duplicate data and reducing costs
- Built-in Monitoring: Track sync status, failures, and data quality issues in real-time
- Zero Infrastructure: No servers to manage—critical for a solo developer building at scale
Custom Python Connectors
I built two custom Fivetran connectors using the Fivetran SDK:
1. RSS Multi-Feed Connector
- Dynamic feed list from MAS discovery output
- Deduplication by (source, url, published_date)
- Language detection and normalization
- Error handling for malformed XML
- Cursor-based incremental sync using
ingested_attimestamp
Schema: 16 fields (id, title, content, description, language, source, url, published_date, etc.)
2. DIKSHA Educational Content Connector
- Batch API calls with rate limiting
- JSON field normalization (language, grade, subject as arrays)
- Content-type filtering (textbooks and courses only)
- Metadata enrichment (board, medium of instruction)
- Full refresh mode for data consistency
Schema: 20 fields (content_id, title, description, board, grade_level, subject, language, diksha_url, etc.)
Automated Connector Deployment
The beauty of BharatConnect's architecture is fully automated ETL:
- MAS discovers 50+ RSS feeds across 10 languages
- Generator script reads discovery JSON and generates Fivetran connector Python code
- Deployment script pushes connector to Fivetran via API
- Fivetran schedules sync (every 6 hours for RSS, daily for DIKSHA)
- BigQuery receives fresh data without any manual intervention
BigQuery Data Warehouse
Fivetran syncs data to two normalized BigQuery tables:
Table 1: rss_content (News & Announcements)
- Partitioned by
published_date, clustered bylanguageandsource - Handles single-language articles
Table 2: diksha_content (Educational Resources)
- Partitioned by
created_on, clustered byboard - JSON fields for multi-value attributes (language, grade, subject)
Layer 3: AI & Search
BharatConnect Agent
- BigQuery Search Tool: Multi-source federation across RSS and DIKSHA tables
- Translation Tool: Gemini AI with 30s rate limiting to respect API quotas
- Summarization Tool: Generates 3-bullet summaries in user's language
- Graceful Fallback: Tries user's language first, then expands to all languages
Layer 4: User Interface
Streamlit Web Application
- Interactive language-circle visualization
- Real-time search across both data sources
- Translation indicators and multi-bullet summaries
- Deployed on Streamlit Cloud with Google Cloud secrets management
Layer 5: Automation
Daily Scheduler (APScheduler)
Runs every midnight:
- Execute RSS Feed MAS
- Run DIKSHA Discovery
- Generate Fivetran connectors
- Deploy to Fivetran
- Auto-sync to BigQuery
Tech Stack:
- Backend: Python 3.12, Multi-Agent Framework
- AI/ML: Google Vertex AI (Gemini 2.0 Flash)
- Data Warehouse: Google BigQuery
- ETL: Fivetran (custom Python SDK connectors)
- Frontend: Streamlit
- Automation: APScheduler
Why Fivetran Was Game-Changing
As a solo developer with limited time, Fivetran eliminated entire categories of problems:
Without Fivetran (Traditional Approach):
- ❌ Build custom ETL scripts for each data source
- ❌ Handle connection failures and retries manually
- ❌ Monitor pipeline health 24/7
- ❌ Manage incremental sync logic and state
- ❌ Deal with schema changes breaking pipelines
- ❌ Scale infrastructure as data grows
- Estimated effort: 2-3 weeks + ongoing maintenance
With Fivetran:
- ✅ Write connector code once, Fivetran handles everything else
- ✅ Automatic retries and error handling
- ✅ Built-in monitoring dashboard
- ✅ State management handled by platform
- ✅ Schema evolution automatic
- ✅ Zero infrastructure to manage
- Actual effort: 3 days (connector development) + 0 maintenance
Real Impact: This freed me to focus on the AI and user experience—the parts that actually differentiate BharatConnect. Fivetran didn't just save time; it made the project possible within hackathon constraints.
Challenges I ran into
1. Multi-Language Schema Complexity
- Problem: RSS has single-language per article (
language: "hi"), while DIKSHA has multi-language content (language: ["en", "hi", "te"]). - Solution: Implemented flexible JSON handling in BigQuery queries using
TO_JSON_STRING()and conditional parsing based on table type.
2. Translation API Rate Limiting
- Problem: Gemini API has strict rate limits—hitting them caused search failures.
- Solution: Implemented configurable 30s delays between calls and exponential backoff for retries. Added graceful degradation—if translation fails, display original content with language indicator.
3. Cross-Language Search Accuracy
- Problem: Translating query terms before search gave poor results (e.g., "Diwali" → "दिवाली" missed English content).
- Solution: Search in original query language first, then expand to all languages. AI translates results on-the-fly rather than pre-translating queries.
4. DIKSHA API Data Quality
- Problem: DIKSHA API returned incomplete metadata, duplicate entries, and inconsistent language tags.
- Solution: Built robust validation in discovery agent—filtered out empty descriptions, deduplicated by
content_id, normalized language codes.
5. Fivetran Connector Generation
- Problem: Dynamic connector generation required understanding Fivetran SDK's schema requirements and sync modes.
- Solution: Created template-based generators that read discovery JSONs and automatically generate valid connector code with proper schema mapping and cursor management.
6. Agent Coordination in MAS
- Problem: 5 agents needed to work in sequence without blocking each other.
- Solution: Implemented coordinator pattern with state management and message passing between agents.
Accomplishments that I'm proud of
- True Production-Ready System: Not just a prototype—complete with automation, error handling, logging, and scheduled updates.
- Multi-Agent Intelligence: Built a sophisticated MAS that learns and adapts feed sources over time.
- Cross-Language AI: Successfully implemented semantic search that works across 10 Indian languages seamlessly.
- Social Impact Scale: Potentially serving 1.4 billion Indians by breaking language barriers to critical information.
- Clean Architecture: 5-layer separation of concerns makes the system maintainable and extensible.
- BigQuery Federation: Unified search across heterogeneous data sources (news + education) with different schemas.
- Production-Grade ETL: Built custom Fivetran connectors with proper error handling, incremental sync, and automated deployment—not just "hackathon code."
- Zero Manual Intervention: Entire pipeline runs autonomously—discovery, ingestion, transformation, and serving.
What I learned
Technical Learnings:
Multi-Agent Systems Design
- Learned coordination patterns for autonomous agents
- Understood trade-offs between centralized vs. distributed control
- Implemented effective state management across agents
AI Translation Limitations
- Not all Indian languages have equal AI model quality
- Context matters—domain-specific vocabulary needs careful handling
- Rate limiting is critical for production AI applications
BigQuery Optimization
- JSON fields in BigQuery require special indexing strategies
- Cross-table queries need careful query planning
- Partitioning by date significantly improves performance
Fivetran SDK Mastery
- Custom connectors require understanding sync modes (incremental vs. full)
- Schema evolution needs to be handled gracefully
- Cursor-based pagination is more reliable than offset-based
- State management is handled by Fivetran's platform
ETL Pipeline Resilience
- Idempotency is crucial—pipelines must handle reruns
- Checkpointing prevents data loss during failures
- Monitoring and alerting are not optional
Domain Learnings:
India's Linguistic Complexity
- Script differences (Devanagari, Telugu, Tamil, etc.) add complexity
- Regional variations within same language require normalization
- English-Indian language mixing (code-switching) is common
Government Data Landscape
- PIB has structured RSS feeds but inconsistent metadata
- DIKSHA's API is powerful but poorly documented
- Both sources require aggressive cleaning and validation
Educational Content Access
- Students struggle to find resources in their medium of instruction
- Language is the primary barrier to digital education in rural India
- Cross-language discovery can democratize access
Human-Centered Learnings:
User Experience for Multi-Lingual Interfaces
- Users prefer searching in their native language
- Translation indicators build trust
- Summaries reduce cognitive load for cross-language content
Accessibility is Not Optional
- Breaking language barriers is a fundamental right
- Technology can and should bridge divides, not widen them
- Simple solutions (like summaries) have massive impact
What's next for BharatConnect
Short-Term:
Expand Language Support
- Add remaining 12 official Indian languages
- Include regional dialects (Bhojpuri, Awadhi, etc.)
More Data Sources
- State government portals (all 28 states + 8 UTs)
- NCERT, CBSE, State Boards directly
- SWAYAM MOOCs and NPTEL lectures
Enhanced AI Features
- Voice search in Indian languages
- Text-to-speech for accessibility
- Video transcription and translation
Mobile Application
- Android app for rural penetration
- Offline mode for low-connectivity areas
- SMS-based query interface
Mid-Term:
Personalization Engine
- Learn user preferences and content patterns
- Recommend relevant content across languages
- Smart notifications for important announcements
Community Features
- User-contributed translations (crowd-sourcing)
- Q&A forum for educational content
Analytics Dashboard
- Track language coverage and gaps
- Monitor translation quality
- Identify trending topics across languages
Long-Term:
AI-Powered Explainability
- Simplify complex government schemes
- Explain educational concepts in native language
- Generate practice questions for students
Partnerships
- Collaborate with state governments for official integration
- Partner with NGOs working in rural education
- Work with telecom providers for zero-rated access
Expand Beyond India
- Adapt for other multilingual nations (Bangladesh, Pakistan, Nepal)
- Support ASEAN languages (Thai, Indonesian, Vietnamese)
- Global platform for linguistic inclusion
My Ultimate Vision:
"A linguistically inclusive India where every citizen, regardless of their mother tongue, has equal access to information, education, and opportunity."
BharatConnect is just the beginning. I envision a future where language is no longer a barrier to progress, where a farmer in Punjab can access the same information as a software engineer in Bangalore, where a student in Assam has the same educational resources as one in Mumbai—all in their own language.
Join me in building a truly connected Bharat. 🇮🇳
Built With
- api
- artificial-intelligence
- automation
- bigquery
- data-warehouse
- etl-pipeline
- fivetran
- gemini
- google-cloud
- json
- machine-translation
- multi-agent-system
- natural-language-processing
- python
- rss
- sql
- streamlit
- vertex-ai
Log in or sign up for Devpost to join the conversation.