-
-
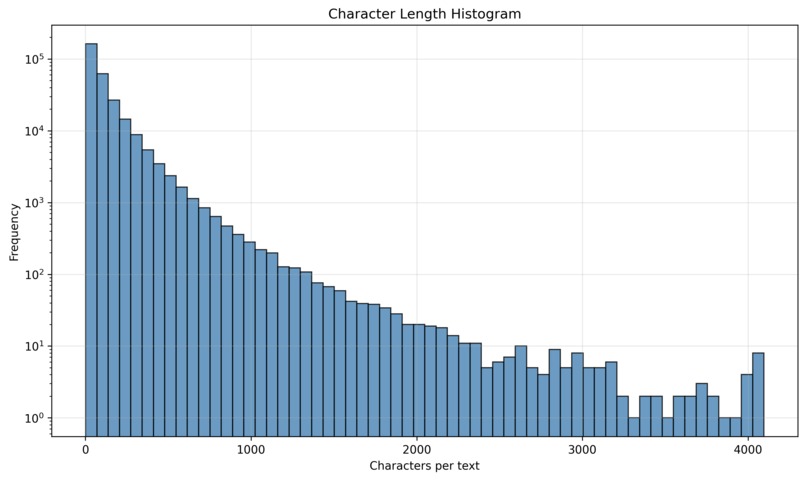
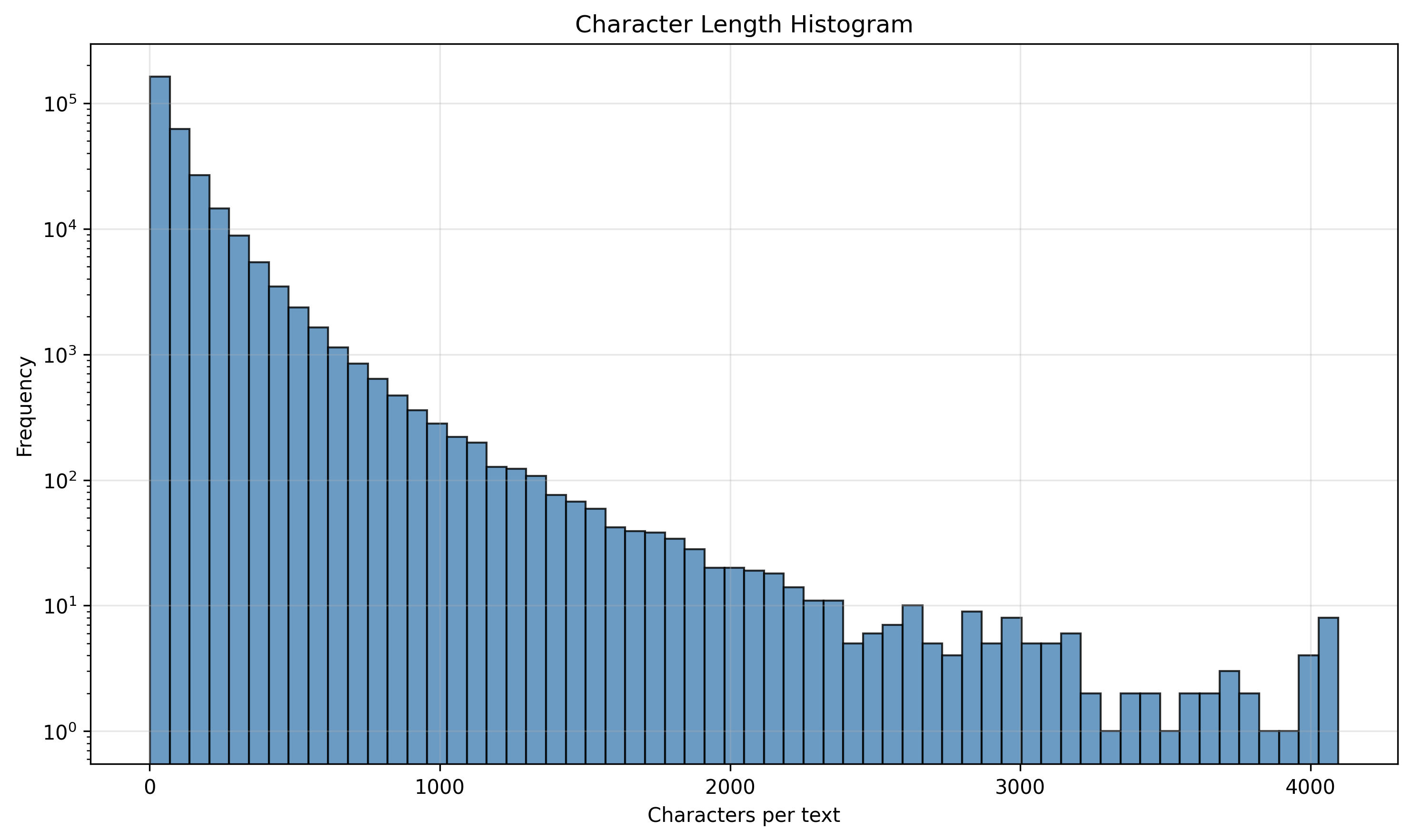
Character Length Histogram
-
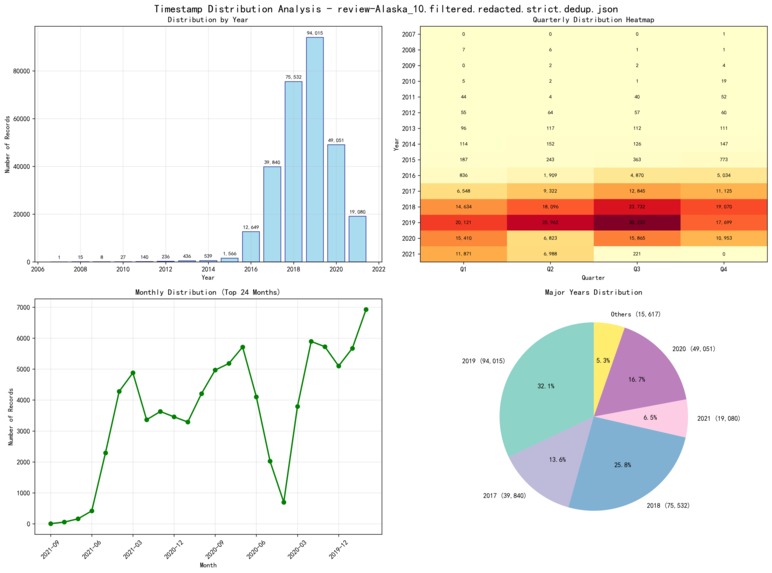
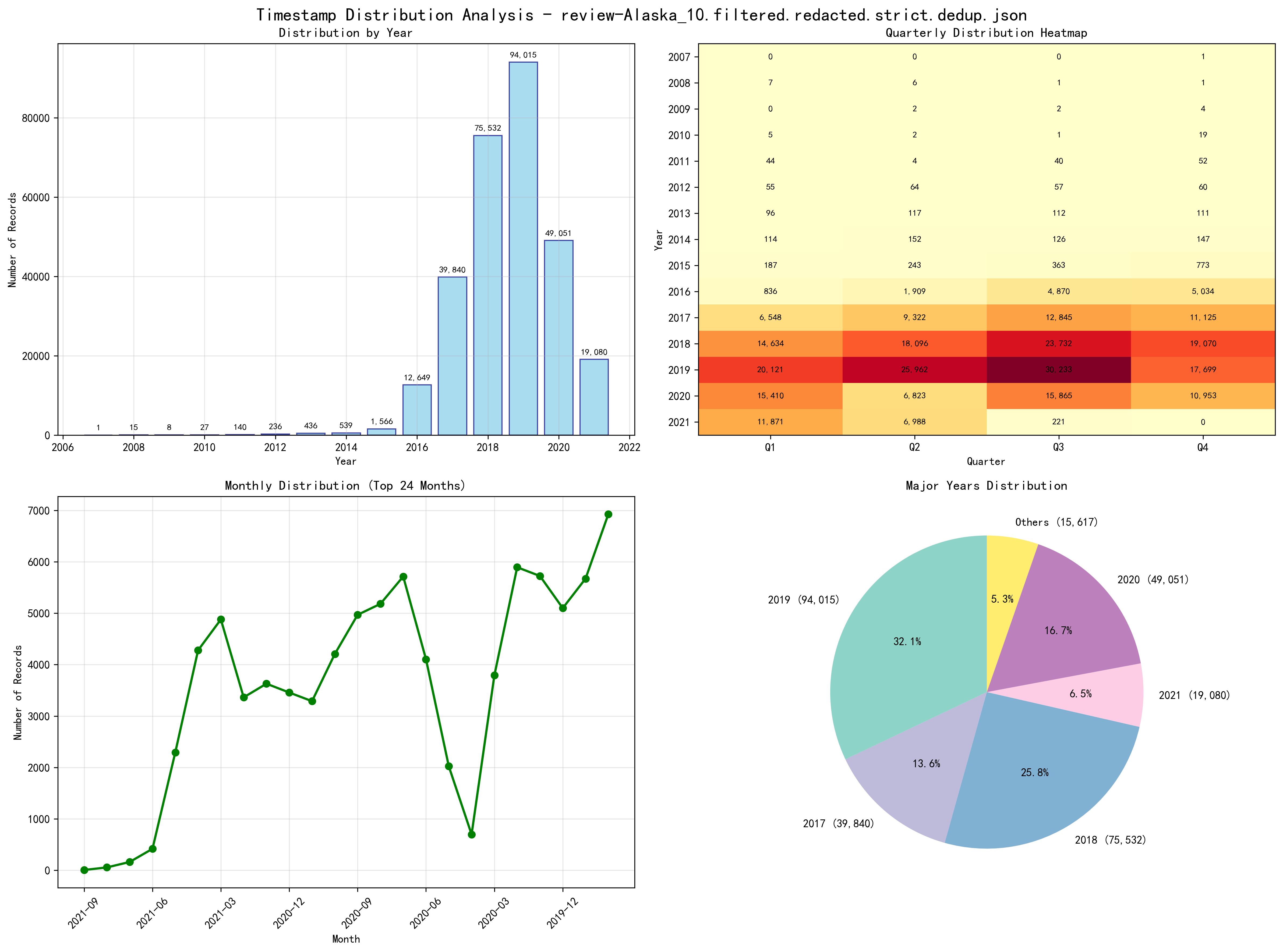
Timestamp Distribution Analysis
-
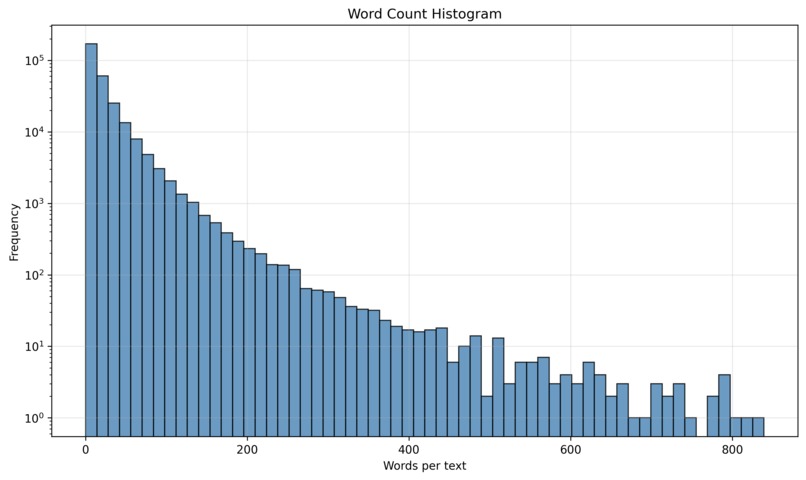
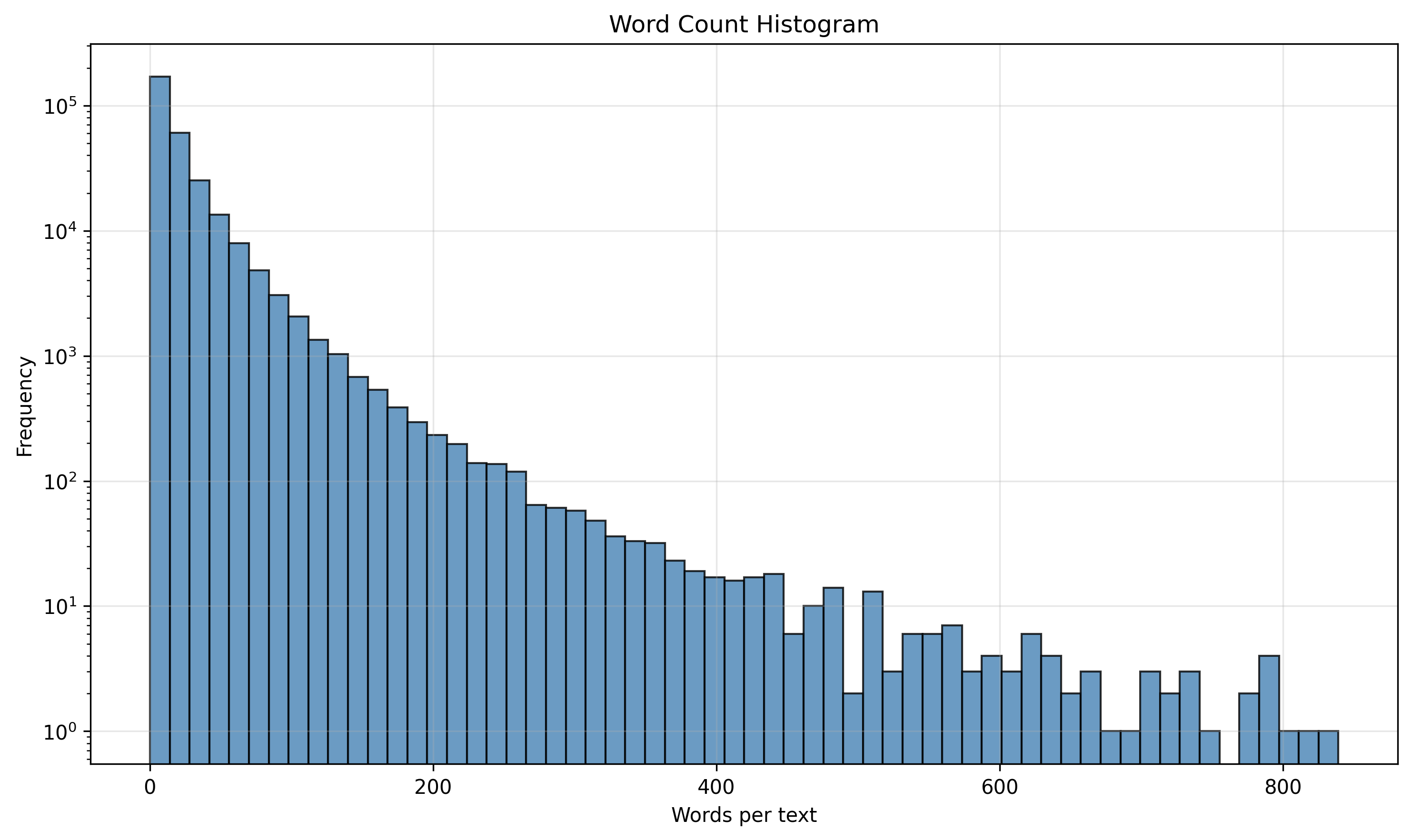
Word Count Histogram
-
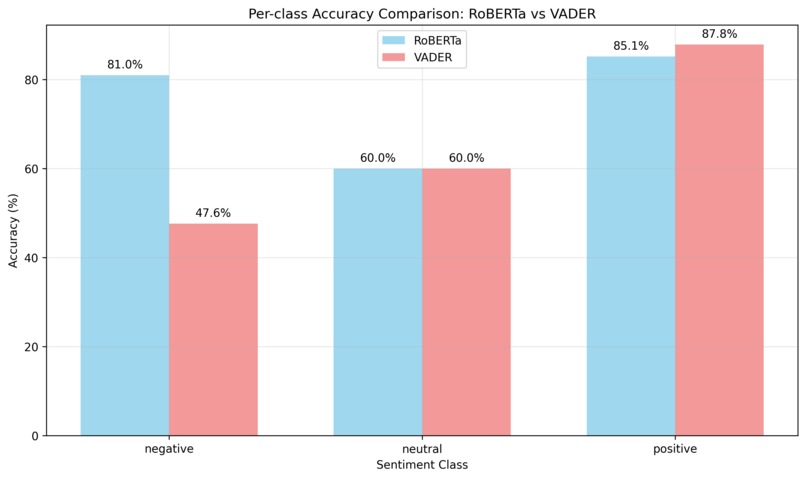
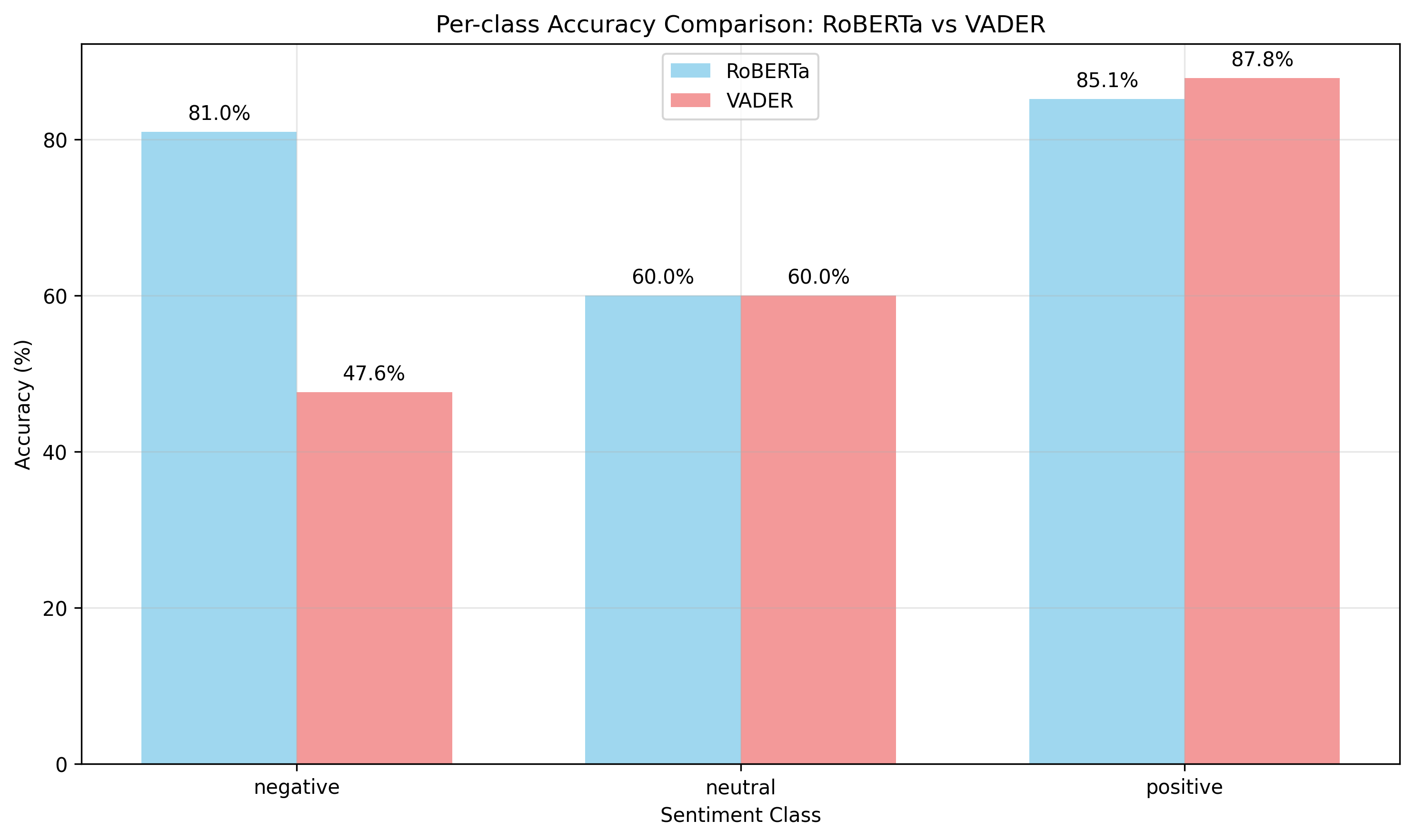
Per-class Accuracy Comparison: RoBERTa vs VADER
-
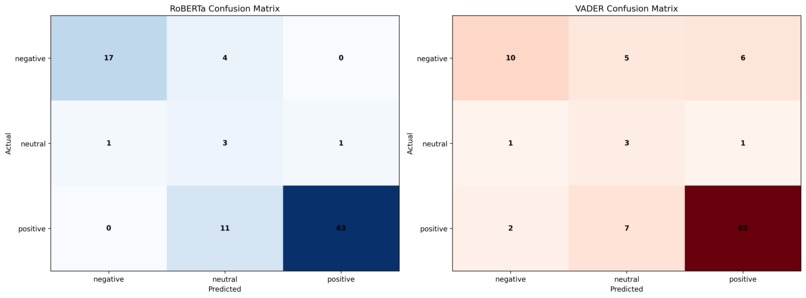
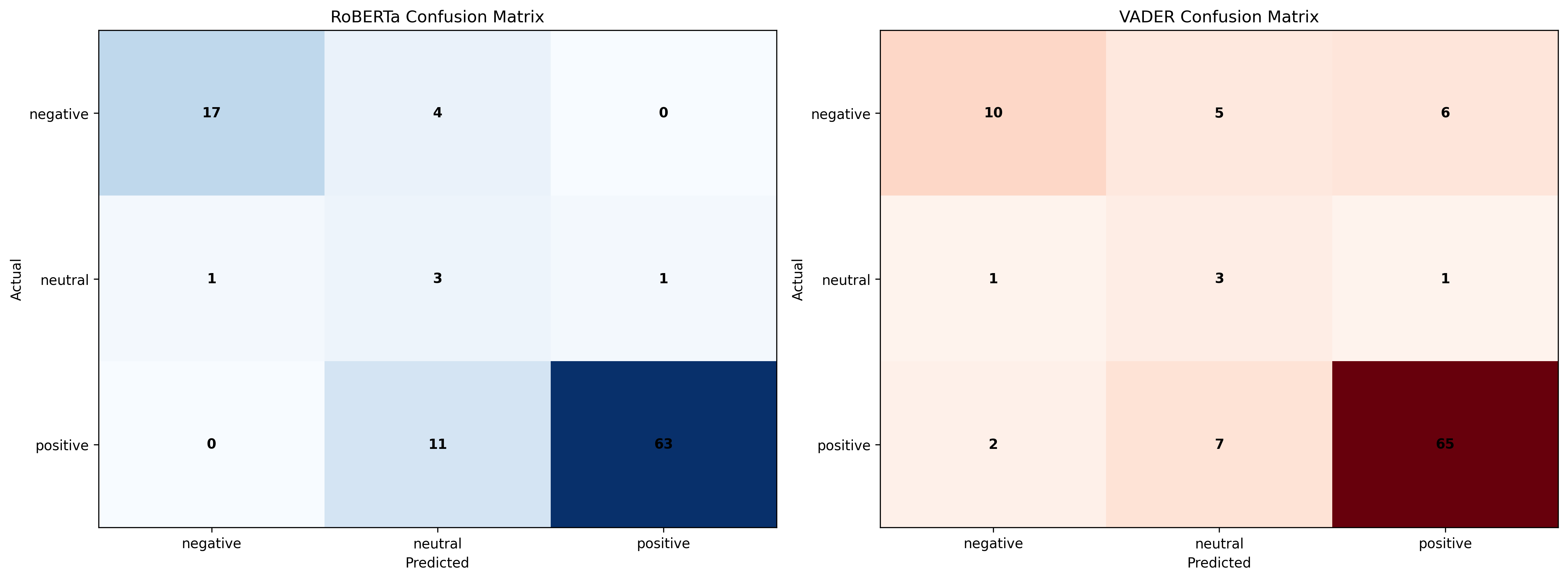
Confusion Matrix
-

Word Cloud Visualization of Preprocessed Text
-

Negative Word Cloud
-

Positive Word Cloud
-
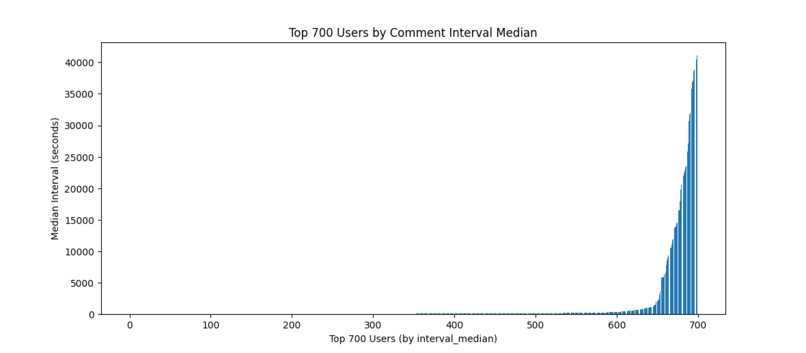
Suspicious users




Inspiration
Ratings aren’t enough. Location platforms are flooded with noisy, off-topic, or promotional reviews that warp reputation and waste attention. Manual moderation doesn’t scale. Beyond Stars, Towards Trust asks: how do we score trust with little to no labels, and make the decision explainable enough to act on?
What it does
- Cleans and normalizes reviews (PII masking, dedup, text normalization).
- Generates pseudo-labels via labeling functions (LFs): promo/template cues, entity-density spikes, sentiment–rating conflicts, bursty users, emoji overload, etc.
- Runs two complementary prototypes:
- RoBERTa classifier (end-to-end).
- RoBERTa embeddings + XGBoost (tabular-friendly decision boundary).
- Outputs a trust score, predicted class, and which LFs fired for transparency.
- Provides batch analysis (n-gram/word clouds, length vs rating, sentiment vs rating, inter-review intervals) and a demo with a threshold slider for different operating points.
How we built it
- EDA & Prep: Removed empties; replaced emails/phones/URLs with placeholders; deduped by
(gmap_id, user_id, text); normalized (lowercasing, stopwords, punctuation/digits removal, lemmatization). - Weak Supervision: Implemented LF library and weighted voting to produce high-confidence pseudo-labels
- Models:
- Fine-tunable RoBERTa + FC + softmax.
- Embedding extractor (RoBERTa) feeding XGBoost for a strong non-neural baseline.
- Evaluation & Viz: Scripts for AUC/F1/Precision@Untrusted, confusion matrices, top-triggered LFs, and slice metrics.
- Demo: Optional Gradio app for single/batch inference, rule hits, and operating-point control.
- Stack: VSCode, Jupyter, PyTorch, Hugging Face Transformers, scikit-learn, pandas, numpy, matplotlib, wordcloud.
Challenges we ran into
- No/low labels: Designing LFs that are broad enough to cover noise but precise enough to avoid over-flagging.
- Domain noise: Neutral sentiment often confuses rating alignment; off-topic detection needs signals beyond keywords.
- Balance of metrics: Tuning for high precision on “untrusted” vs overall F1 is a pragmatic trade-off.
- Time & compute constraints: Building an end-to-end, reproducible pipeline while keeping training iterations lean.
Accomplishments that we're proud of
- A label-efficient pipeline from raw text → pseudo-labels → dual modeling paths → explainable outputs.
- A reusable LF library that captures common abuse patterns (promo/templates, bursts, emoji, entity density).
- An interpretable demo that exposes rule hits and lets reviewers choose operating points.
What we learned
- Weak supervision works: Good LFs + conservative voting can bootstrap useful training signals fast.
- Interpretability is adoption: Showing why a review is flagged (LF hits, token importances) builds trust with ops teams.
- Behavioral context matters: User-level patterns (bursts) add signal that pure text often misses.
What's next for Beyond Stars, Towards Trust
- Human-in-the-loop: Active learning on most-uncertain samples to quickly improve LFs and models.
- Calibration & fairness: Temperature scaling/ECE, plus category/language slices for consistent thresholds.
- Multilingual & domain transfer: Extend beyond English and adapt to new verticals with minimal retuning.
Built With
- google-maps
- huggingface
- nltk
- python
- roberta
- vscode
- xgboost



Log in or sign up for Devpost to join the conversation.