-
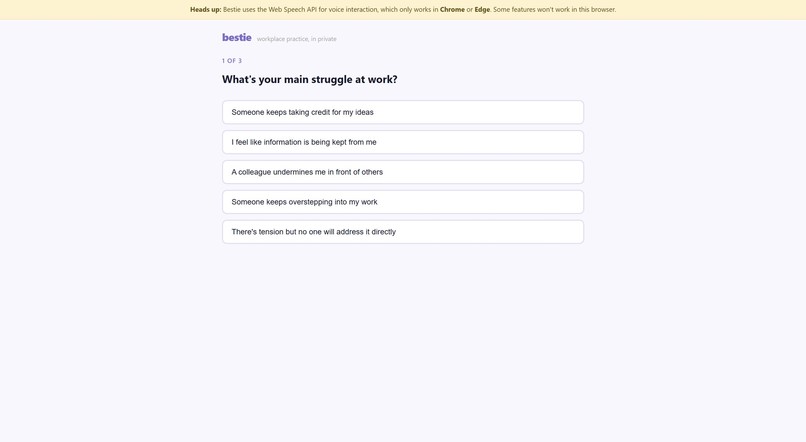
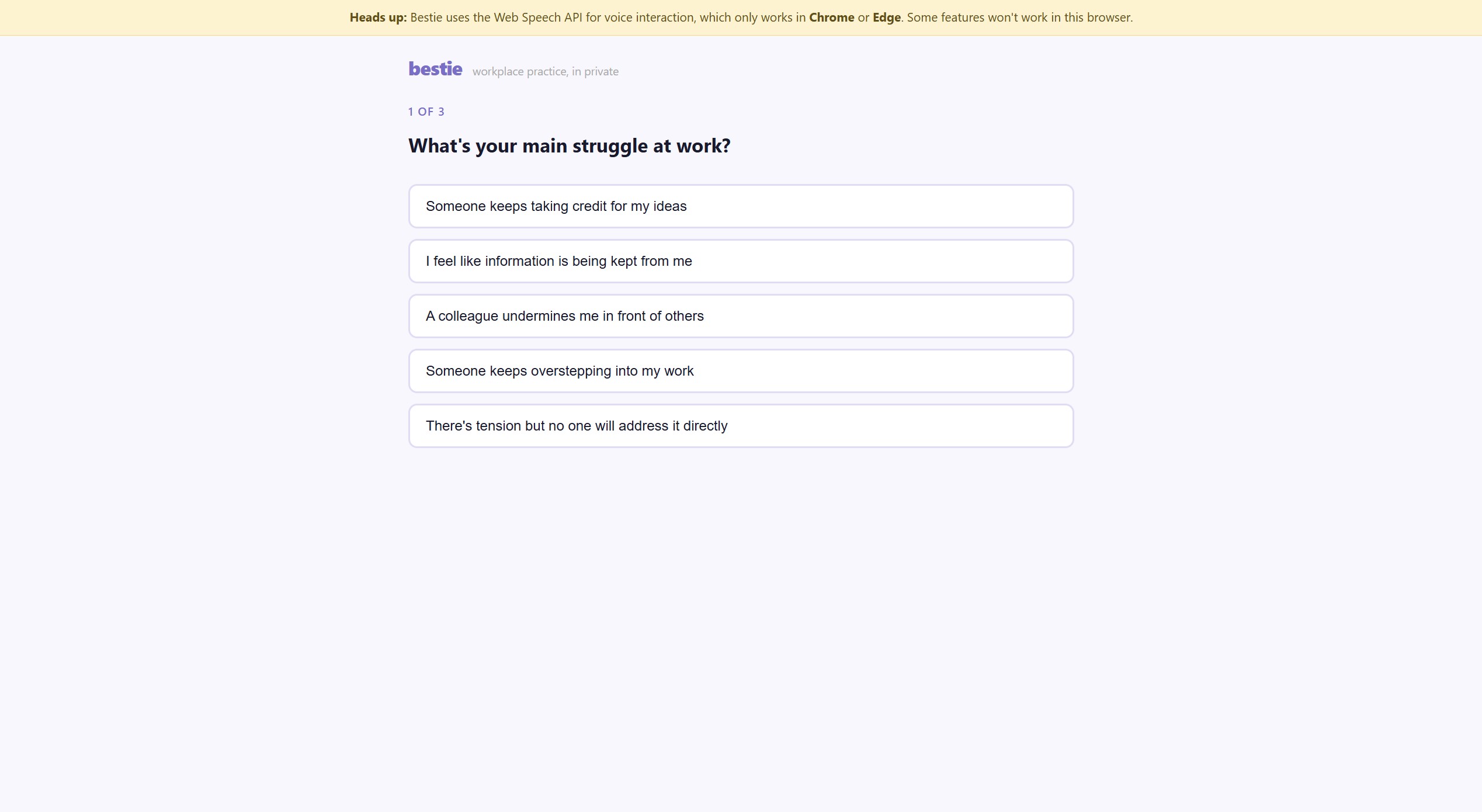
Questions Screen to recommend best match for practice
-
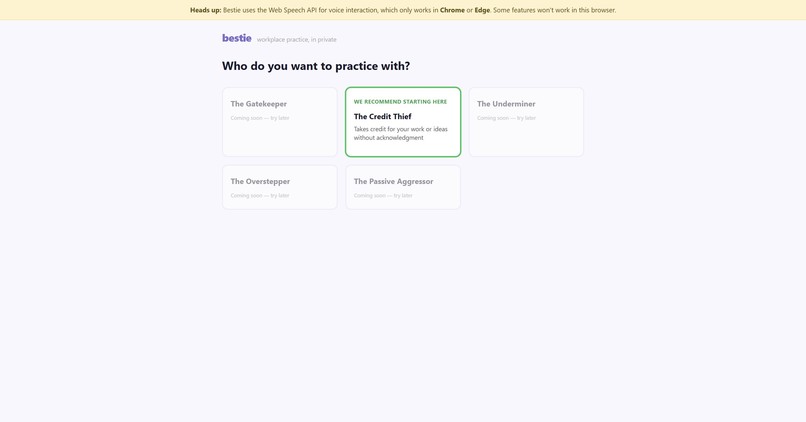
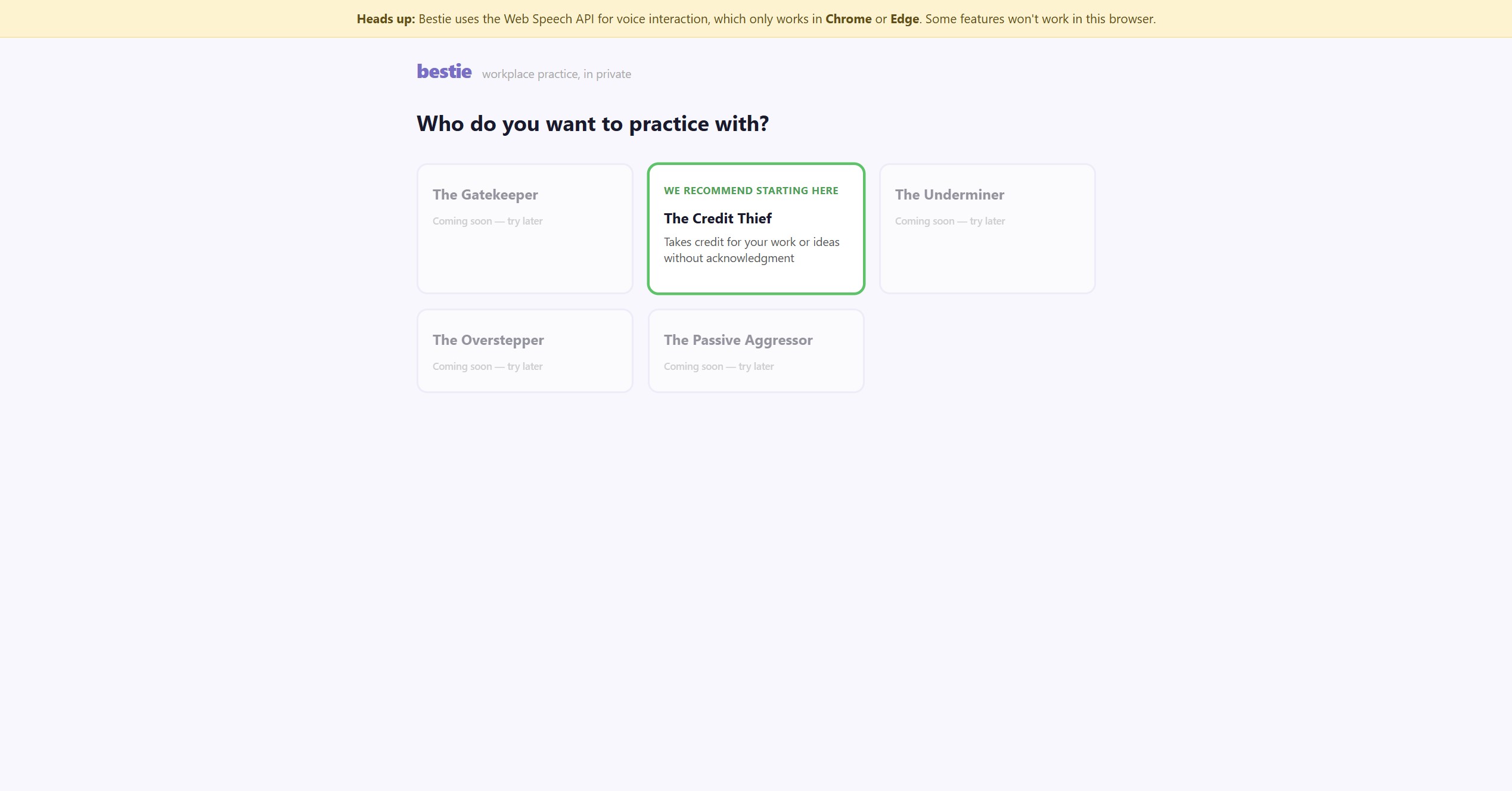
Recommended Archetype is green on the Archetypes Screen of app
-
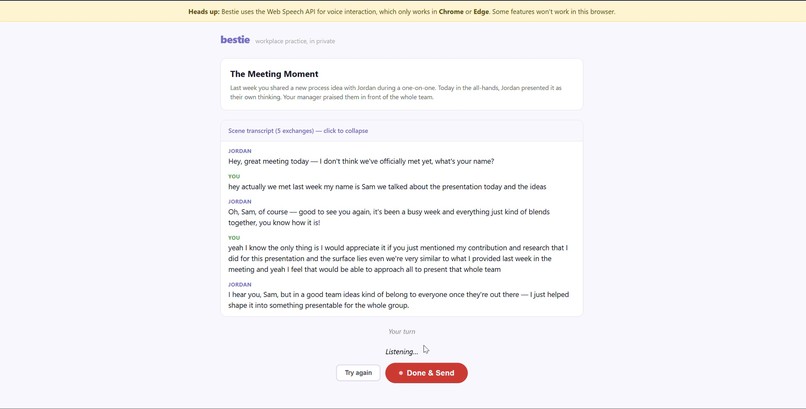
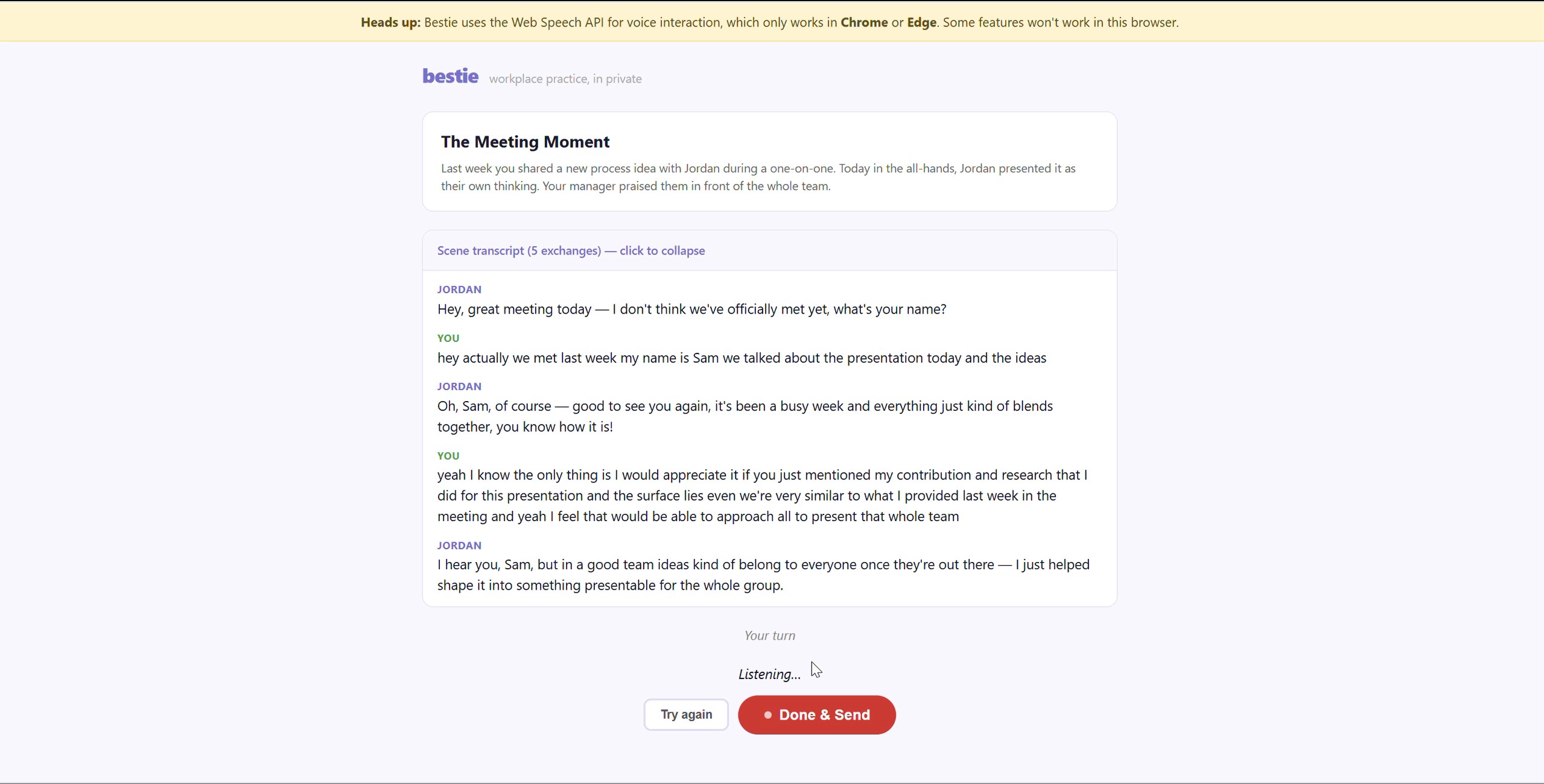
Meeting and real time interaction with the archetype Screen
-
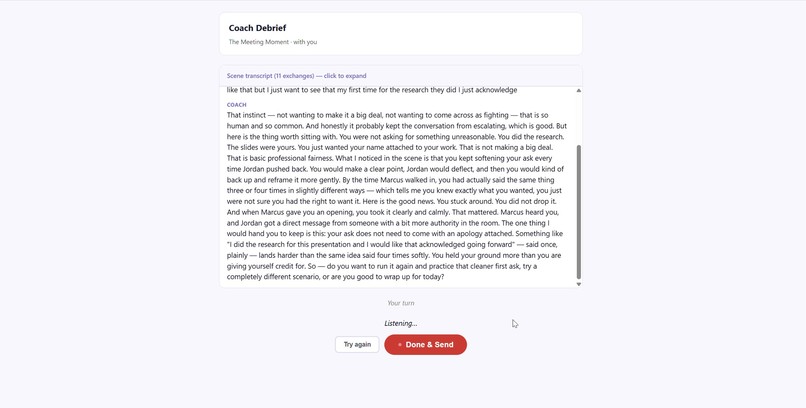
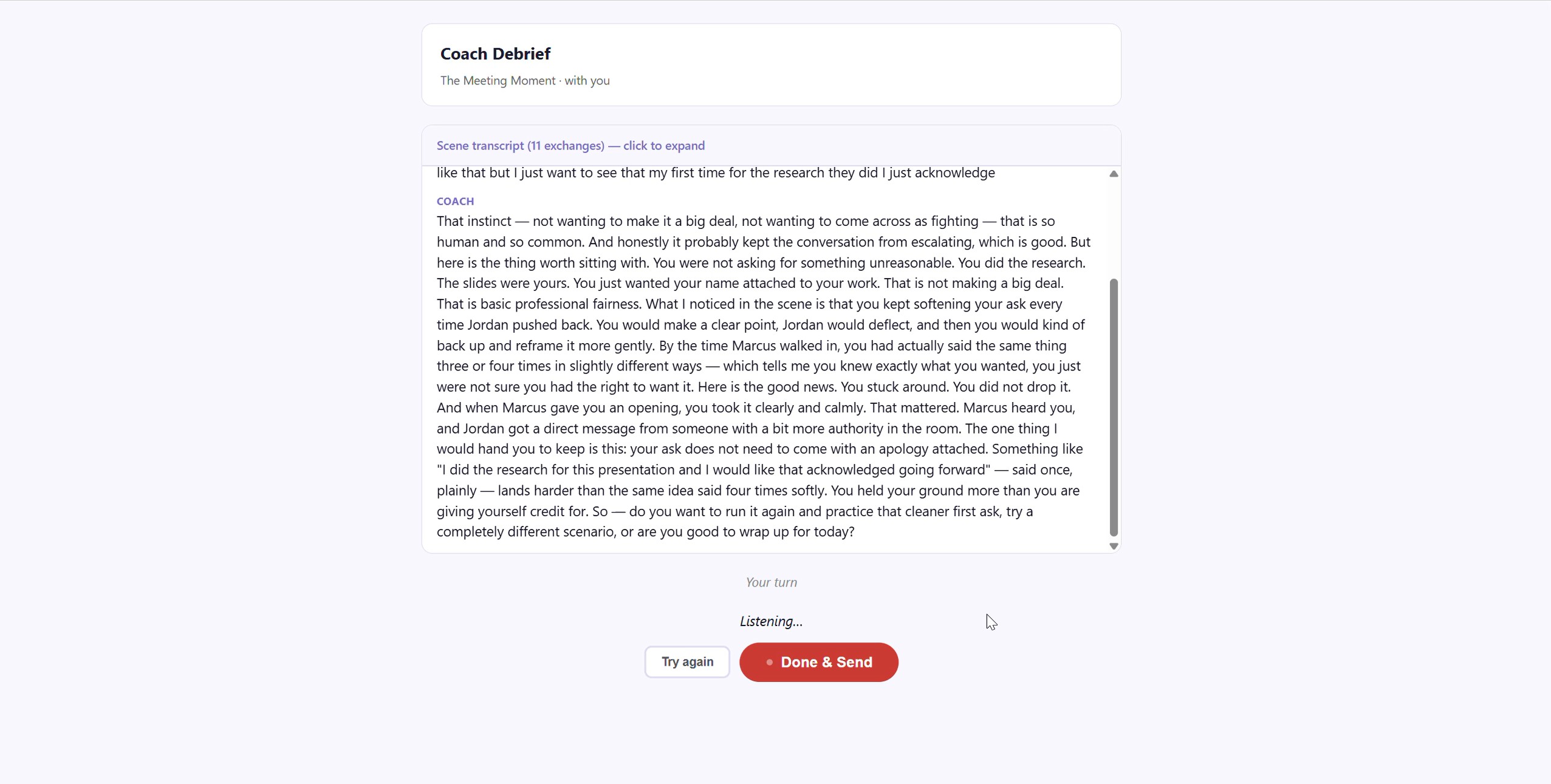
Coach Debrief Screen
Inspiration
Early-career professionals constantly face difficult workplace dynamics — a colleague who takes credit for their ideas, someone who undermines them in meetings, a manager who withholds information. Most people learn to handle these situations the hard way: in the moment, unprepared, with real consequences. I wanted to build a safe space to practice those conversations before they happen. Not by reading about them — by actually having them.
What it does
Bestie is a voice-first role-play coach that helps early-career professionals practice navigating difficult workplace dynamics before those moments happen in real life. You pick a difficult person archetype — a credit thief, an underminer, a gatekeeper — and Bestie puts you in a real conversation with them. You respond by voice, the scene plays out naturally, and then a coach steps in to help you reflect and understand what worked and why. The whole experience is spoken. No forms, no text input, no scoring. Just a conversation that feels real enough to matter.
How I built it
Bestie is a vanilla JavaScript single-page app built with Vite. The role-play is powered by Claude (Anthropic) via direct API calls from the browser. Voice input uses the Web Speech API (Chrome/Edge only) and voice output uses the browser's built-in speech synthesis. All session state lives in memory — closing the tab resets everything. The spec called for ElevenLabs for text-to-speech, but during the build, I switched to the Web Speech API to remove a dependency and keep the flow simpler. The tradeoff is less expressive voices, but it ships, and it works.
Challenges I ran into
The Web Speech API fires onend on every natural pause, not just when the user finishes speaking. Getting the voice input to feel continuous — preserving text across pauses, restarting silently, and only asking the user what to do after 15 seconds of silence — took more iteration than expected. Intent detection in the debrief was also fragile until I used a [OPTIONS] marker in the Claude system prompt to switch between conservative and permissive matching. One thing I didn't anticipate: Claude's responses sometimes came back with markdown formatting and emojis, and the browser's speech synthesis reads those literally. The coach would say "asterisk asterisk great job asterisk asterisk" or "open mouth smile face." Stripping markdown before passing text to the voice fixed it — but I also had to decide what to do with laugh emojis. Deleting them felt wrong, so laugh emojis become "(laughs)" and everything else disappears silently. The transcript still shows the original — only the voice gets the cleaned version.
Accomplishments that I'm proud of
The conversation protocol. Defining upfront that every Claude response would follow a CHARACTER_NAME: dialogue format with [USER_TURN] and SCENE_END markers meant the scene engine had a predictable structure to parse. That decision, made during spec, is what made the whole voice loop reliable. The other thing I'm proud of is that it actually feels like a conversation — the pacing, the silence handling, the way the coach reads the room before giving feedback.
What I learned
Spec first, build second actually works. Having a clear data model, a defined conversation protocol (CHARACTER_NAME: dialogue, [USER_TURN], SCENE_END), and a screen-by-screen acceptance criteria meant that when things broke, I knew exactly where to look. The biggest lesson: voice apps have a lot of invisible states — listening, paused, speaking, waiting — and each one needs to be designed explicitly.
What's next for Bestie
Scenario selection (4 scenarios are built for the Credit Thief, but only the first is reachable), the remaining 4 archetypes, and a text fallback mode for non-Chrome browsers.
Built With
- anthropic-claude
- css
- html
- javascript
- vite
- web-speech-api

Log in or sign up for Devpost to join the conversation.