-
rag-response
-
vector embeddings
-
Chatbot
-
frontPage
-
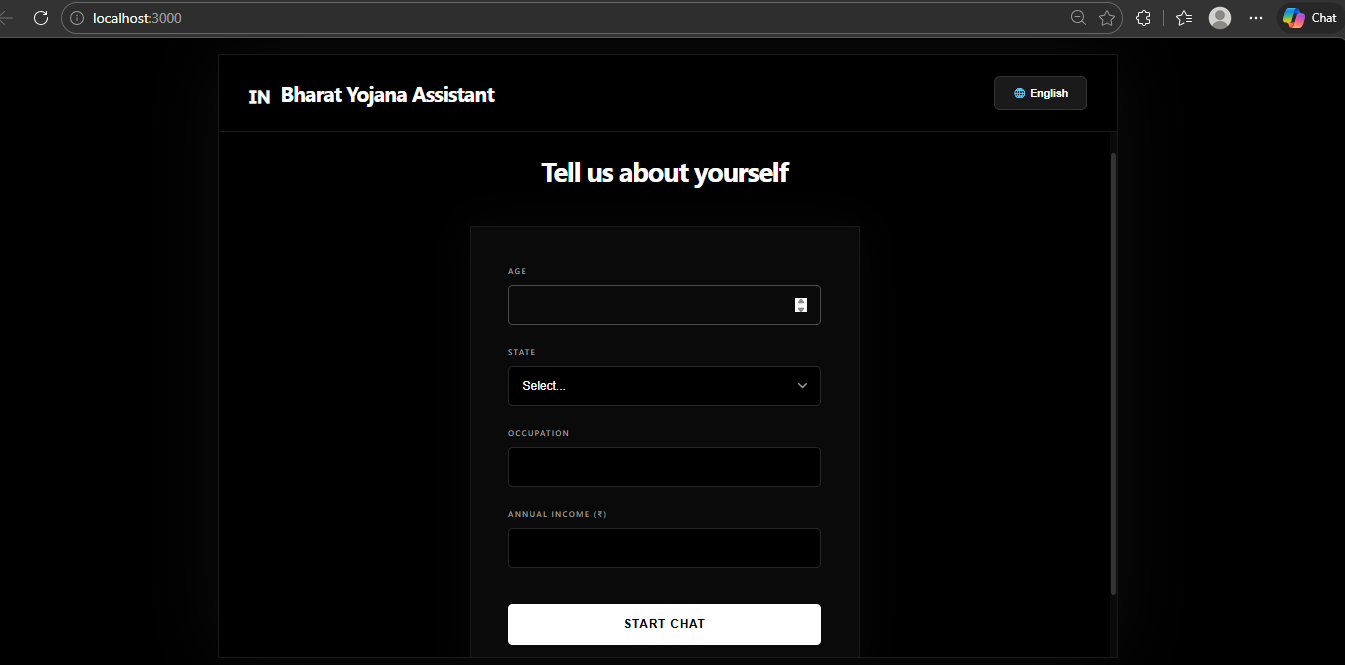
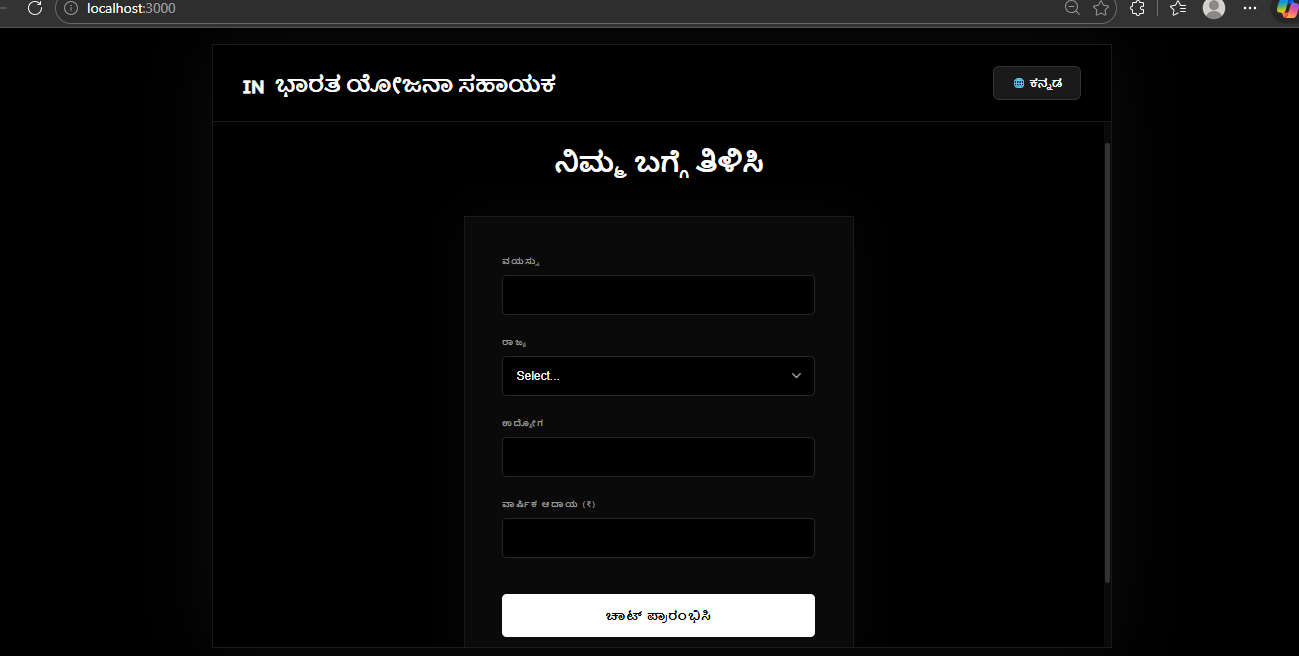
Multi-lingual
Inspiration
Billions of rupees allocated for Indian government welfare schemes (Yojanas) go unclaimed every year. The root cause is an information gap: eligibility criteria are buried in massive, complex PDF documents written in dense bureaucratic English or formal Hindi.
For the "Swatantra" (Indic AI) theme, we aimed to democratize access to these resources. Our goal was to build a seamless bridge between citizens and government schemes, ensuring no one misses out on aid simply because they cannot understand lengthy policy documents.
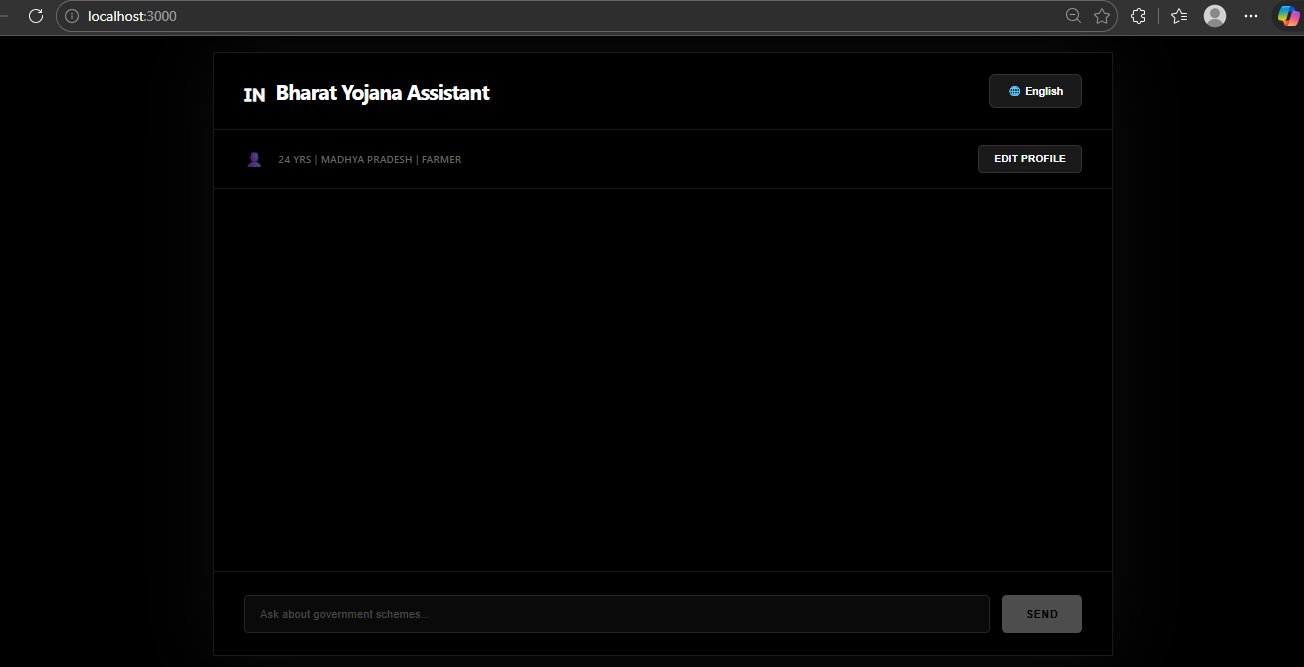
What it does
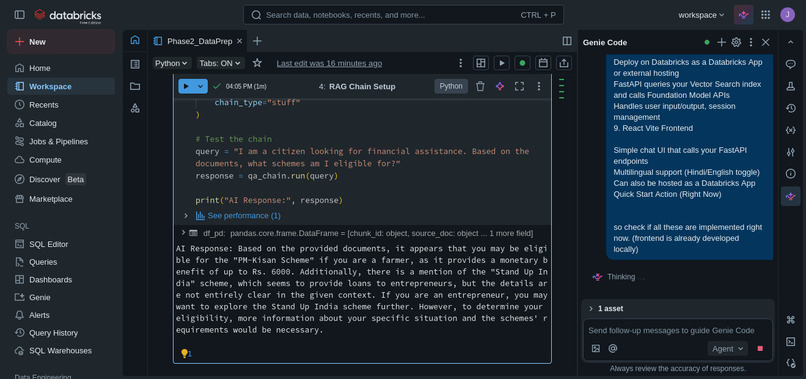
Bharat Yojana AI is an intelligent, focused Retrieval-Augmented Generation (RAG) system.
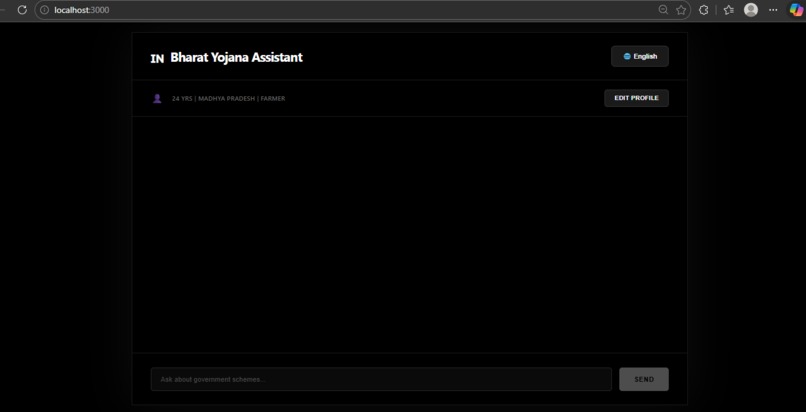
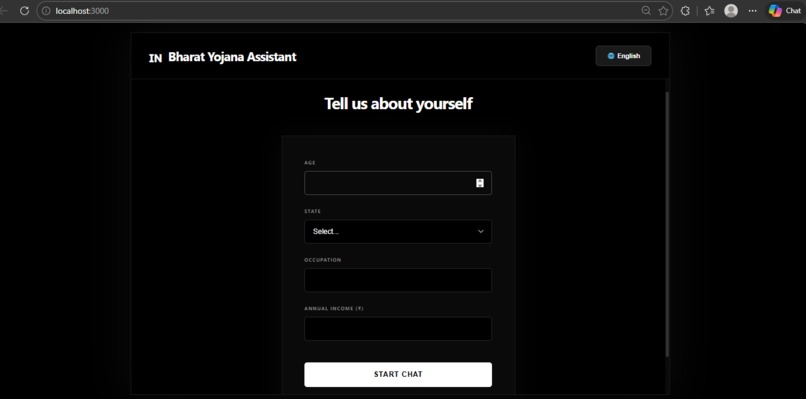
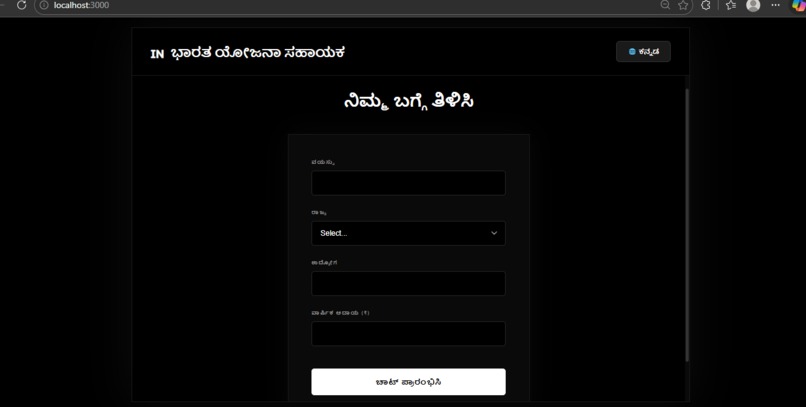
A user inputs basic demographic details such as age, income, state, and occupation. The AI acts like a personalized caseworker and:
- Scans official government policy documents
- Identifies schemes the user is eligible for
- Explains eligibility in simple language
- Guides users on how to apply
Instead of returning links, it synthesizes relevant clauses into clear, accessible insights.
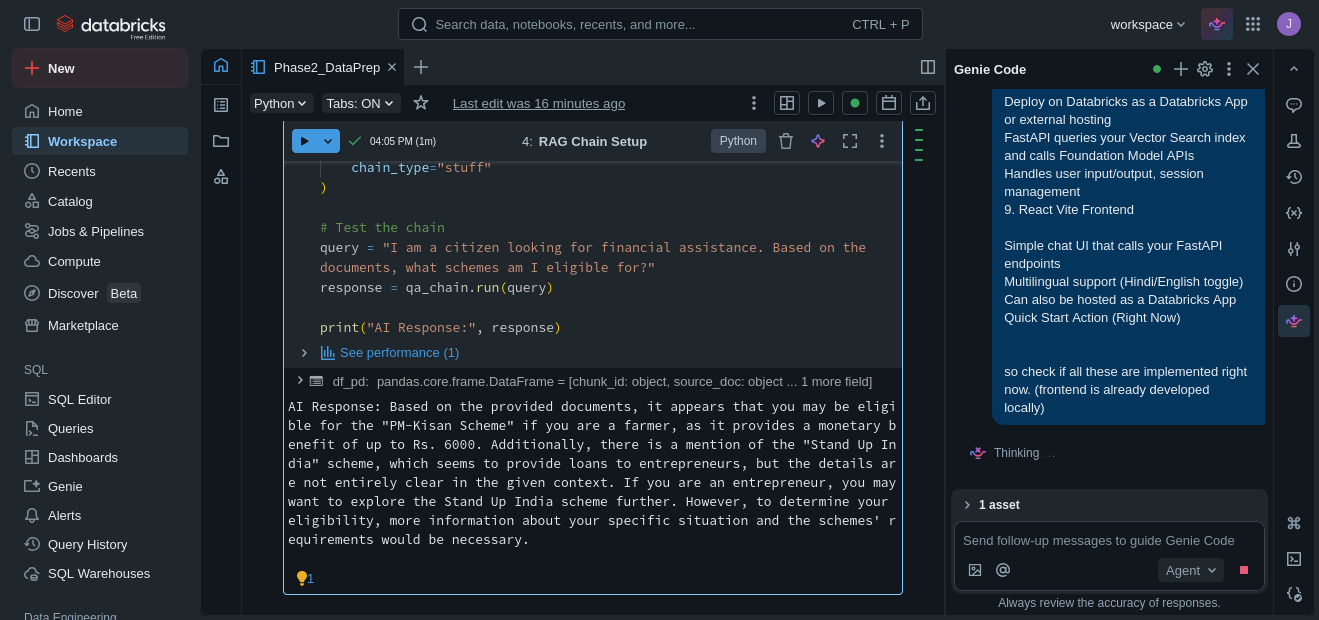
How we built it
We built the entire backend and AI pipeline natively on Databricks using the Lakehouse architecture:
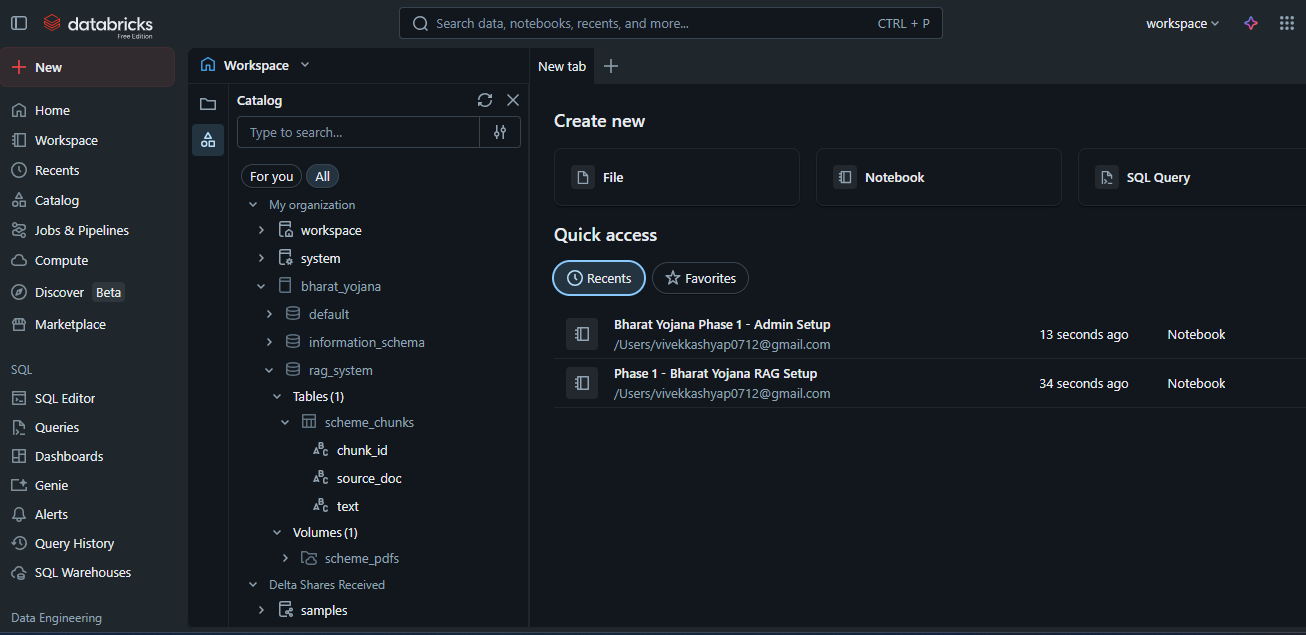
Data Ingestion & Storage
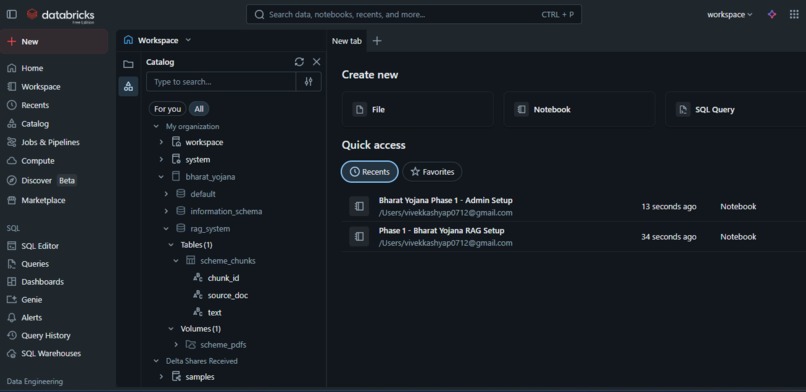
- Collected official scheme PDFs from data.gov.in
- Stored them in Unity Catalog Volumes for governed unstructured storage
Processing & Chunking
- Used PyPDFLoader and LangChain on a Databricks Serverless cluster
- Split documents into 500-character chunks with 50-character overlap
- Stored processed chunks in a Delta Table:
bharat_yojana.rag_system.scheme_chunks - Enabled Change Data Feed for real-time updates
Vector Search & Embeddings
- Generated embeddings using
databricks-bge-large-en - Stored vectors using FAISS
- Used cosine similarity for retrieval:
Generative Inference
- Used
databricks-meta-llama-3-70b-instructvia Model Serving - Prompted the model to act as an empathetic Indian government advisor
- Combined retrieved context + user profile for final output
Challenges we ran into
- Tight hackathon timeline forced rapid development and decision-making
- Initially over-engineered with React + FastAPI + external vector DB
- Pivoted to a fully Databricks-native architecture mid-way
- Parsing poorly formatted government PDFs (tables, scans, watermarks)
- Maintaining context continuity during chunking
Accomplishments that we're proud of
- Built a fully functional RAG pipeline in under 8 hours
- Implemented end-to-end system entirely within Databricks
- Avoided external vector databases and complex integrations
- Successfully converted unstructured PDFs into a smart AI system
- Demonstrated rapid prototyping using Lakehouse architecture
What we learned
- Unity Catalog is powerful for managing both structured and unstructured data
- Delta Tables + Volumes together form a strong data foundation
- Databricks Model Serving simplifies LLM deployment
- LangChain integrates well with Delta tables for scalable RAG pipelines
- Building inside a unified platform significantly reduces complexity
What's next for Bharat Yojana AI
- Build a multilingual frontend (Hindi, Kannada, Tamil, etc.)
- Integrate WhatsApp bot for accessibility in Tier-2 and Tier-3 cities
- Add voice-based interaction for low-literacy users
- Connect live APIs from data.gov.in for real-time updates
- Improve personalization and recommendation accuracy
Built With
- apache-spark
- apis
- databricks-bge-large-en
- databricks-lakehouse
- databricks-meta-llama-3-70b-instruct
- databricks-model-serving
- databricks-vector-search
- databricks-volumes
- delta-lake
- faiss
- fastapi
- javascript
- langchain
- pyspark
- python
- react
- rest
- unity-catalog
- vite

Log in or sign up for Devpost to join the conversation.