Inspiration
Using this as my first Berkeley Hack A Thon I wanted to focus on a small task first without doing too much, especially when doing this project solo. This is why I tried to create a cheap compression model for AI prompts.
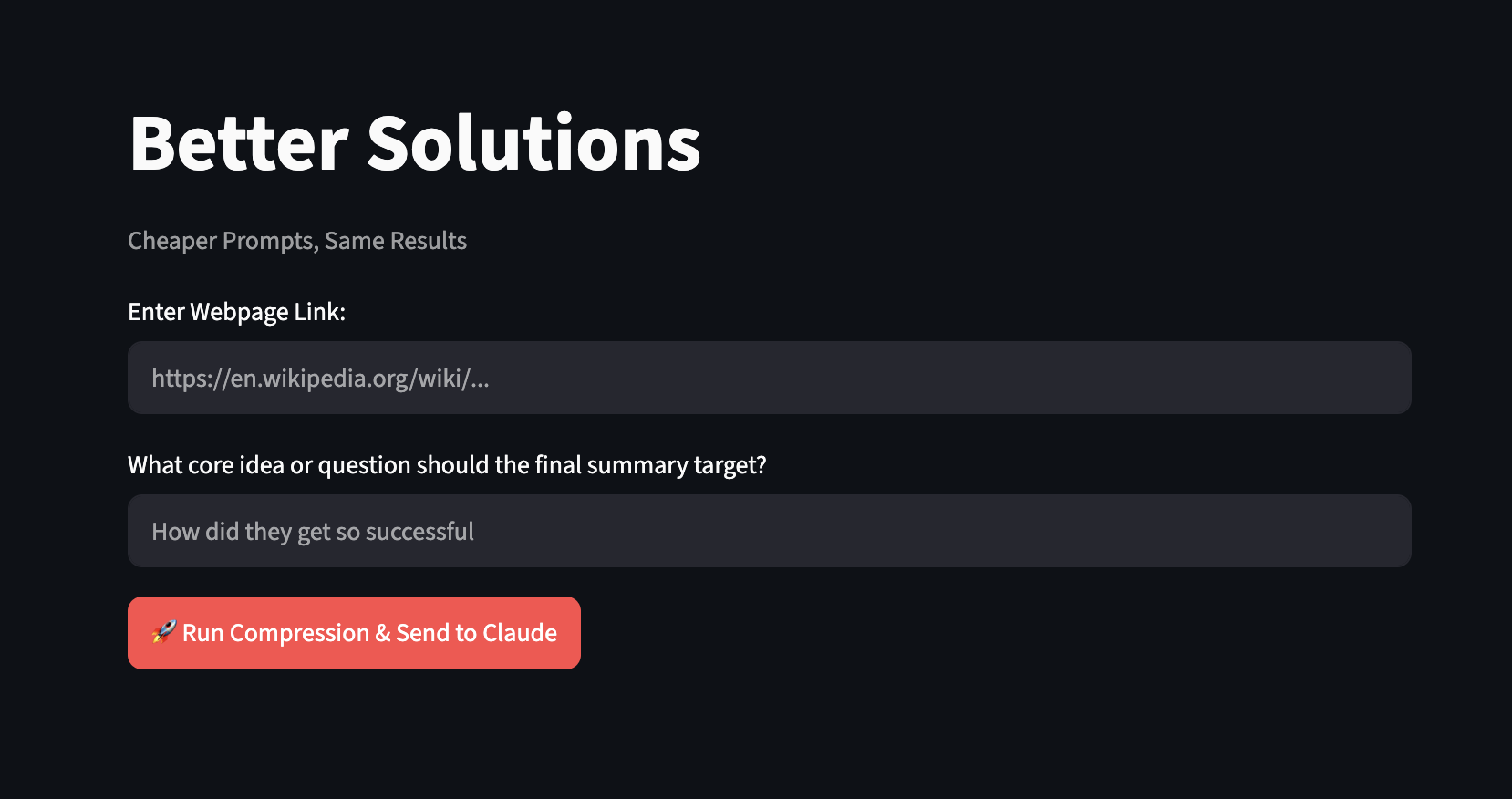
What it does
First you submit a website and a prompt. Then the cross encoder reranker scores every paragraph against the user's prompt and keeps only the most relevant segments. Then LLMLingua-2 compresses the surviving text by trimming filler words and connectors. Then with a new less token and compressed prompt, it's provided to Claude AI and it outputs the answer.
How we built it
I built it by using a streamlit app which allowed me to have a website through visual studio code. Had Web scraping by using requests and BeautifulSoup, with custom filtering to strip footnotes and reference before taking in the text. The reranking stage uses a sentence-transformer CrossEncoder to help pick which paragraphs are worth keeping. Compression runs through Microsoft's LLMLingua-2. Then use Anthropic token counting and put the output through Claude AI with RAG guidelines to improve output quality.
Challenges we ran into
The compression model was either taking out too many tokens and reducing too much information or was keeping too many tokens and it had not useful information. There is too much overlap between the two compression models where sometimes it compresses so much that I had only 100 tokens from a 40k token request.
Accomplishments that we're proud of
Was able to get a finished project by deadline and have something to show for it. I'm glad there are some working systems for submitting big or small files into the system and trying to create the smallest token request through input and output.
What we learned
I learned how to use Hugging Face more effectively. I also learned how to set up streamlit and overall have a website behind my project. I also learned more use and understanding of tokens and how to utilize them towards cheaper and more efficient methods. I also learned different compression models and how I can compress data for different uses for how much readability I want left.
What's next for Better Solutions
After judging, I will try to create more methods of compressor, try to build an even more fast responding request from typing in the prompt and getting an answer, and building a more native website system to where I could even publish it on a domain.
Built With
- claude-api
- huggingface
- python

Log in or sign up for Devpost to join the conversation.