-
-
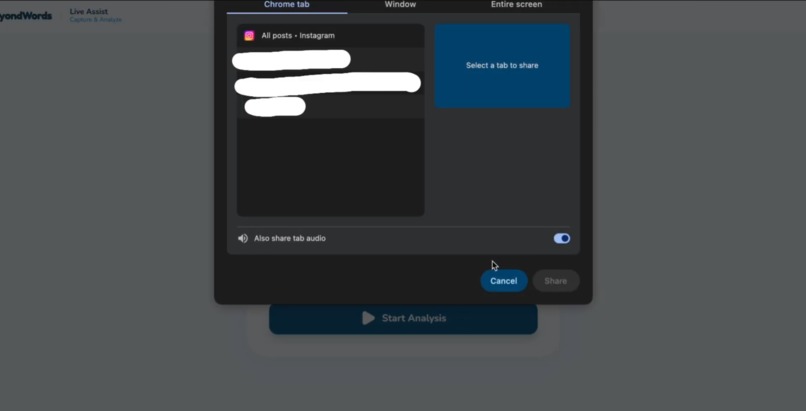
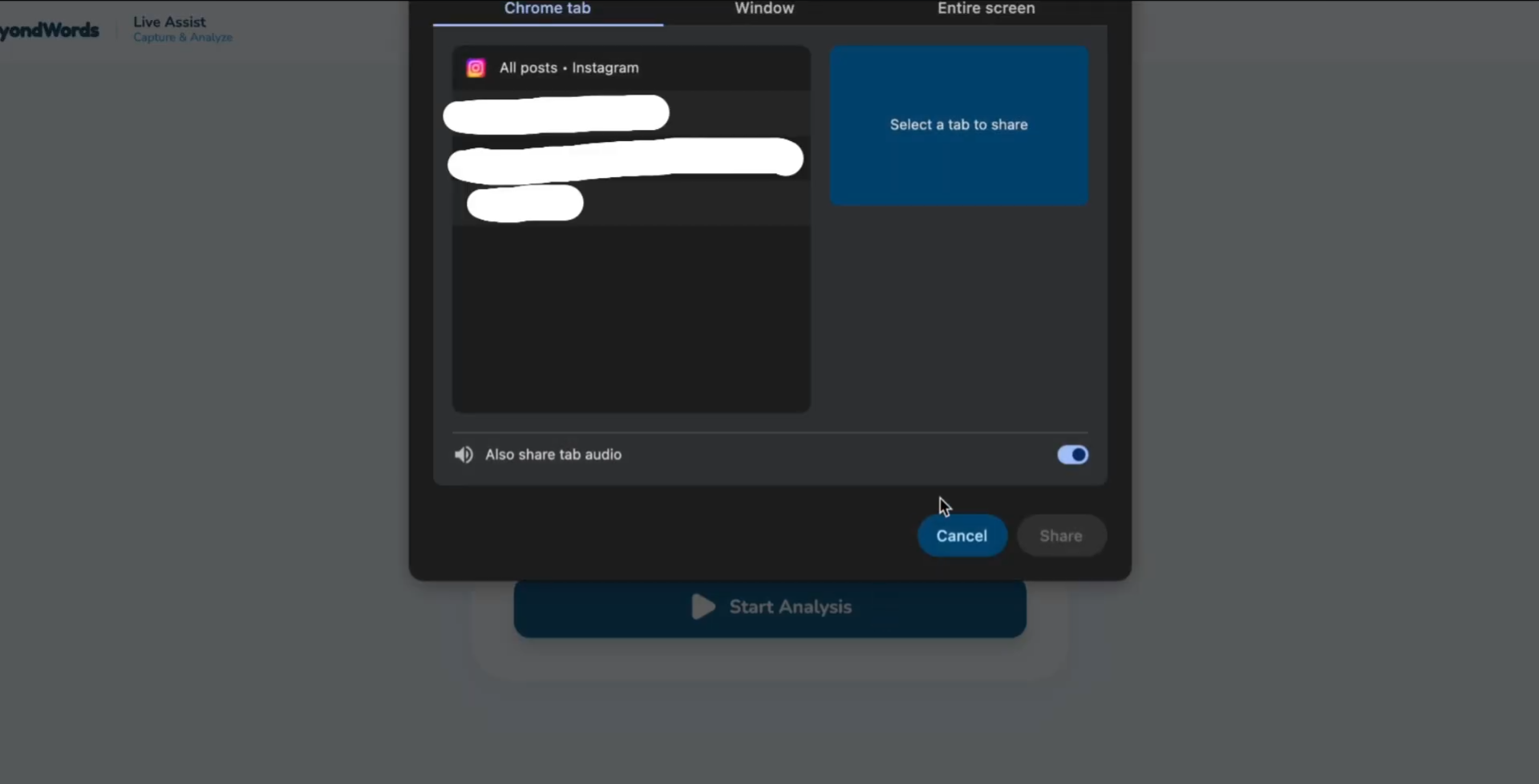
Options where you can share your screen
-
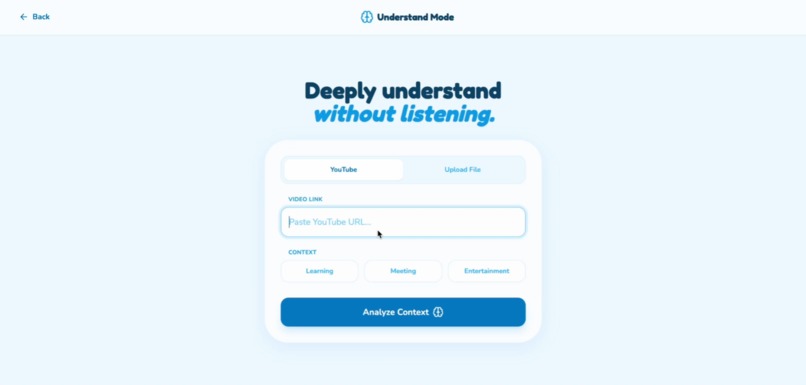
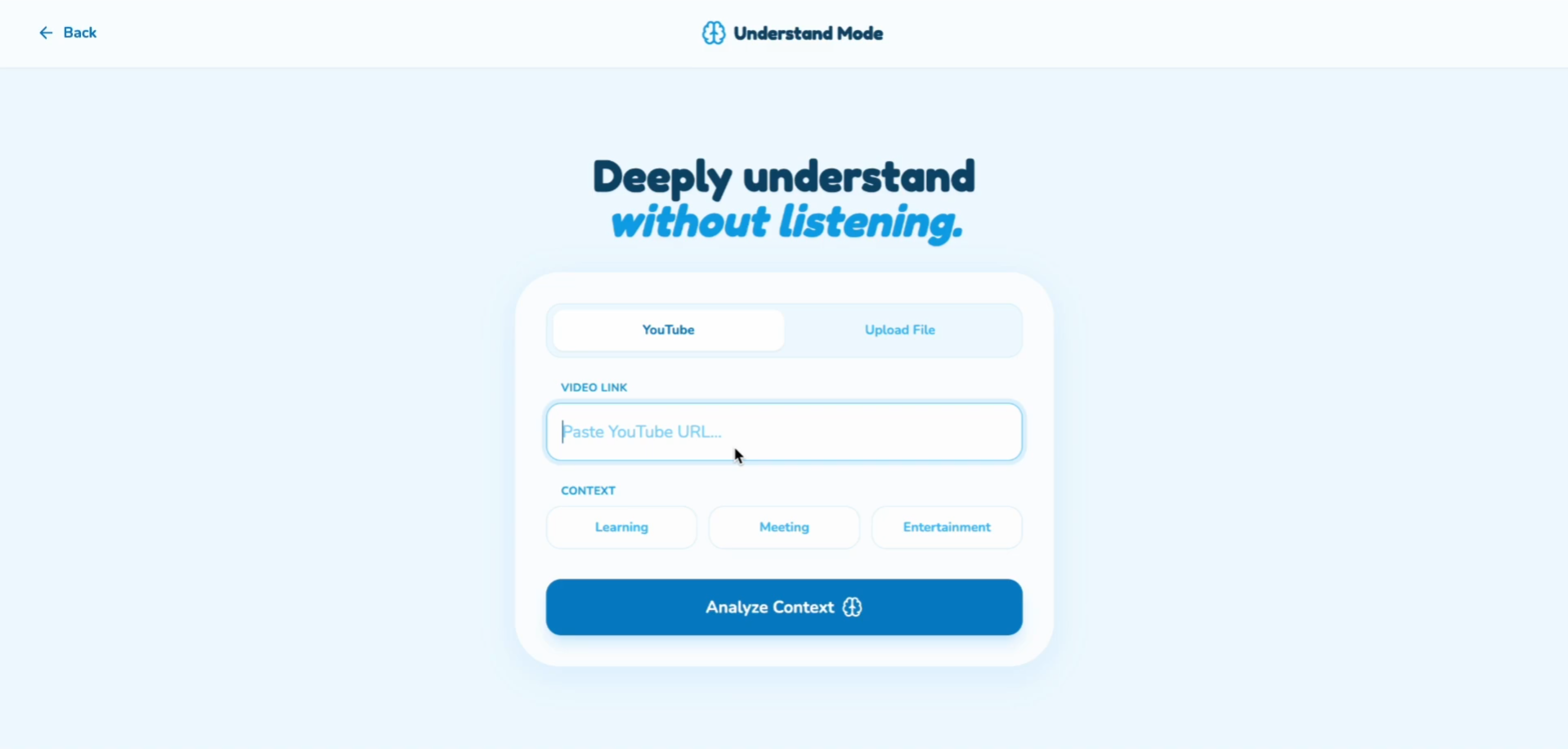
The understand mode entry point
-
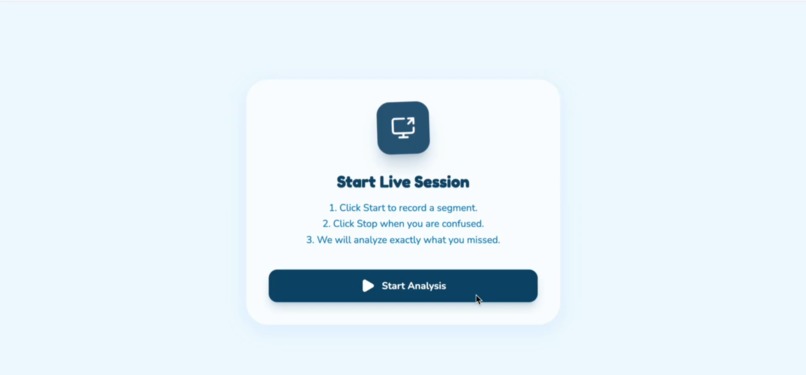
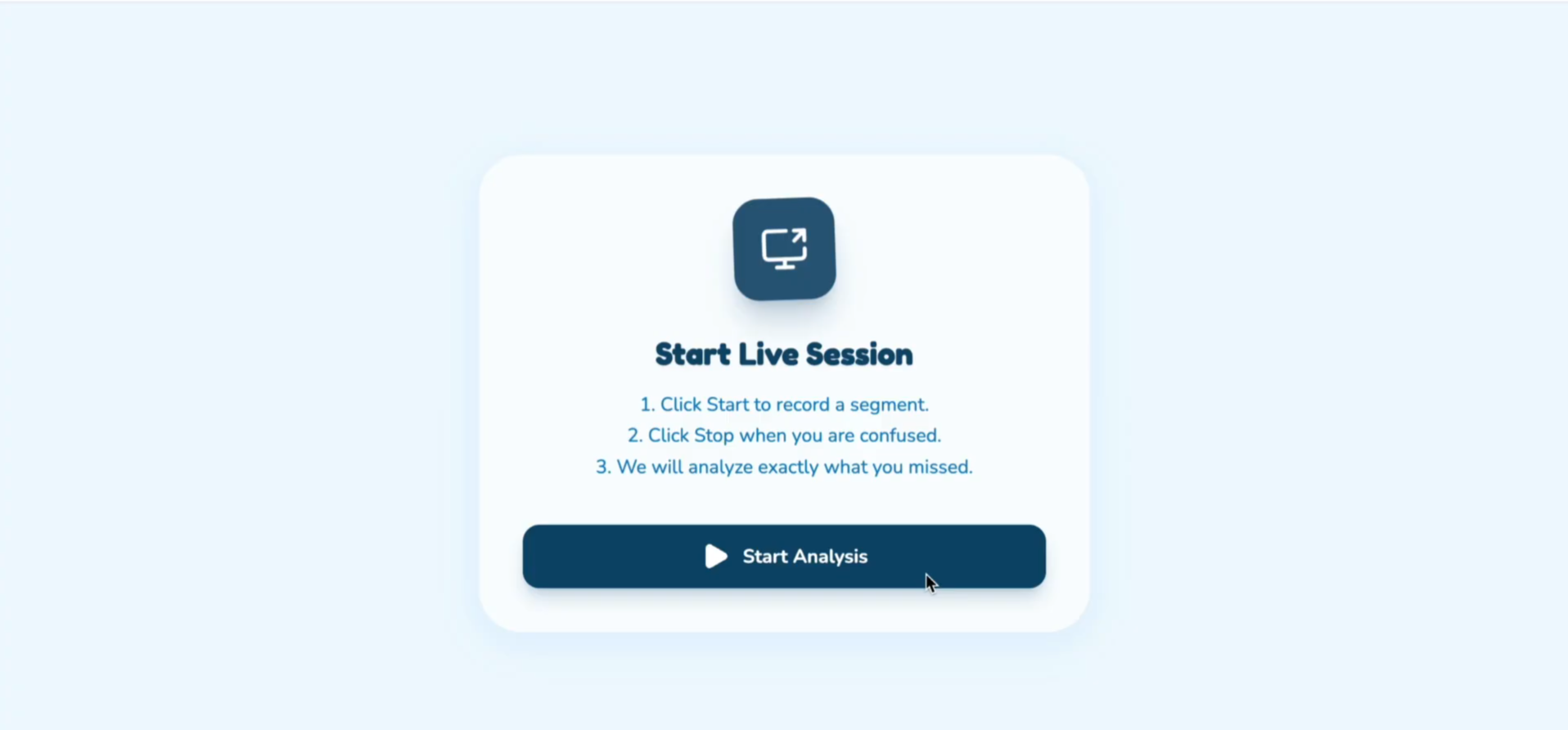
Starting point of the Live Assist Mode
-
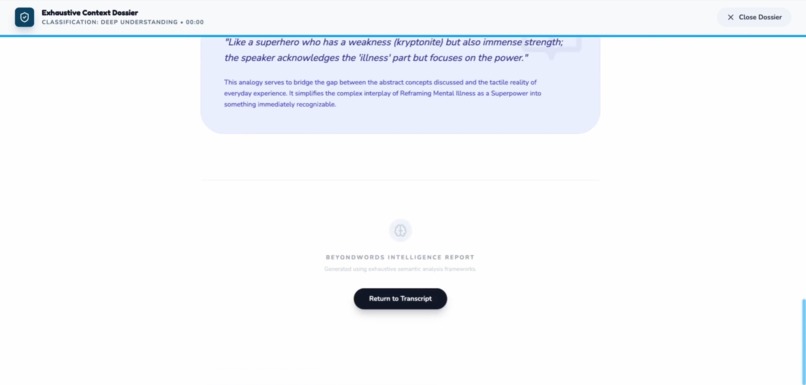
The understand mode The Deeply mode 6
-
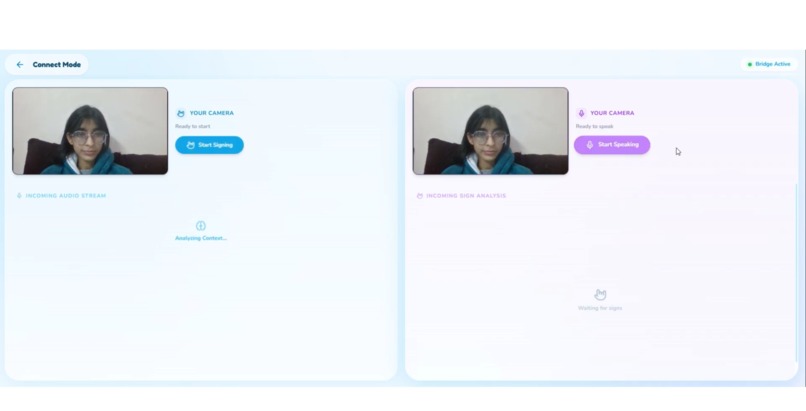
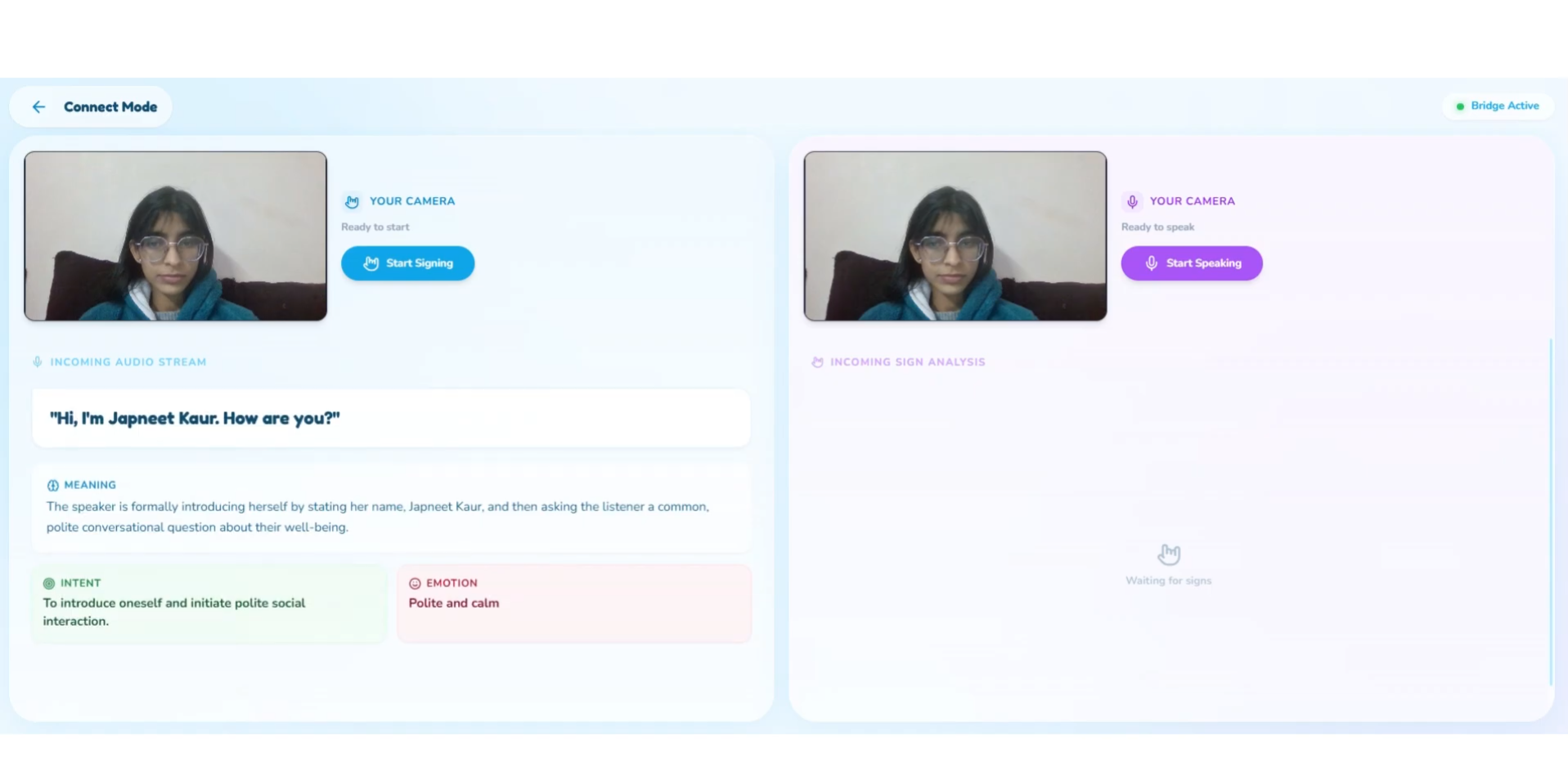
This is Our normal screen in connect mode looks like
-
-
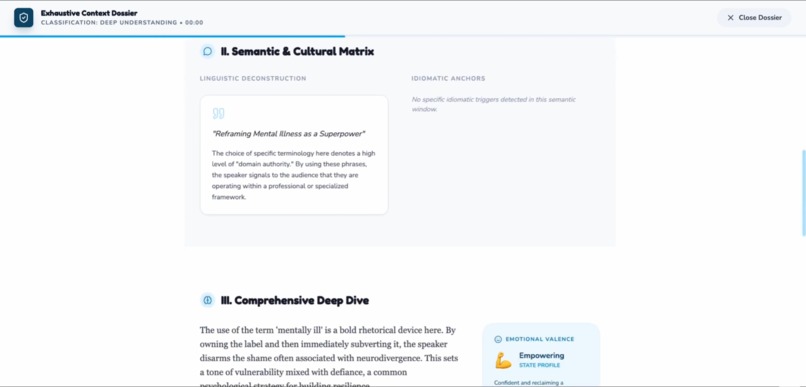
The understand mode the deeply mode 3
-
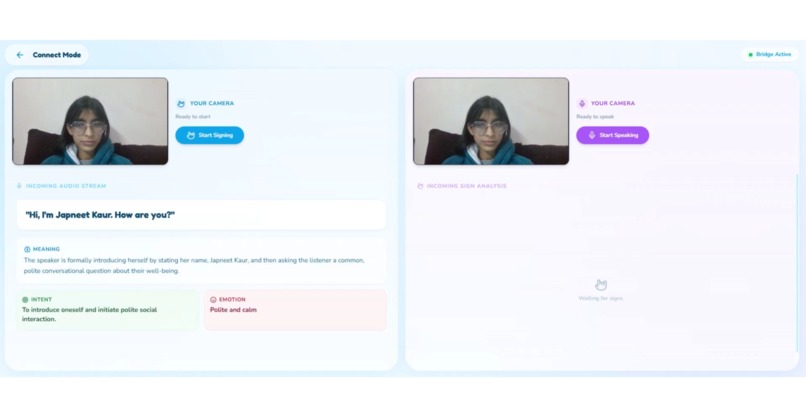
this is our spoken to the HoH user
-
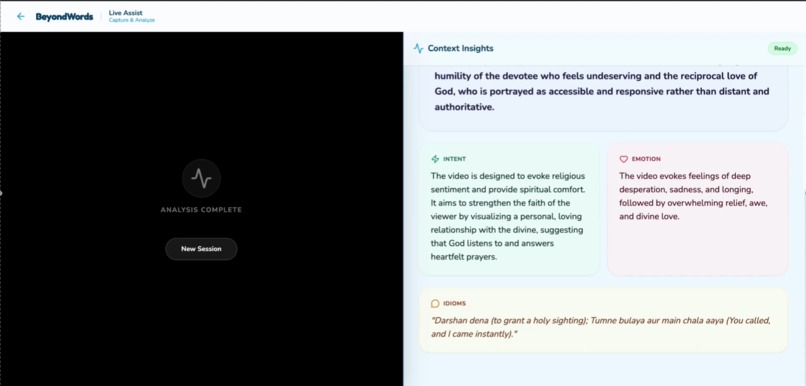
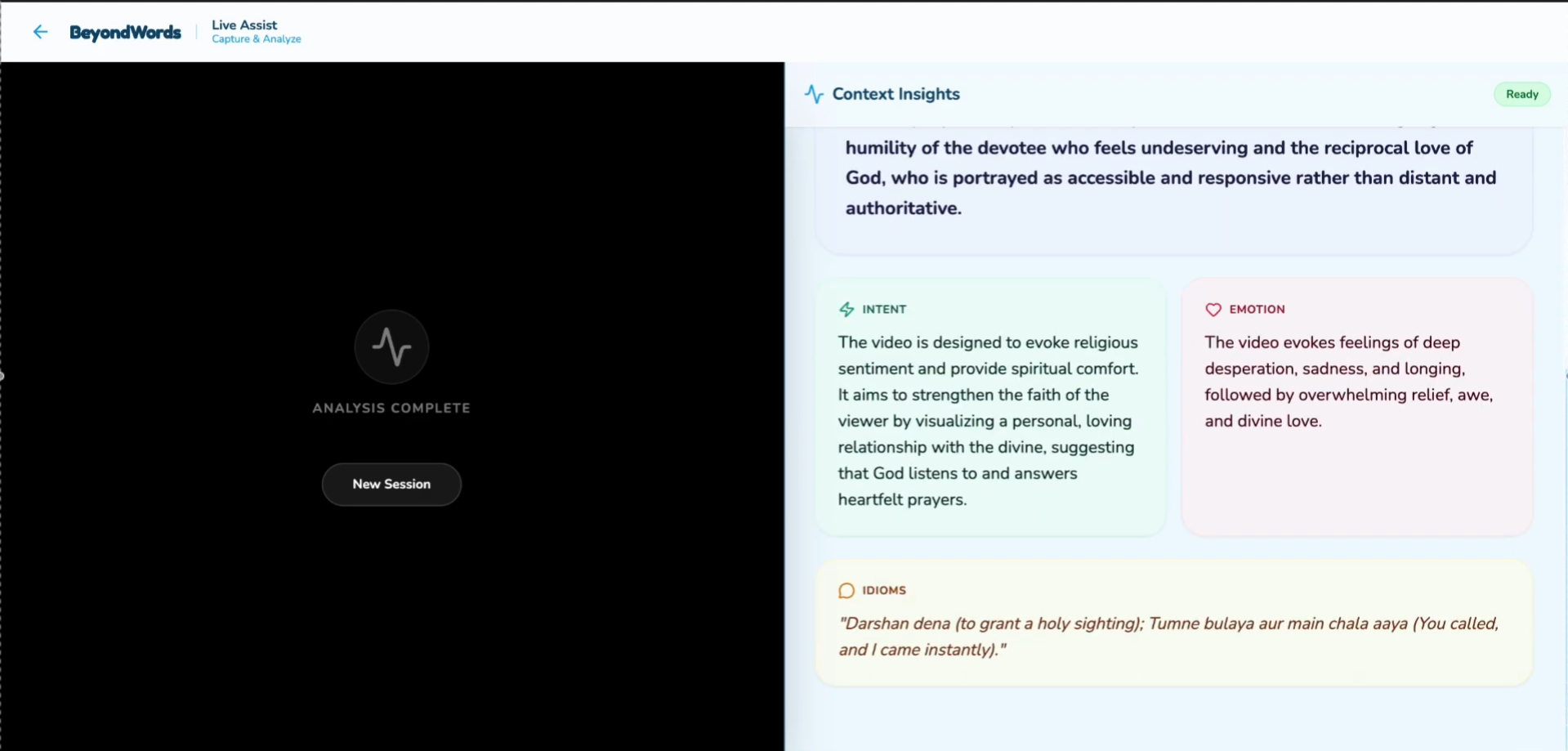
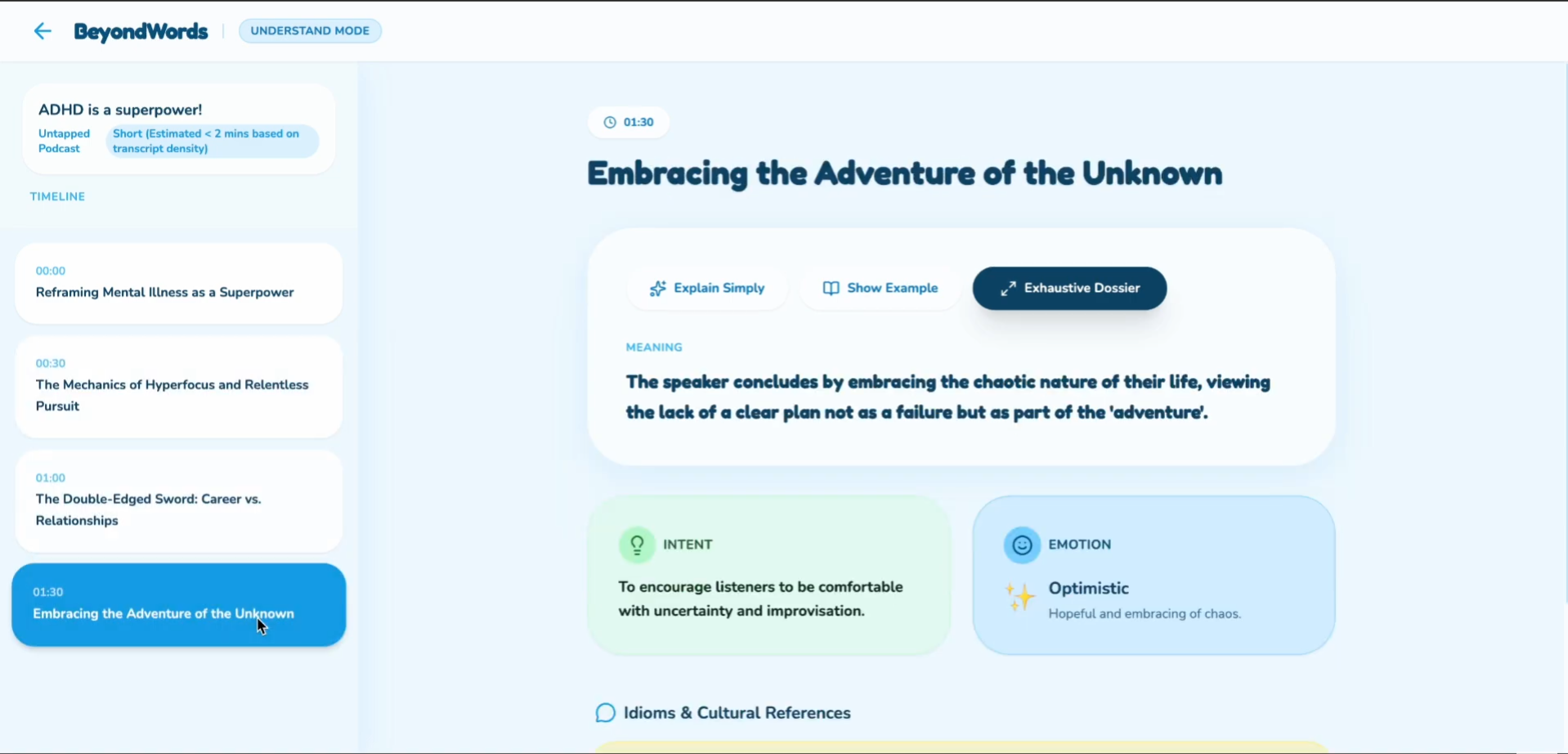
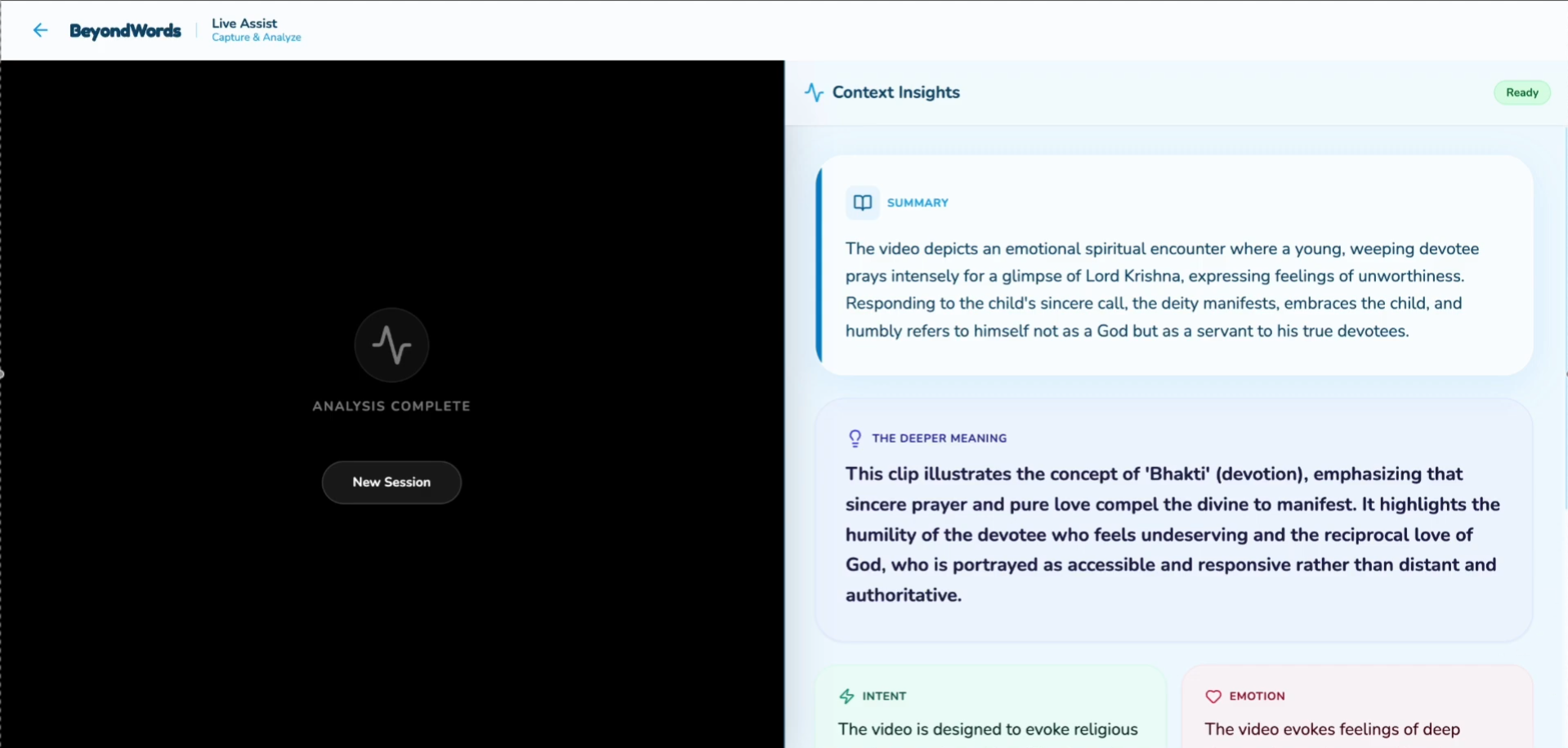
The full detail of Idioms and intent and even emotions of the content
-
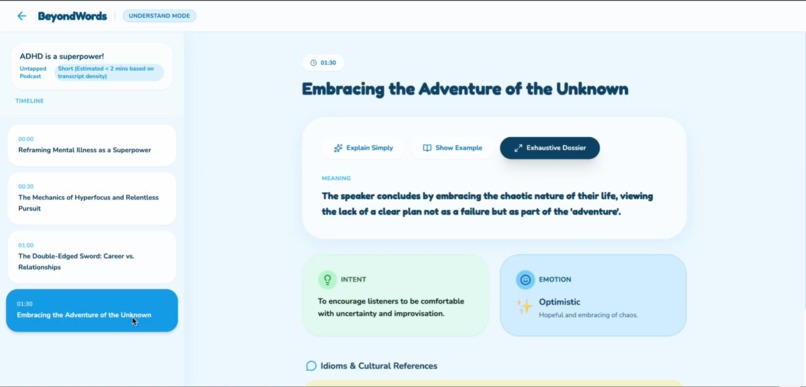
The understand mode another view
-
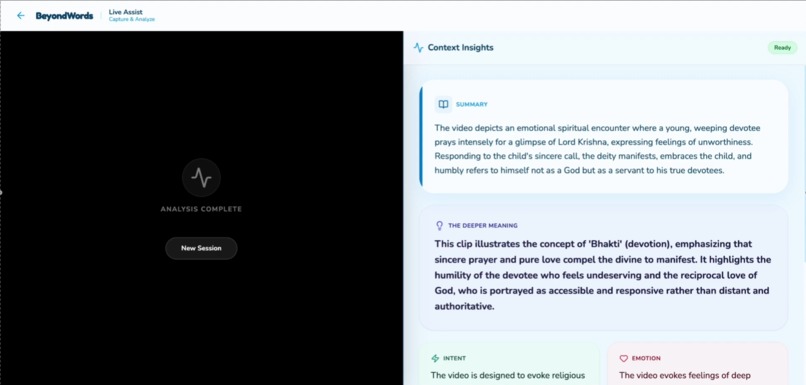
Summary of what is in the video and then existent of what it means
-
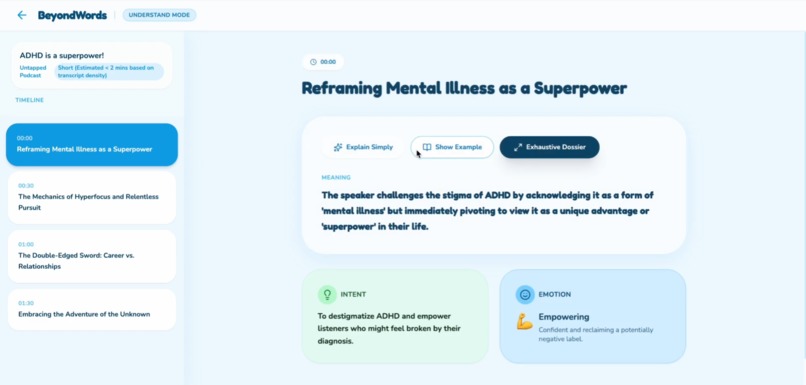
The understand mode the sections
-
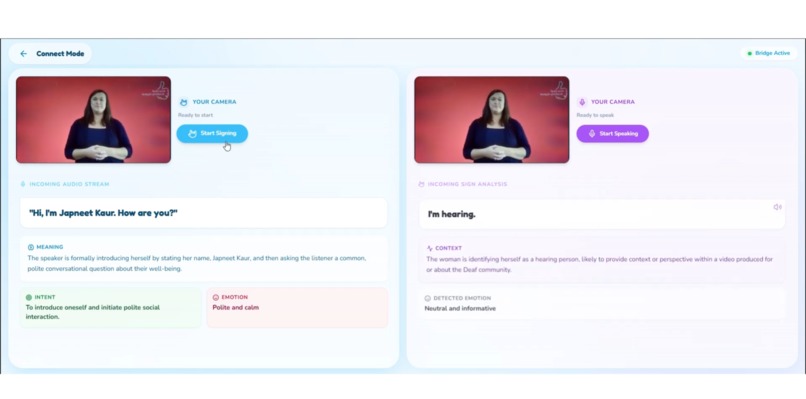
This is our Sign Language interpretation
-
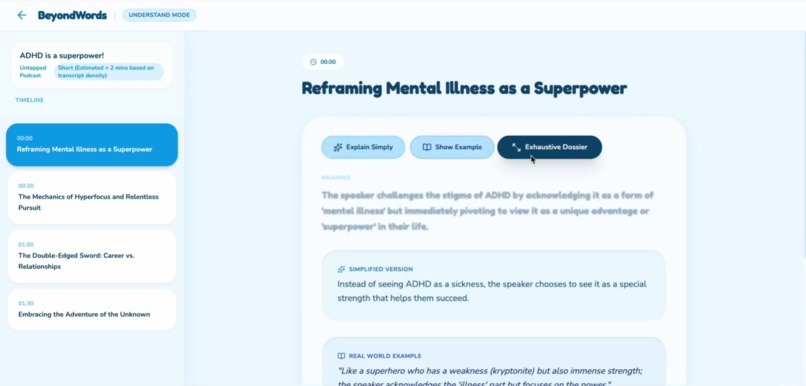
The understand mode the explain why
-
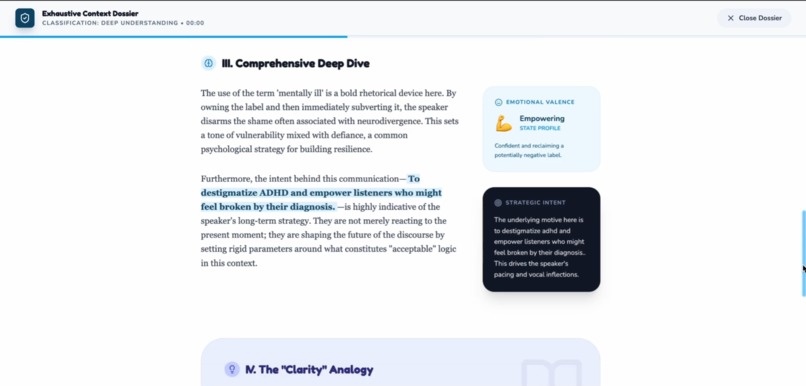
The understand mode The Deeply mode 4
-

The understand mode The Deeply mode 5
-
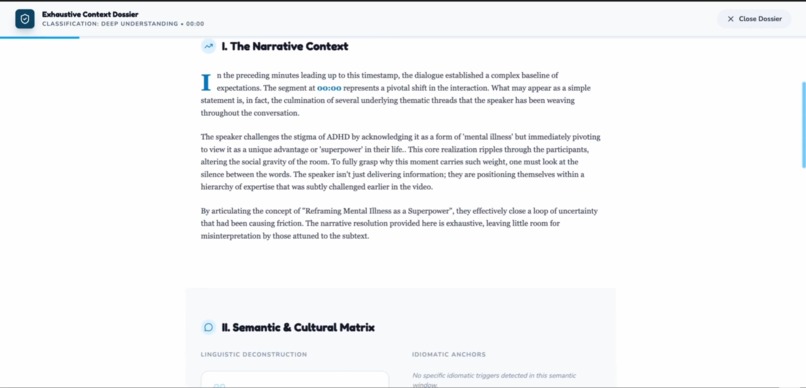
The understand mode the deeply mode 2
-

The understand mode The deeply mode
-
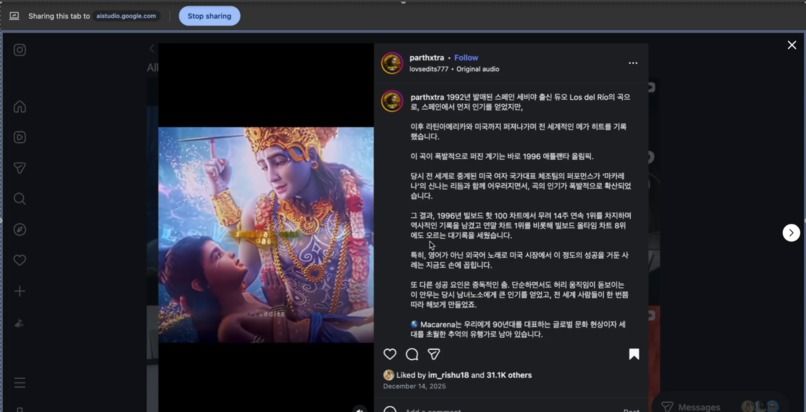
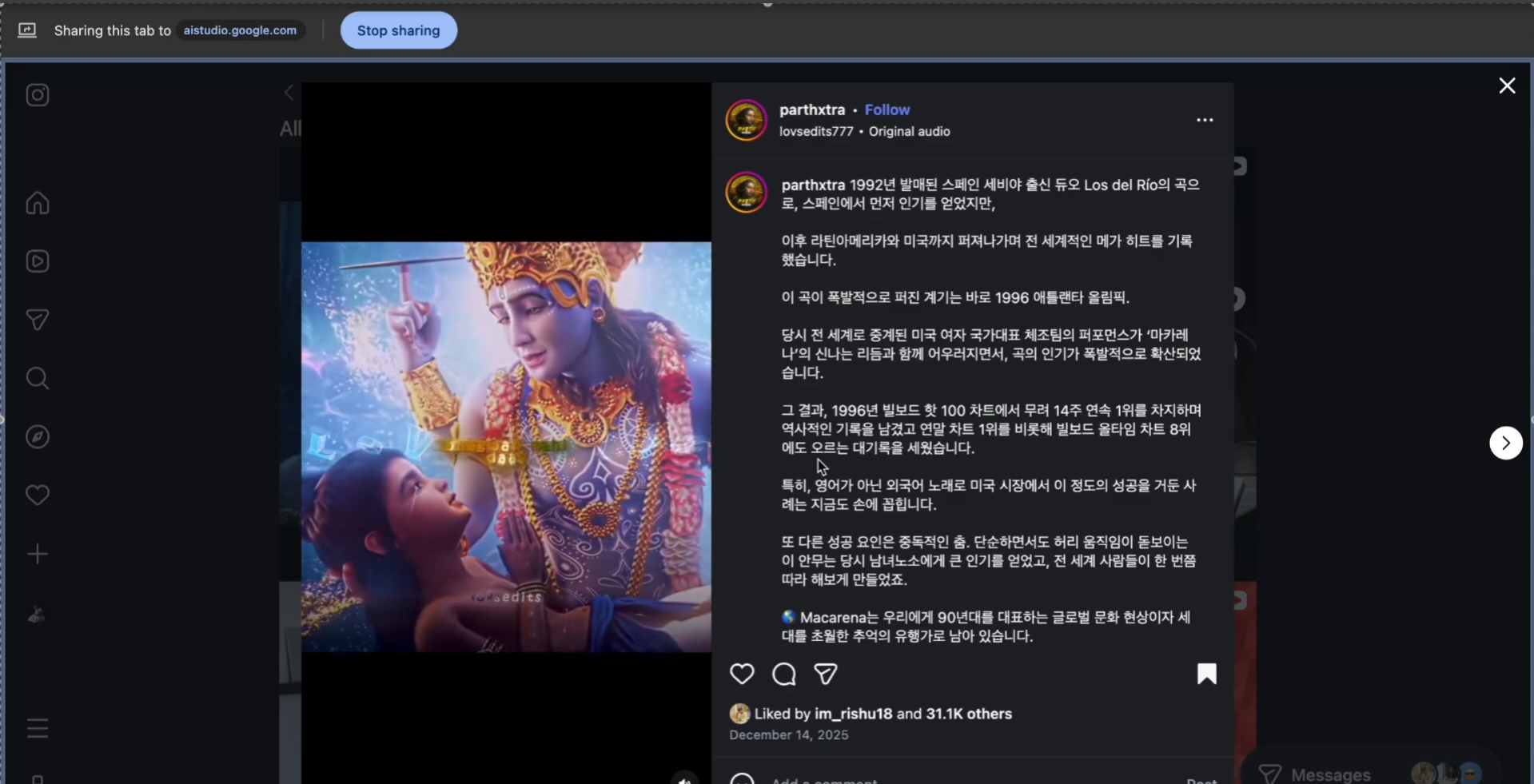
Screen sharing with Live Assist Mode


BeyondWords
Inspiration
For the 466 million people worldwide who are hard of hearing (HoH), the world isn't silent — it's incomplete.
Most accessibility tools focus on words: captions, transcripts, speech-to-text. But human communication is not made of words alone. Meaning lives in tone, emotion, sarcasm, cultural references, and context that builds over time. When these layers disappear, misunderstanding replaces inclusion.
We were inspired by a simple but painful realization:
Transcription tells you what was said. It doesn't tell you what was meant.
Imagine watching a heated debate where someone says "I completely agree with you" — but their tone drips with sarcasm. Subtitles show the words. They miss the meaning. The HoH viewer thinks there's agreement. Everyone else hears the confrontation.
Or picture a lecture where a professor references "the elephant in the room" — an idiom that makes perfect sense to hearing students but appears as literal text to someone relying on captions, leaving them genuinely confused about what elephant the professor is talking about.
These aren't edge cases. They're everyday experiences that compound into isolation, miscommunication, and exhaustion.
BeyondWords was born to bridge that gap — not by translating speech into text, but by translating human meaning.
What it does
BeyondWords is an AI-powered accessibility platform built with Gemini's multimodal intelligence, designed to help HoH users truly understand conversations, videos, and live content — beyond subtitles.
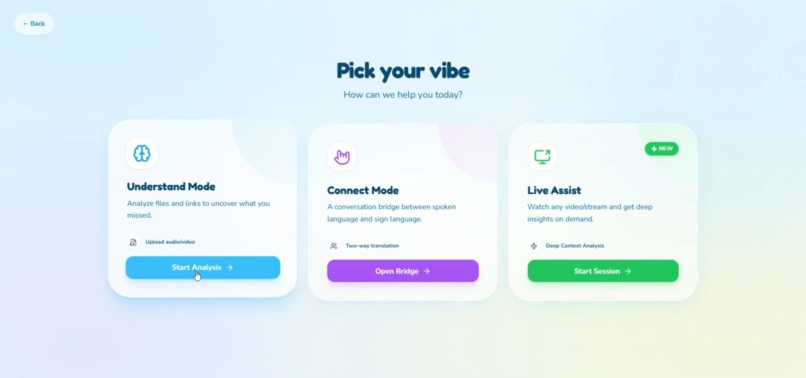
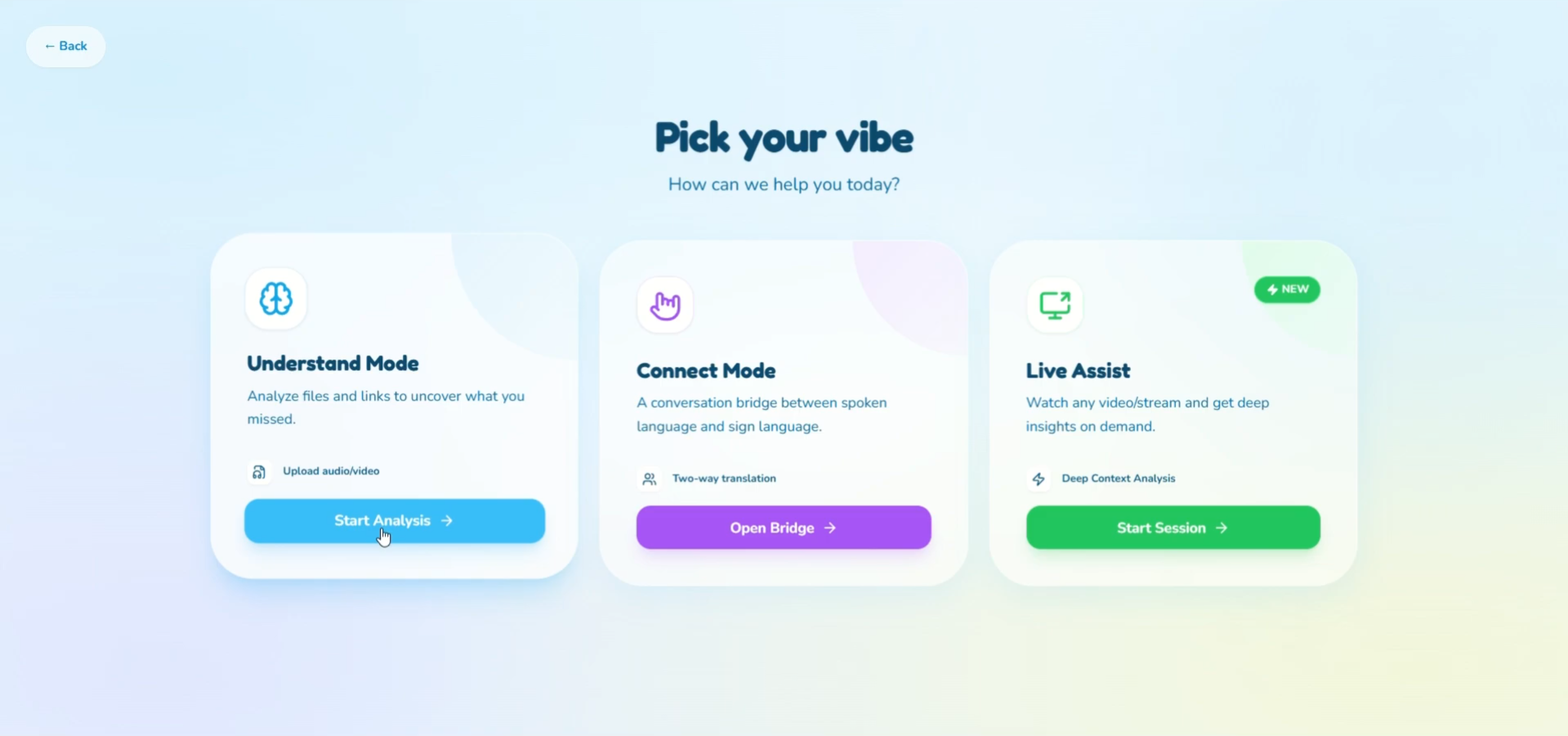
It currently offers three modes, each solving a different real-world pain point:
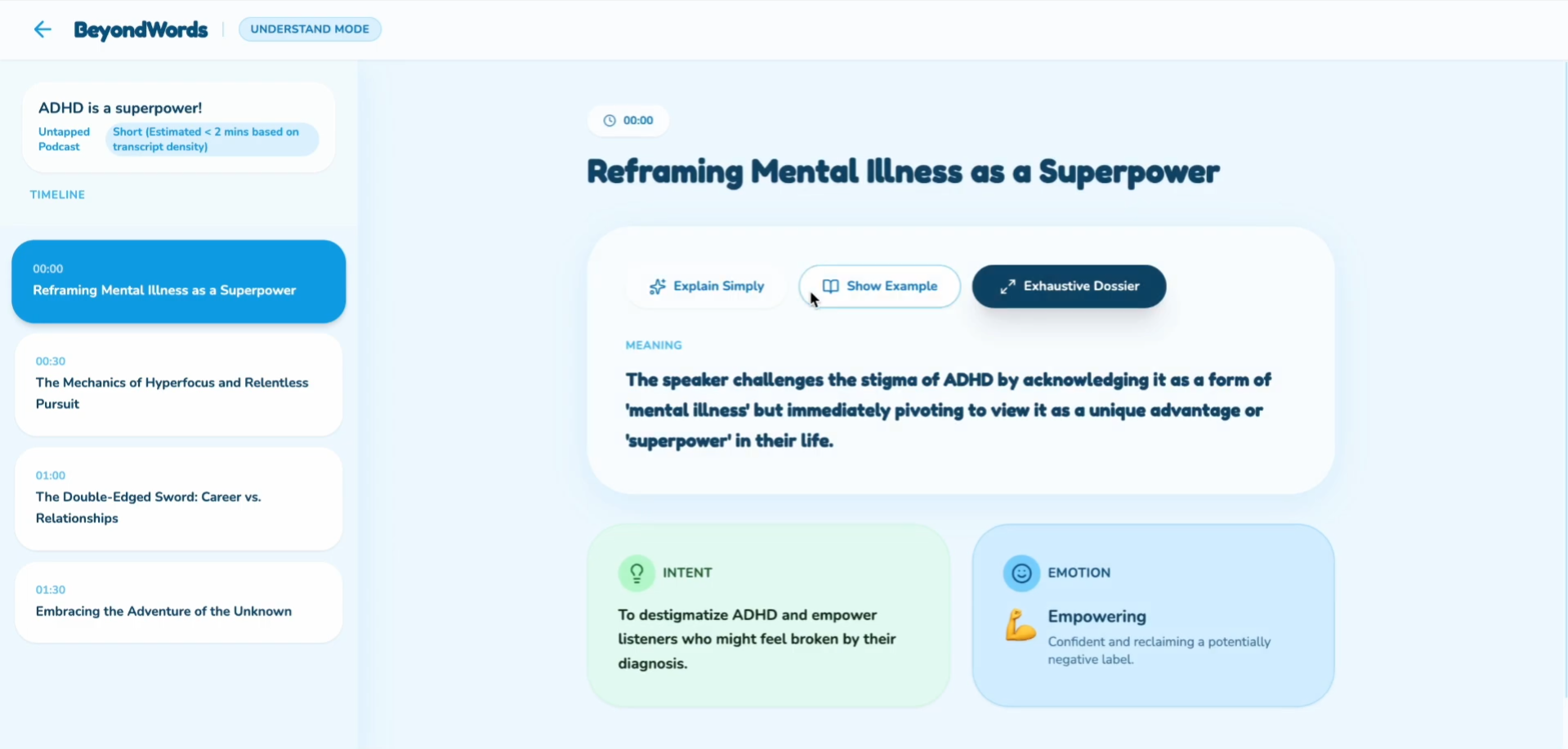
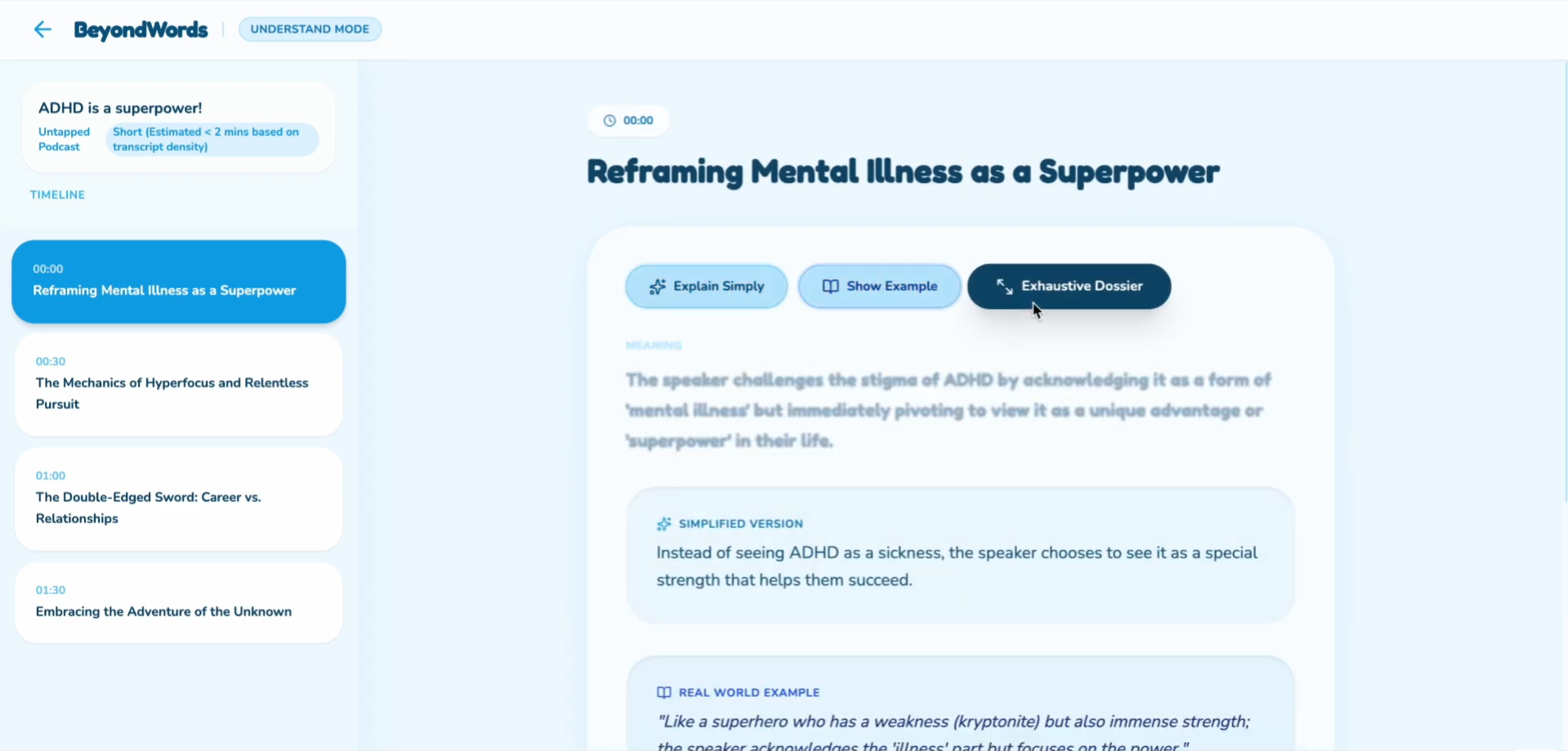
1. Understand Mode (Deep Comprehension)
The Problem: YouTube videos, podcasts, and recorded content are captioned — but context, emotion, and cultural references are lost.
The Solution:
Users can upload a YouTube link, local video, or audio file. The system then:
Breaks content into meaningful timestamped sections — not arbitrary time chunks, but semantic moments (e.g., "Introduction," "First counterargument," "Emotional climax")
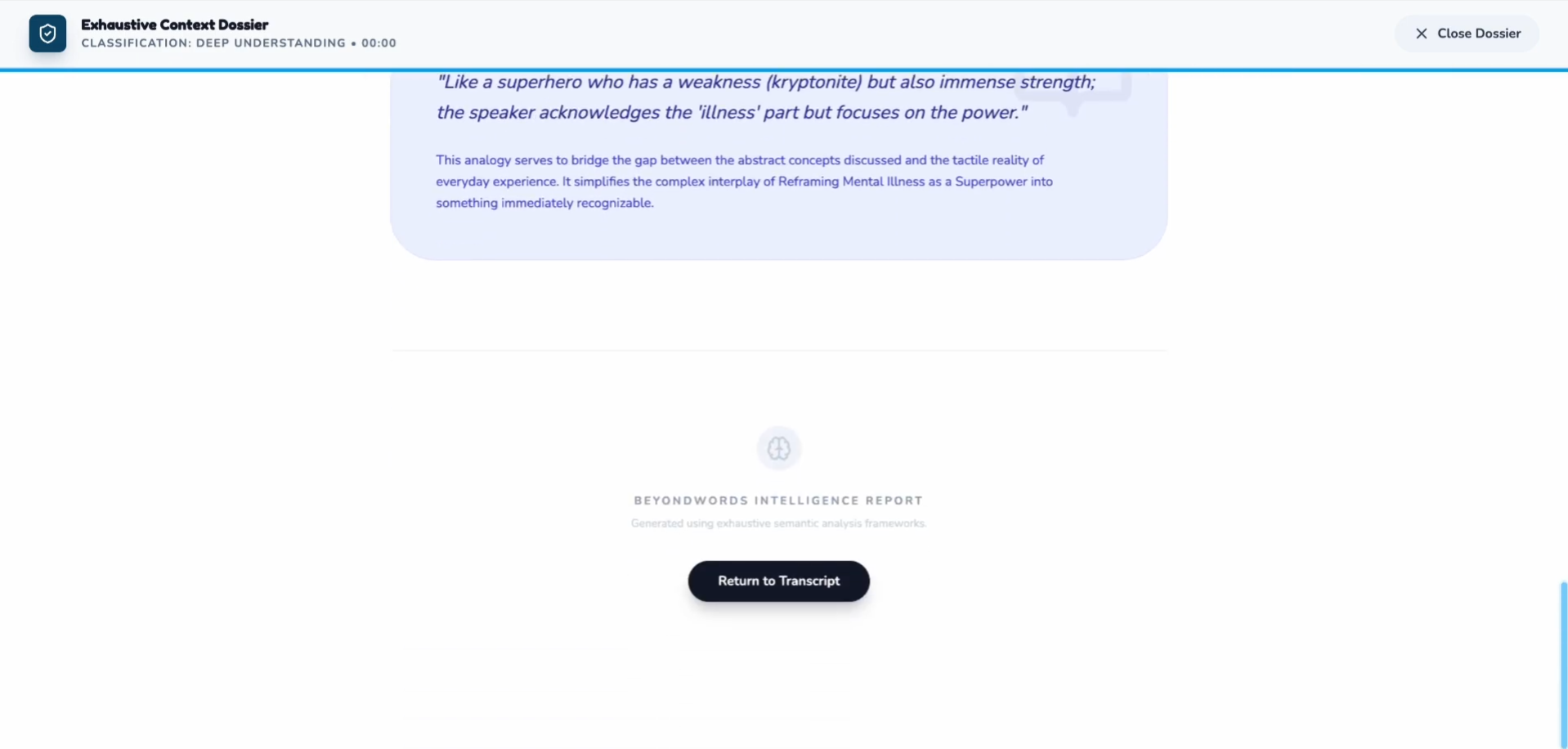
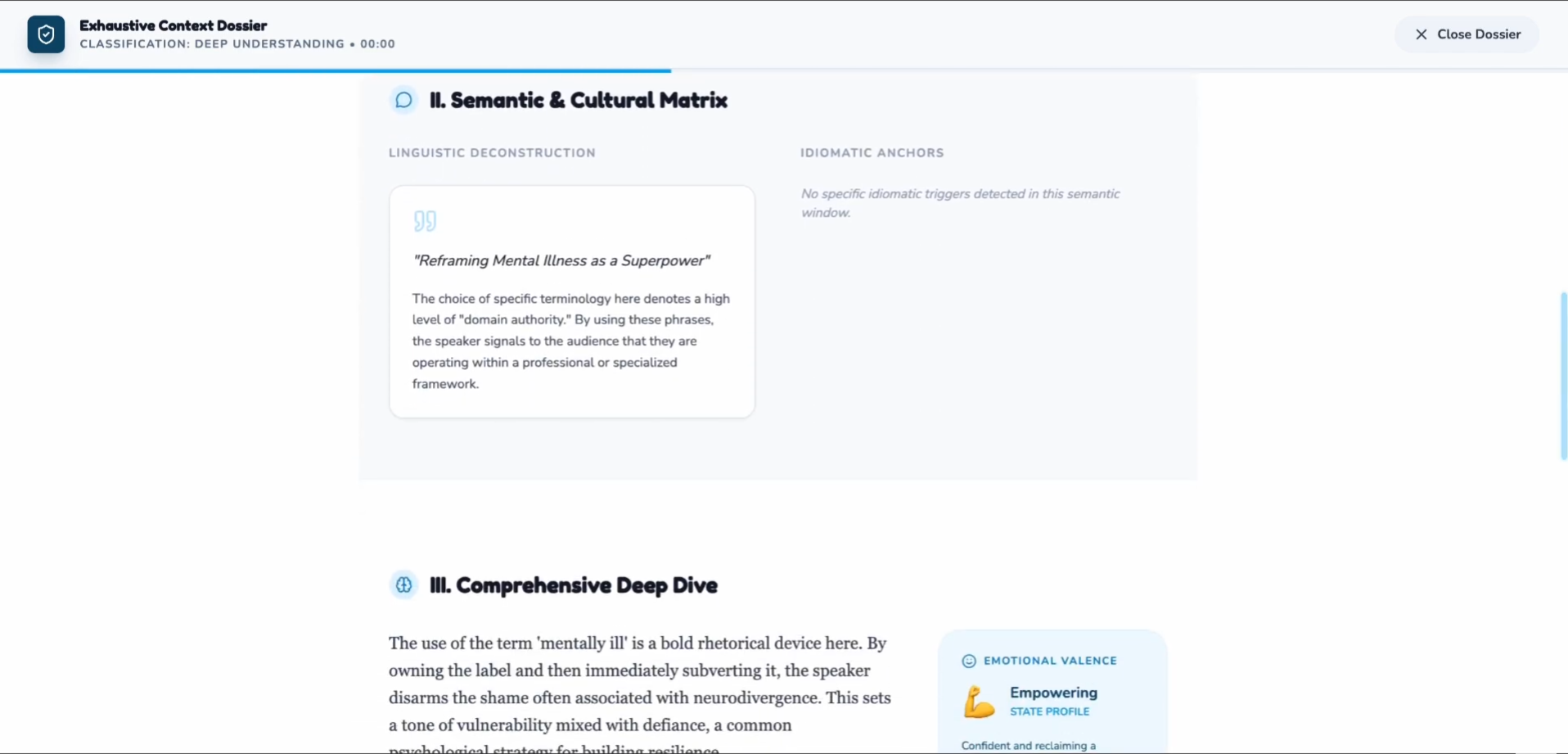
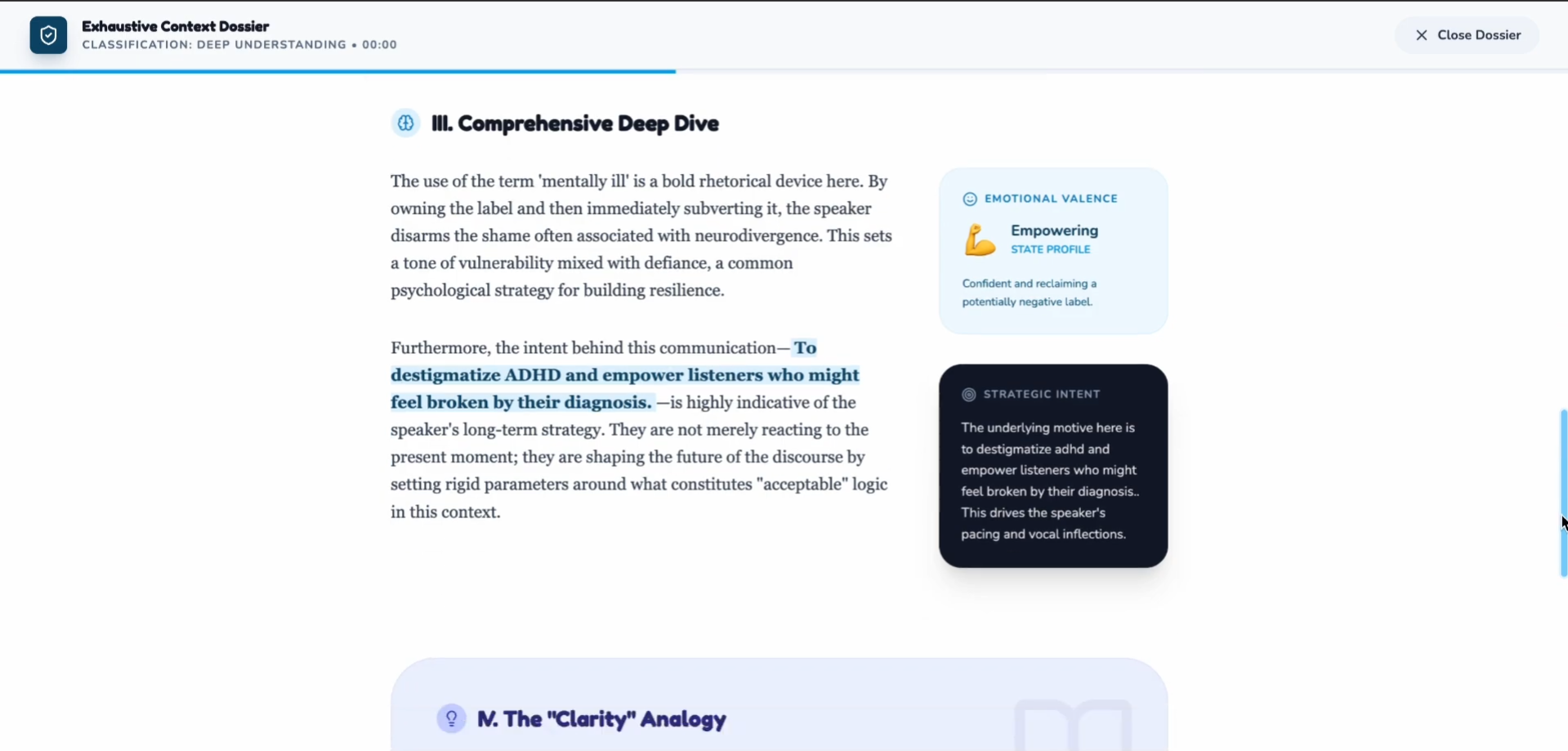
Explains what happened, why it mattered, and how it was meant — reconstructing the narrative arc and emotional journey
Detects emotional intent with precise labeling: calm, nervous, sarcastic, tense, excited, dismissive, empathetic, etc.
Explains idioms, metaphors, jokes, and references that subtitles miss entirely
Real Example:
A comedian says: "My bank account after the holidays? Chef's kiss."
- Subtitle shows: "My bank account after the holidays? Chef's kiss."
- BeyondWords explains: "[Sarcastic humor] The speaker is joking that their bank account is empty/terrible after holiday spending. 'Chef's kiss' is used ironically here — it usually means 'perfect,' but the speaker's tone indicates the opposite. The joke relies on the contrast between the positive phrase and the negative reality."
This allows HoH users to reconstruct meaning, not just read words.
2. Live Assist Mode (Meaning on Demand)
The Problem: When watching shows, scrolling social media, or sitting in online meetings, you can see the captions — but when someone laughs, the room goes quiet, or a comment feels off, you're left wondering what you actually missed.
The Solution:
Users screen-share any content — Netflix shows, TikTok videos, Instagram reels, YouTube livestreams, Zoom meetings, college lectures, even restricted platforms that don't allow plugins.
When something feels confusing or incomplete, the user simply asks:
- "What did I just miss?"
- "Why did everyone laugh?"
- "Was that sarcastic?"
- "What's the vibe right now?"
BeyondWords then:
- Analyzes the complete current context — not just a snippet, but the full ongoing conversation, scene, or interaction
- Processes emotional shifts, power dynamics, callbacks, and hidden context that captions can't capture
- Provides deep, conversational insight that explains the meaning you lost
The beauty of Live Assist Mode: You don't need to rewind or pause. Just ask, and BeyondWords catches you up on what the captions couldn't tell you.
Real Example 1 (Online Meeting):
During a tense work meeting, someone says: "Well, that's certainly... one approach."
- Live captions show: "Well, that's certainly one approach."
- User asks: "What did I miss?"
- BeyondWords explains: "[Passive-aggressive criticism] The speaker disagrees with the proposed approach but is being diplomatically negative. The long pause before 'one approach' and the emphasis on 'certainly' indicate skepticism. The room's energy shifted — likely others noticed the tension too. This is a polite way of saying they don't think it's a good idea."
Real Example 2 (TV Show):
Two characters are talking. One says "Sure, whatever you say, boss" and the room erupts in laughter.
- User asks: "Why is that funny?"
- BeyondWords explains: "[Sarcastic callback + inside joke] The character isn't actually agreeing — they're being sarcastic. Earlier in the episode (around 8 minutes in), the same character refused to take orders from anyone. Calling them 'boss' now is ironic. The laugh track confirms the audience caught the sarcasm. The humor comes from the contrast between the respectful words and the dismissive tone."
Real Example 3 (Social Media):
Watching a TikTok where someone says "I'm fine" with a specific facial expression, and comments are going wild.
- User asks: "What's happening here?"
- BeyondWords explains: "[Trending audio + ironic expression] The creator is using the 'I'm fine' sound ironically — their exaggerated smile and eye twitch indicate they're definitely NOT fine. This is a popular meme format where people show they're barely holding it together. Comments are laughing because they relate to the feeling of pretending everything's okay when it isn't."
This mode turns confusion into clarity — whether you're watching entertainment, scrolling social media, or navigating professional meetings. It's meaning on demand, exactly when you need it.
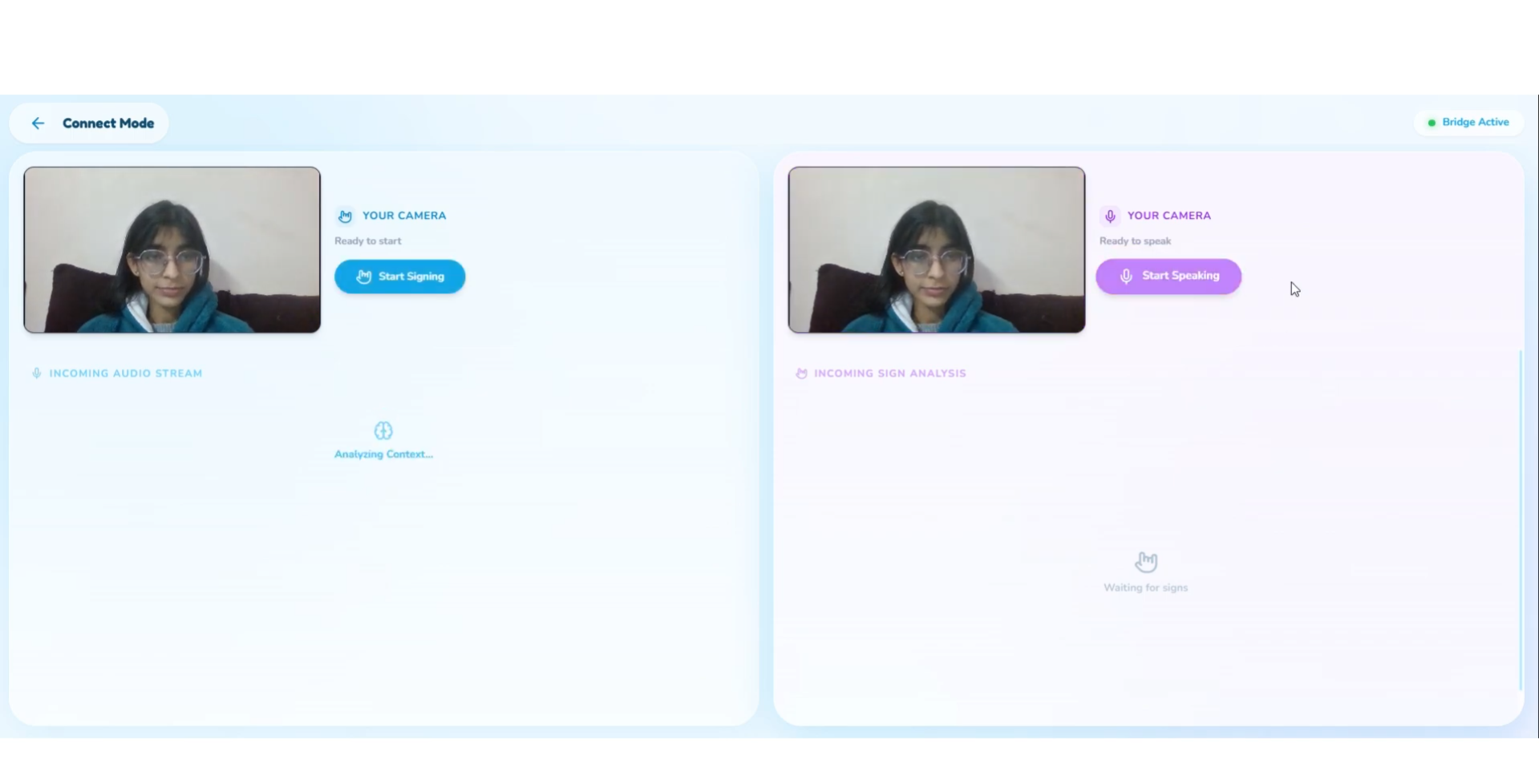
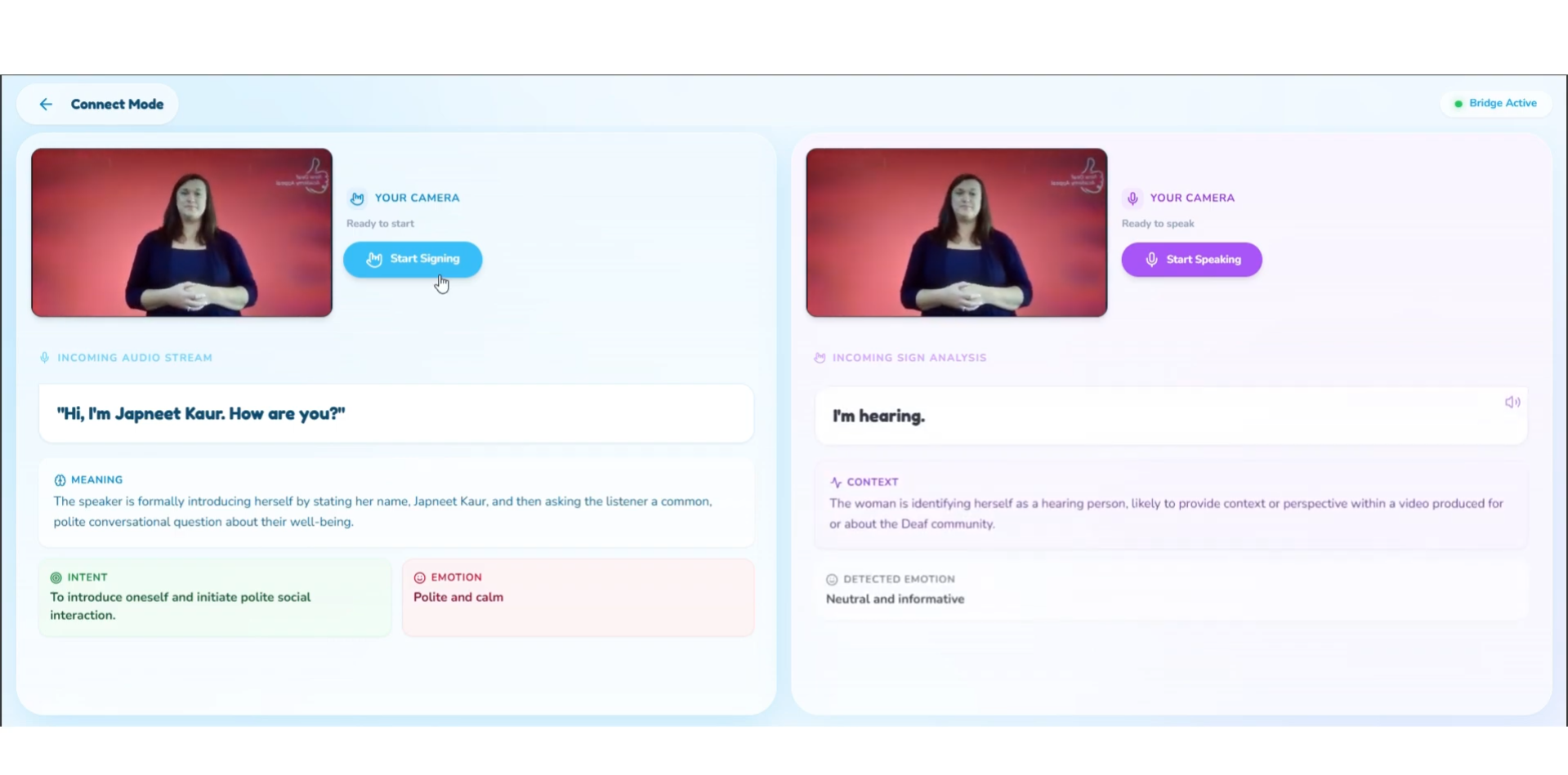
3. Connect Mode (Bidirectional Communication Bridge)
The Problem: Conversations between HoH and hearing individuals lose emotional nuance in both directions.
The Solution:
Connect Mode enables real conversations with full emotional and contextual translation.
Hearing → HoH:
Speech is converted into:
- Clear transcription (standard)
- Emotional intent ("speaking quickly, seems excited" / "slower pace, sounds uncertain")
- Idiom/metaphor explanations in real-time
- Contextual cues ("they're referencing something you mentioned earlier")
HoH → Hearing:
Sign language (via video) is recorded, analyzed, and converted into:
- Plain English meaning — not word-for-word translation, but the full intended message
- Emotional context from facial expressions — ASL grammar relies heavily on facial expressions for tone, questions, emphasis
- Optional AI-generated voice output with matched emotion (enthusiastic, concerned, joking, serious)
Real Example:
An HoH user signs: "FINISH WORK ME" with raised eyebrows (ASL question marker) and an eager expression.
- Literal translation: "Finish work me"
- BeyondWords output (text): "Are you done with work?" [enthusiastic, hoping for yes]
- BeyondWords output (voice): "Are you done with work?" [spoken with upbeat, hopeful tone]
This is not language translation — it's emotional and contextual translation.
How we built it
BeyondWords was built entirely using Google AI Studio and Gemini 3 models, leveraging the latest multimodal capabilities:
- Audio understanding — analyzing tone, pacing, vocal emphasis, and emotional markers
- Vision reasoning — reading facial expressions, body language, and sign language gestures
- Contextual reasoning over time — tracking conversational threads, callbacks, and evolving emotional dynamics
- Structured, staged inference — breaking complex analysis into deliberate reasoning steps to reduce token usage and improve accuracy
Technical Architecture:
Understand Mode:
- Video/audio → Gemini 3 Pro (audio + vision inputs with extended reasoning)
- Prompt engineering for semantic segmentation and emotion tagging
- Structured JSON output for timestamped emotional metadata
- Frontend displays interactive timeline with emotional annotations
Live Assist Mode:
- Screen capture → Continuous context monitoring
- User query triggers Gemini 3 Pro analysis with extended thinking capabilities
- Multi-turn context window maintains full conversation/scene history
- Response prioritizes comprehensive understanding of complete context
- Works seamlessly with any platform — Netflix, TikTok, Zoom, YouTube, Instagram
Connect Mode:
- Bidirectional pipeline: speech-to-meaning and sign-to-speech
- Gemini 3 Flash for conversational processing
- Gemini Live API for audio input/output handling
- Gemini vision models analyze ASL facial grammar for emotional tone
- Text-to-speech synthesis with prosody matching (Google Cloud TTS integration)
- Real-time transcription paired with emotional layering
Key Technical Decisions:
We strategically chose different Gemini models for different tasks:
- Gemini 3 Pro for Understand and Live Assist modes — where deep reasoning and comprehensive context analysis are critical
- Gemini 3 Flash for Connect mode — where conversational speed matters while maintaining quality
- Gemini Live API for seamless audio making in conversations
The frontend focuses on clarity, accessibility, and emotional readability, while the backend prioritizes intentional reasoning and complete context understanding.
Challenges we ran into
1. Interpreting sign language meaningfully, not just literally
ASL grammar is fundamentally different from English. Facial expressions carry grammatical weight (questions, negations, emphasis). We had to teach Gemini to look beyond hand shapes to the full emotional and grammatical context.
2. Balancing comprehensive analysis with user experience
Users need complete understanding, not just quick answers. We optimized Gemini 3 Pro to provide thorough context analysis while keeping responses conversational and digestible.
3. Handling diverse content types in Live Assist Mode
From formal Zoom meetings to fast-paced TikToks to dramatic TV shows — each requires different contextual awareness. We built flexible prompting that adapts to content type while maintaining consistent emotional insight.
4. Avoiding token-heavy continuous multimodal analysis
Streaming audio/video to Gemini constantly would be cost-prohibitive and unnecessary. We implemented smart context windowing and query-triggered analysis instead.
5. Designing accessibility UX without overwhelming users
Too much information is as bad as too little. We iterated heavily on how to present emotional context without making every interaction feel like a psychology lecture.
6. Handling restricted/DRM content in Live Assist Mode
Many platforms block screen recording. Screen-sharing to our system was the only viable workaround that works universally across Netflix, streaming services, and proprietary platforms.
Each challenge pushed us to make intentional trade-offs — prioritizing meaning over speed, and depth over surface-level accuracy.
Accomplishments we're proud of
✓ Successfully translating emotional intent, not just words — this is the core innovation that existing accessibility tools miss
✓ Making a complex multimodal system feel simple and human — users don't need to understand the AI; they just get answers
✓ Building a complete accessibility platform, not a single feature — three distinct modes that cover real-world use cases from entertainment to professional meetings
✓ Creating a solution that HoH users can actually trust — accuracy and nuance matter more than speed
✓ Proving that Gemini 3's multimodal capabilities can solve real human problems — not just tech demos, but genuine accessibility gaps
✓ Making social media and entertainment truly accessible — HoH users can finally understand why something is funny, trending, or meaningful
Most importantly, we proved that accessibility can be empathetic, not mechanical.
What we learned
About accessibility:
- Accessibility is not about speed — it's about understanding. Complete context matters more than instant responses.
About communication:
- Emotion is a critical layer of communication — often more important than the literal words. Ignoring it isn't just incomplete; it's exclusionary.
About AI design:
- AI is most powerful when it adapts to humans, not the other way around. We didn't build a system that forces users to learn AI. We built AI that learns human communication.
About engineering:
- Thoughtful model selection and trade-offs matter as much as raw capability. Gemini 3 Pro for deep reasoning, Flash for real-time conversation, Live API for audio — each choice serves a specific purpose.
About impact:
- The best accessibility tools don't feel like assistive technology — they feel like understanding. When users stop thinking about the tool and start understanding the conversation, you've succeeded.
About entertainment accessibility:
- Cultural context and social references are as important as dialogue — understanding why something is funny or trending is essential for true inclusion in digital spaces.
What's next for BeyondWords
Our vision is to take BeyondWords from prototype to product. Here's our roadmap:
Phase 1: Beta Launch & Community Testing
- Partner with deaf/HoH community organizations for authentic user testing
- Recruit beta testers to refine emotional accuracy and UX across different content types
- Measure key metrics: comprehension improvement, user satisfaction, cultural reference understanding
Phase 2: Platform Expansion
- Browser extensions (Chrome, Firefox) for seamless use across YouTube, Netflix, Zoom, TikTok, Instagram, and more
- Mobile app (iOS/Android) with camera-based Live Assist for in-person conversations
- Wearable integrations (smart glasses concept) for ambient assistance
Phase 3: Technical Improvements
- Optimize context processing for even faster insights while maintaining accuracy
- Expand sign language support beyond ASL (BSL, Auslan, ISL, etc.)
- Train custom fine-tuned models for emotion detection using HoH community feedback
Phase 4: Partnerships & Scale
- Partner with educational institutions (universities, online learning platforms)
- Integrate with enterprise communication tools (Slack, Microsoft Teams, Google Meet)
- Collaborate with accessibility advocacy groups to ensure authentic, community-driven development
- Partner with streaming platforms to integrate directly into their interfaces
Phase 5: Research & Advocacy
- Publish open research on emotional accessibility
- Advocate for accessibility standards that include emotional and contextual understanding, not just transcription
- Contribute to open-source accessibility tooling
Our ultimate goal is simple:
Make human meaning accessible to everyone.
Not just words. Not just captions.
Understanding.
Whether you're watching your favorite show, scrolling through TikTok, sitting in a work meeting, or having a conversation with a friend — you deserve to understand what's actually being communicated.
Built with: Gemini 3 Pro, Gemini 3 Flash, Gemini Live API, Google AI Studio, Google Cloud TTS
For: The 466 million HoH individuals worldwide who deserve to understand conversations the way they were meant to be understood
By: A team that believes accessibility is a right, not a feature



Log in or sign up for Devpost to join the conversation.