-
-

-

Prediction of adverse symptoms
-

Prediction in Mobile Interface
-

Workflow of Slimming process



Abstract
Drugs can produce intended therapeutic effects ,however they may also cause side effects at the same time. An undetected side effect for an approved drug is harmful for humans and may bring great risks for a pharmaceuticals company. For an approved drug, it is best to detect all side effects it can produce. Due to lack of awareness of side effects, many clinical problems occur frequently, such as acute and chronic poisoning, drug abuse and increasing drug-related morbidity.
Novelty
Drug side–effects are triggered by complex biological processes involving many different entities, from drug structures to protein–protein interactions. Predicting the probability of side–effects, before their occurrence, is fundamental to reduce this impact, in particular on doctor’s prescription.
Problem statement
Side-effects can occur either when taking a drug as prescribed or as a result of incorrect dosages, interaction of multiple medicines, or off-label use. What if we could anticipate the adverse side effects based on their current medical data from their prescription which can help them to prevent the side effects?
Solution
We can help the patients to identify whether a prescribed drug has fewer or no negative side effects by predicting the adverse side effects of the drug based on usage. On uploading the prescription as document/image, the patient will be able to get the possible adverse side effects of each particular drug in the prescription. If a new medication needs to be prescribed, the doctor can do so based on the anticipated side effects. The proposed solution can benefit the doctor and patient by helping them understand the effects of a particular drug intake. This can be achieved by using AWS Comprehend Medical , AWS Textract and Classifiers.
Training a model
For creating the model we need a well reputated dataset which consists of many important features which helps to predict the exact drug adverse reactions. The adverse effects dataset provided by Food and Drug Administrative (FDA) was used to train the model. We shortlisted the top 25 drugs based on number of drug samples present in the dataset. Similarly, the 21 most occurring symptoms was chosen from the data. We eliminated other symptoms which are not commonly observed due to drug intake. With the extracted features we provide the data to our K-Nearest Neighbors classifier which uses proximity to make classifications by grouping the individual data points. The trained model achieved an accuracy of 94.3% with a recall score of 70.1%.

Building blocks of the Prediction
To interact with hybrid clients such as mobile as well as browsers, we decided to create an API which helps to communicate with hybrid platforms. FastAPI was chosen to make HTTP requests. The endpoint receives prescription file as input which is later processed by set of instructions. The given prescription image is processed by AWS Textract which extracts all textual information in the prescription. The extracted textual information is processed by AWS Comprehend Medical service where it can extract medical information from unstructured medical text like doctors’ notes , clinical trial reports, or radiology reports. It also identifies relationships among extracted health information and links to medical ontologies like ICD-10-CM, RxNorm, SNOMED CT. It upholds patient's data privacy and protected health information (PHI) with a HIPAA–eligible service. The extracted drug data based in InferRxNorm will be provided to the pre-trained model which will predict the adverse reactions of the drug and returns the output. By analyzing the predicted results, a medical professional can predict the adverse reactions of the drug in prior before prescribing the drug to a particular individual.

Why containerising an application ?
Container is a type of an operating system virtualization which helps in the efficient running of applications across platforms with minimum consumption of resources. They are lightweight and portable, a major point to consider while deploying them in cloud.Many organizations, both large and small, are looking at containers as a means to improve application life-cycle management through capabilities such as continuous integration and continuous delivery.

Why hardening of image ?
Hardening is the process of strengthening a system to reduce the exposure surface and attack vectors using different tools and configurations. Images have the file systems, binaries, package managers, libraries and other programs which required to make the application run. However, a container is a standard unit of software that packages up code and all its dependencies, so the application runs quickly and reliably from one computing environment to another.
Architecture of the product

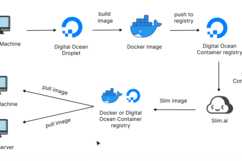
Workflow of Sliming Process
The product which was developed by many developers is stored in a unique server . The Dockerfile written by developers helps to build a docker image for that product . Later it is pushed to container registry such that we get a variety of options to work on with the images. The container registry is connected with slim.ai using connectors . Later the image is hardened by Slim AI and the output is provided with vulnerability report. The slimmed image is later pushed to container registry and made public or private depending on the usage. The image can be pulled from the registry by many machines and can create its own choice of containers to run the product.

Vulnerability Report of Container
Slim.ai generates report on Image without hardening.

Comparing container images
beyolix : latestwithbeyolix : latest-slim.
Challenges we ran into
- Collecting and Preprocessing the FDA dataset was quite a challenging part .
- The user interface integration of our classifier model was challenging.
- Working with a classifier model was a difficult portion of the project.
- It was interesting to work on with some AWS Services.
- Setting up AWS secrets was quite difficult to work on.
- Deploying the application in live using digital ocean droplet.
What we learned
- We learnt more about production environment.
- We were able to spend our digital ocean credits wisely which helped us to know about more services.
- Working on with docker was quite interesting.
- When coming to hardening of image based on CIS standard manual hardening was quite hard which we were able to resolve using SLIM AI which was quite astonishing to use .
- It provided many efficient ways such as connector etc to work on with hardening of image.
- We came upon to know about many services provided by AWS which was one of the good part.
- We also learnt to create and consume API in react JS and flutter.
Accomplishments that we're proud of
- We were successful in developing a remarkable approach that can helps to predict the adverse side effects of a drug .
- Using AWS Comprehend as well as AWS Textract to process the document was an asthetic part
- Was able to develop a classifier model using FDA drug dataset.
- It was amazing to think of creating a native mobile application and using this concept.
- Providing interfaces in two different platforms for ease use .
- Bringing the application live into production and containerizing it for better virtualization.
- Hardening of image to enhance security and size of the image thus reducing the cost of usage.
What's next for Beyolix
- Suggesting medications which has less or no complications.
- Giving personalized feedback for each person
- By incorporating regional languages the document can be processed in native languages .
- Improving models accuracy for better performance of the application.
- The application can also be extended to Drug Discovery Analysis .
Built With
- aws-comprehend-medical
- aws-textract
- digitalocean
- docker
- dockerhub
- fastapi
- flutter
- slimai


Log in or sign up for Devpost to join the conversation.