Inspiration
Traditional language learning apps treat vocabulary as isolated flashcards, disconnected from real-world context. We wanted to create something different: an app where you learn languages the way people actually use them in conversations. By practicing through immersive scenario-based dialogues with an AI tutor, learners develop practical communication skills rather than memorized word lists.
What it does
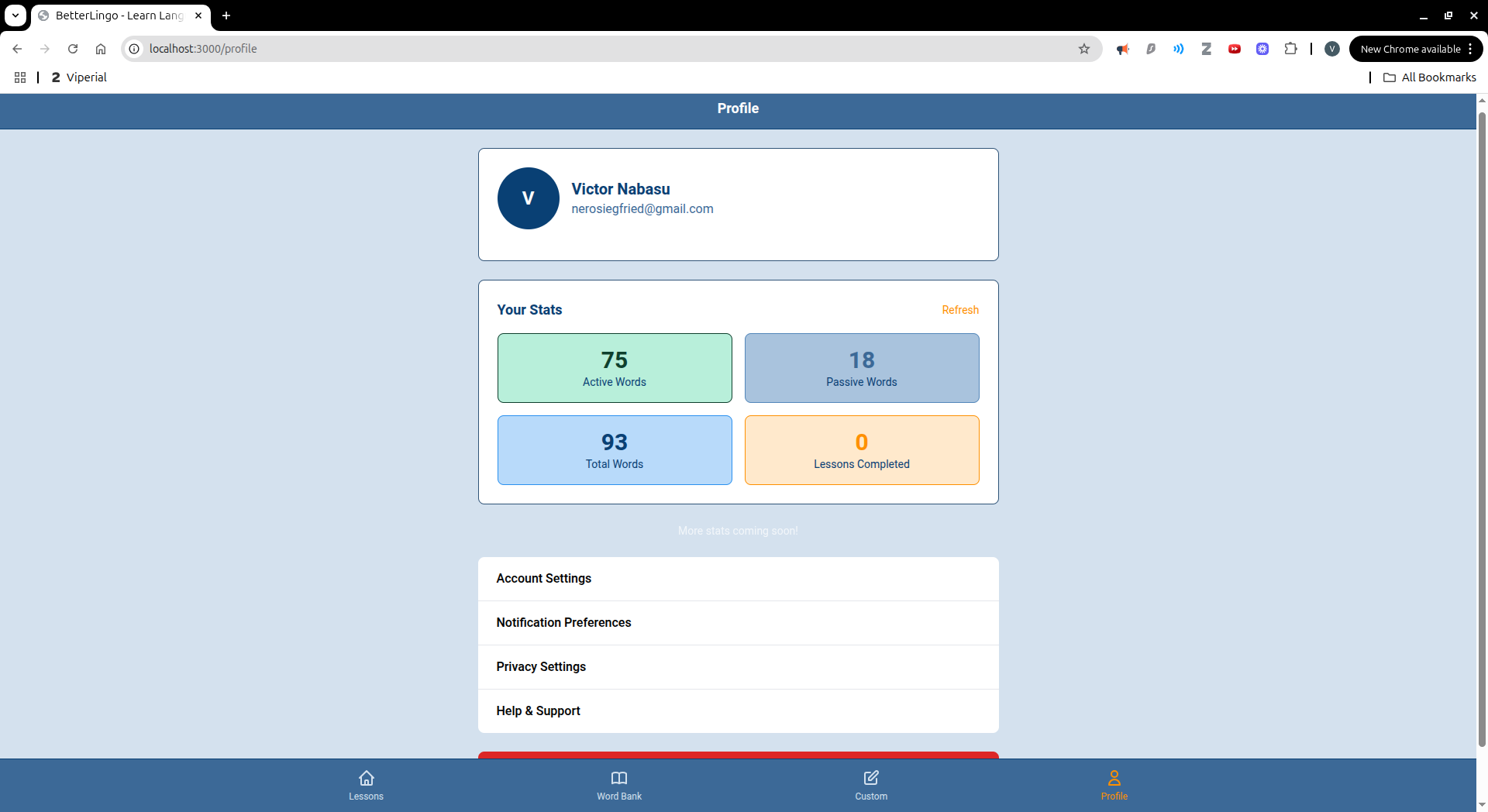
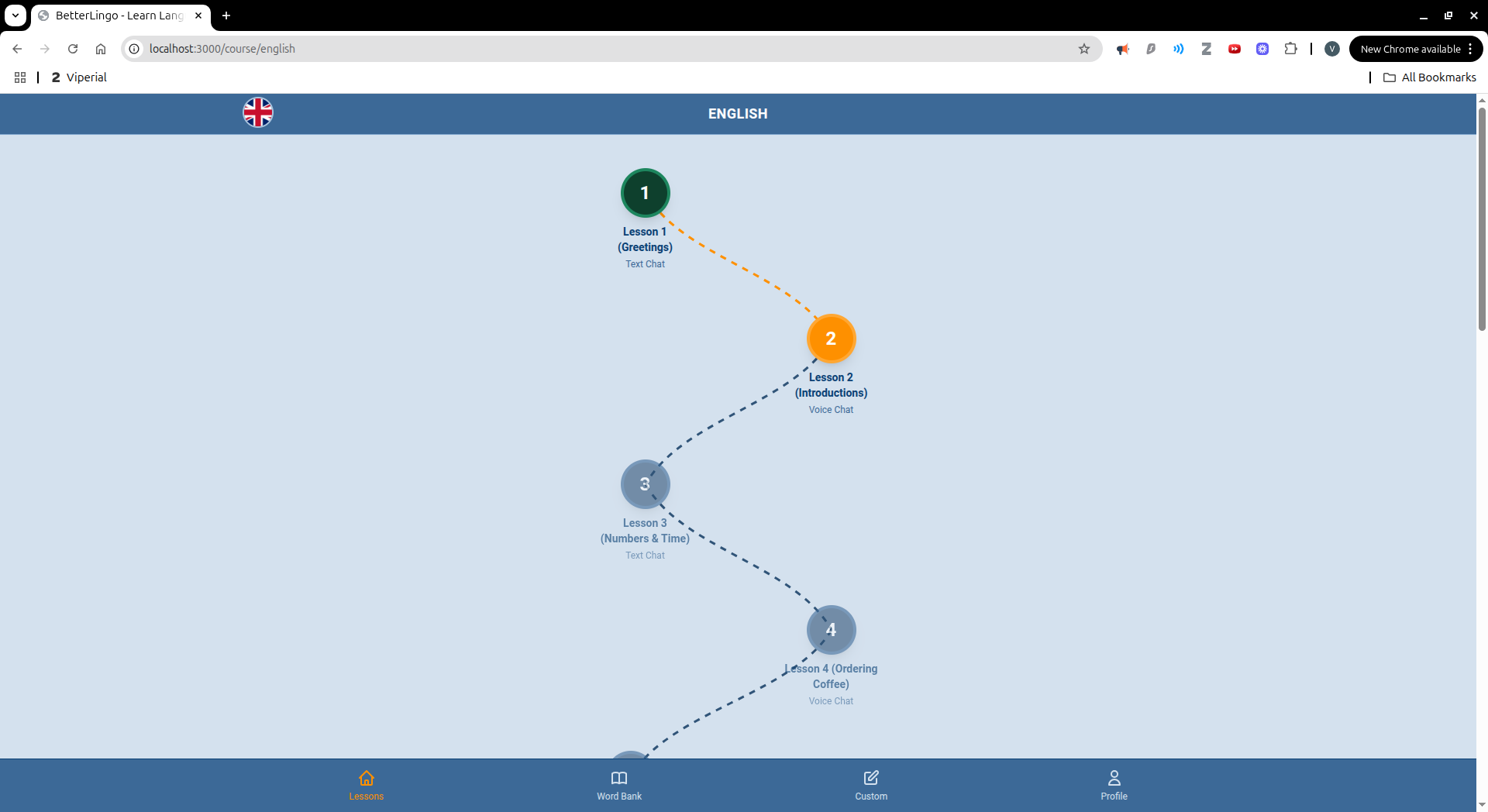
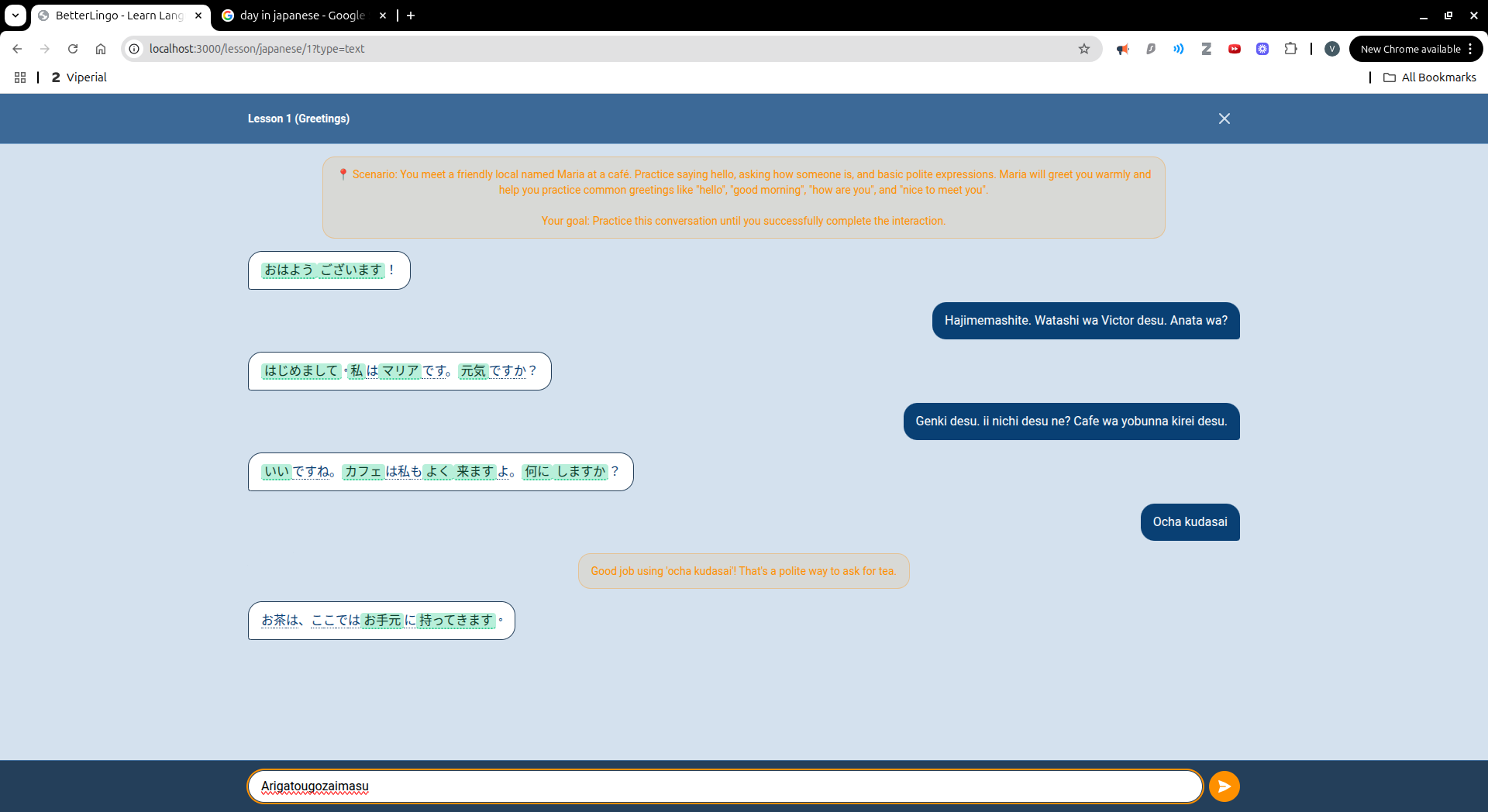
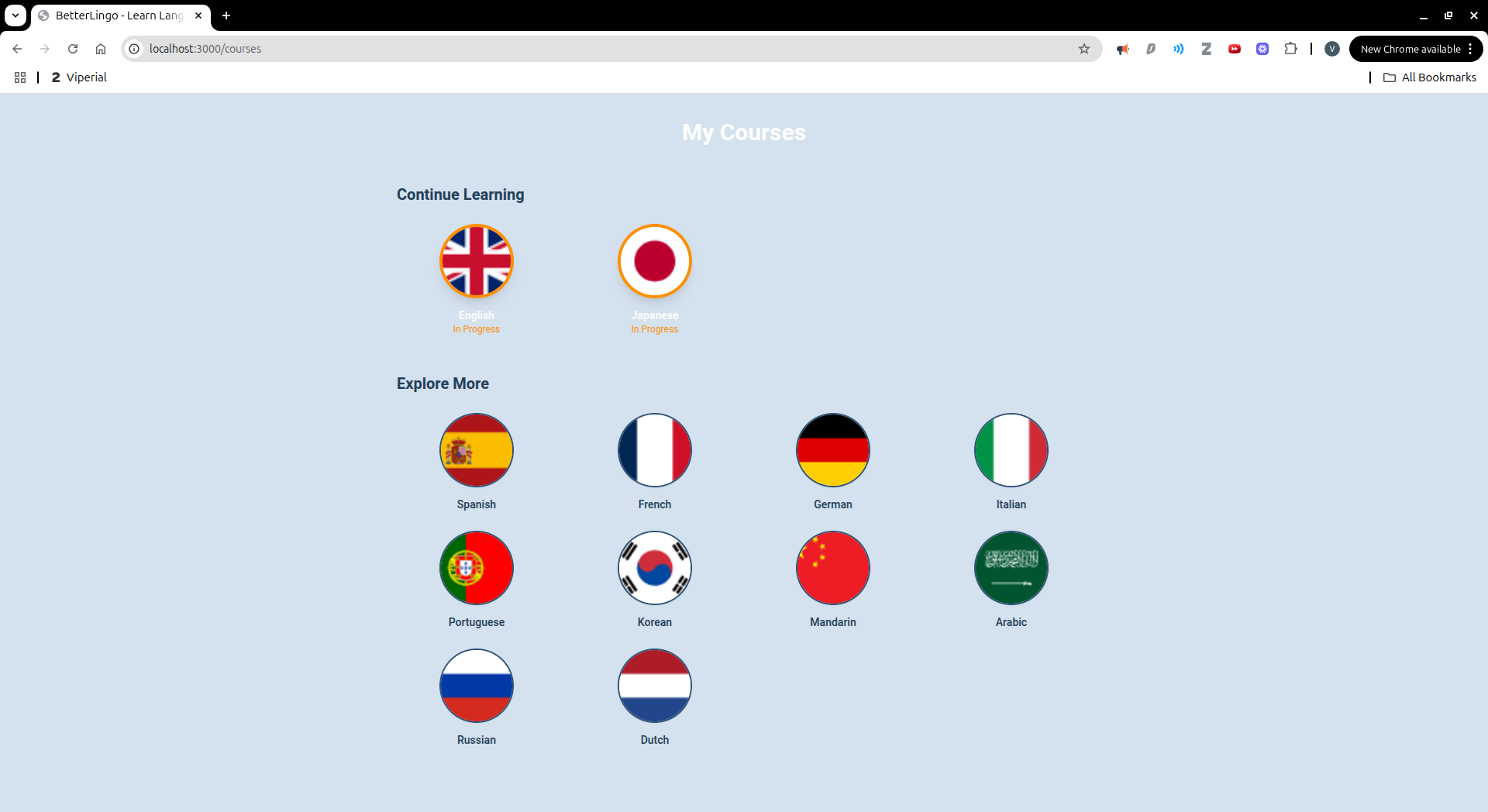
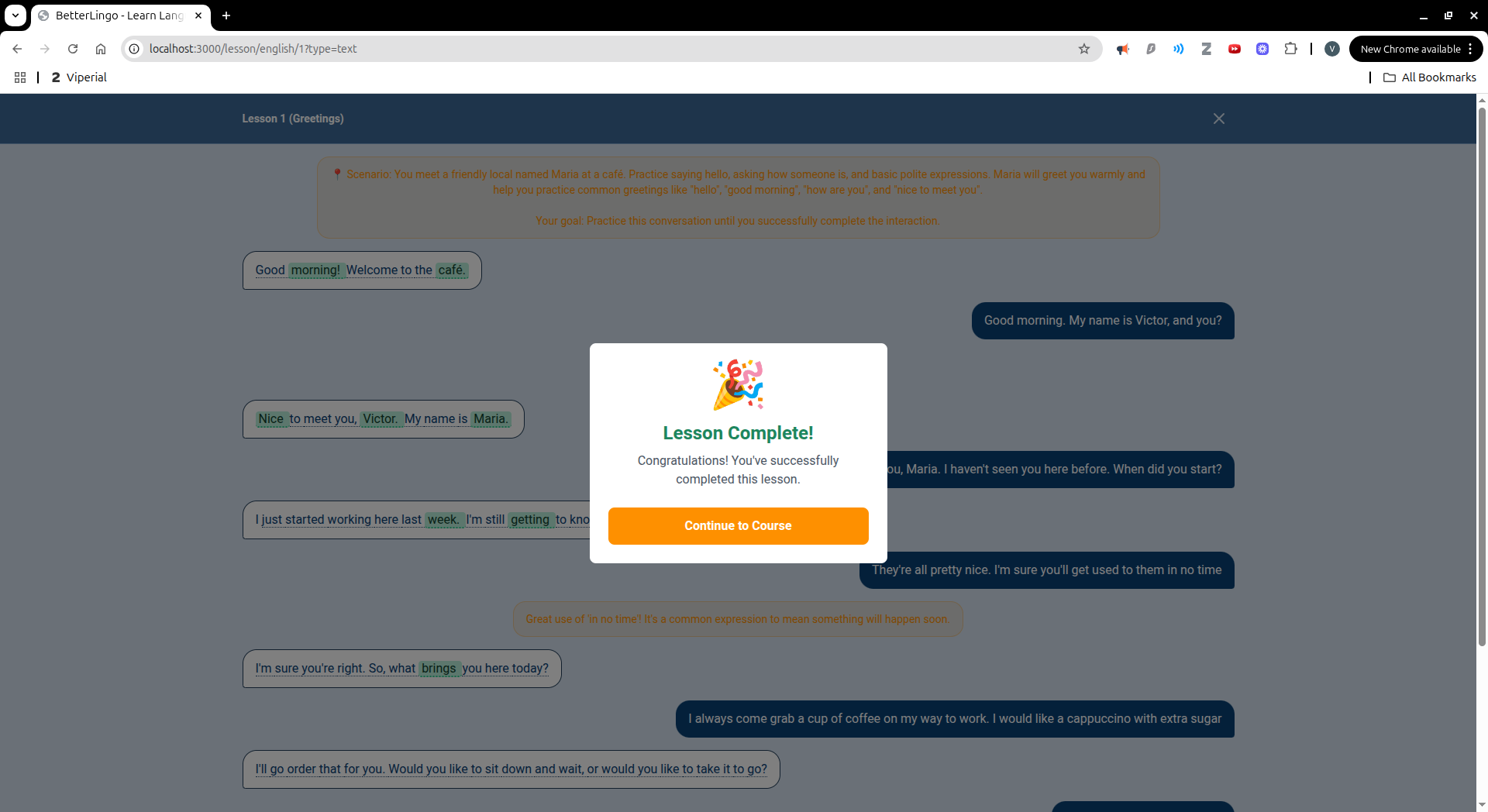
BetterLingo is an AI-powered language learning platform that teaches languages through contextual conversations. Instead of drilling isolated vocabulary, you have natural conversations with an AI tutor who plays a character in realistic scenarios like ordering at a café or introducing yourself. The app automatically identifies new vocabulary from conversations, builds your personal word bank, provides instant corrections and feedback, and offers multiple practice modes including matching games, translation exercises, and sentence building activities.
How we built it
We built BetterLingo using Next.js for the full-stack framework, React for the frontend UI, Prisma with Supabase PostgreSQL for data persistence, and Groq's API for real-time AI conversations. The app uses JSON mode enforced by the LLM to ensure consistent, parseable responses. For voice lessons, we implemented the Web Audio API with silence detection to provide natural recording experiences. The word bank system intelligently tracks vocabulary status across conversations, and the practice games are built with React state management to create engaging, interactive learning experiences.
Challenges we ran into
The biggest challenge was getting the LLM to consistently return properly formatted JSON responses. We went through multiple iterations of prompt engineering before implementing Groq's response_format with JSON mode to enforce strict formatting. Another major hurdle was correctly parsing and storing new vocabulary from conversational responses without storing incomplete or malformed words. We also struggled with database connection pooling and prepared statement caching with Supabase, requiring us to switch between pooler and direct URLs during development. Additionally, distinguishing between what should be conversational dialogue versus teaching feedback in LLM responses required careful prompt redesign and message ordering logic. The LLM is also quite a simple one and it makes unreasonable mistakes sometimes; a better quality model would greatly improve the program
Accomplishments that we're proud of
We successfully built a system where new vocabulary is automatically extracted and tracked from every conversation without manual curation. The silence detection for voice lessons creates a natural recording experience that adapts to user speech patterns. We implemented intelligent word highlighting that knows whether a word is new or already learned by the student. The system correctly separates AI character dialogue from teaching feedback, providing both immersion and pedagogical guidance. We also created a flexible practice game system that adapts to the learner's word bank, allowing multiple reinforcement modes beyond simple flashcards.
What we learned
We learned that LLM consistency requires explicit constraints at the API level, not just in prompts. We discovered that database connection management is critical in development versus production environments. We realized that language learning UX requires careful separation of concerns: immersive conversation, immediate feedback, and spaced repetition practice need to coexist without interfering with each other. We also learned that voice-based input benefits from intelligent automation rather than arbitrary time limits. Finally, we understood that storing metadata about vocabulary status (times used, times seen, learning stage) is essential for creating adaptive, personalized learning experiences.
What's next for BetterLingo
Firstly, because this is a prototype and is poorly polished as a result, we want to improve the app until it is ready for the market. We plan to expand to more languages beyond Japanese and add support for different proficiency levels within each language. We want to implement spaced repetition algorithms that optimize when vocabulary is revisited based on learning science principles. We're exploring adding a community aspect where users can share scenarios and compete on leaderboards. We also want to improve the LLM's ability to generate more nuanced teaching feedback tailored to individual learning patterns. Finally, we plan to add support for multiple conversation styles and personalities so the AI tutor can adapt to different learning
Built With
- groq
- next.js
- nextauth
- node.js
- prisma
- react
- supabase
- tailwind-css
- typescript
- web-audio-api

Log in or sign up for Devpost to join the conversation.