-
-
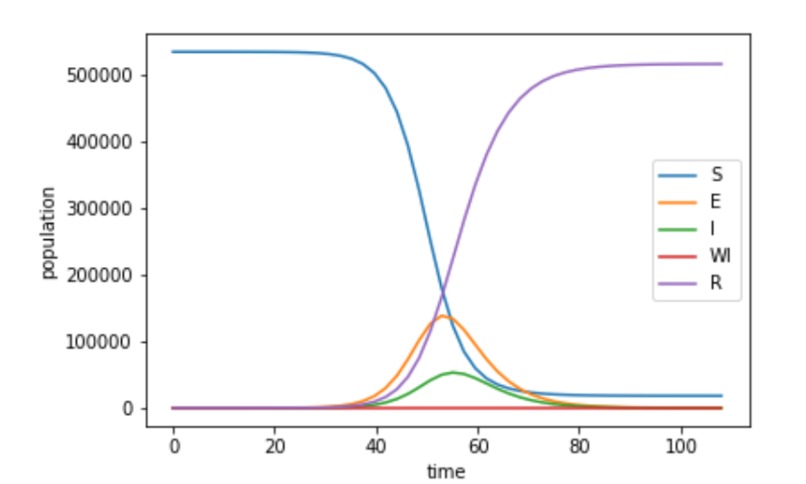
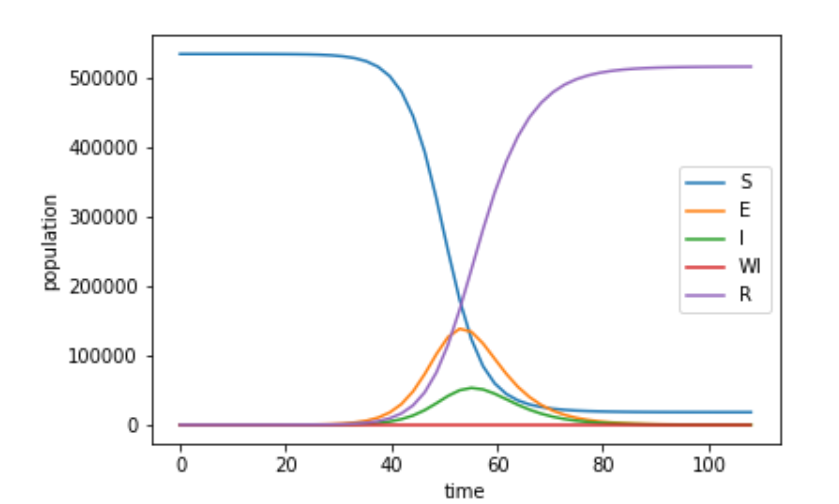
SEIR-Simulation (beispielhaft für 100 Tage)
-
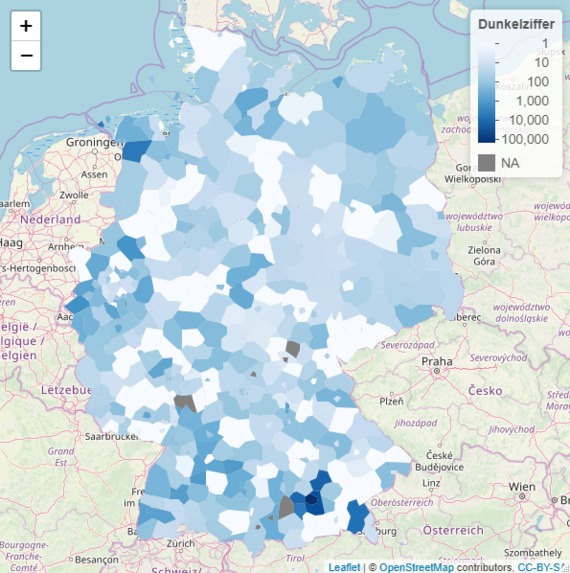
Visualisierung der erste Berechnung der Dunkelziffer anhand unseres SEIR-Modells auf Landkreisebene bzw. kreisfreien Städte

Inspiration
Wir möchten mithelfen, die Infektionsketten zu stoppen. Vielen Menschen ist offenbar noch nicht bewusst, dass die Dunkelziffer der Infizierten groß ist. Daher bewegen sie sich noch immer wie im normalen Alltag. Infizierte Personen können aber auch ohne Symptome und positiven Test bereits ansteckend sein. Diese Personen sind eine große Gefahr. Um diese Menschen zu sensibilisieren, möchten wir die geschätzte Dunkelziffer aufzeigen und anhand von Zahlen greifbar machen. Zusätzlich kann dieser Ansatz Entscheidungsträger*innen helfen, Maßnahmen geografisch zu begrenzen und so die Akzeptanz in der Bevölkerung für diese Maßnahmen zu steigern.
What it does
Unsere Berechnung soll Licht ins Dunkle bringen. Sie soll Auskunft über die Anzahl der infizierten Bürger*innen, die nicht auf COVID-19 getestet wurden - die sogenannte Dunkelziffer - geben. Wir berechnen die Dunkelziffer für die deutschen Landkreise und kreisfreien Städte und visualisieren den Output mithilfe einer Heatmap. Zurzeit sehen wir unsere Berechnungen als pädagogisches Hilfsmittel Bürger*innen über die Wichtigkeit von Präventionsmaßnahmen gegen eine COVID-19-Infektion zu überzeugen. Durch die Angaben auf Landkreisebene, dem eigenen persönlichen Umfeld, wollen wir das abstrakte Konzept der Ausbreitung von Krankheiten greifbarer machen und so Bürger*innen motivieren empfohlene Sicherheitsvorkehrungen ernst zunehmen.
How we built it
Die Dunkelziffer wird mithilfe der offiziell gemeldeten Daten des Robert-Koch-Instituts (https://npgeo-corona-npgeo-de.hub.arcgis.com/datasets/dd4580c810204019a7b8eb3e0b329dd6_0) und eines epidemiologischen Modells (https://github.com/Hackathon-WirvsVirus-0982/Landkreis_Dunkelziffer_Heatmap) bestimmt. Die Dunkelziffer wird berechnet aus der Differenz zwischen den Vorhersagen des epidemiologischen Modells und der aktuell, offiziell gemeldeten Zahl von Infizierten. Annahmen zum epidemiologischen Modell: Wir implementieren zuerst ein einfaches, standardisiertes epidemiologisches SEIR-Modell, dass die Anzahl von Bürger*innen in den Kategorien “susceptible”, “exposed”, “infected” und “recovered” zeitlich vorhersagt. Abschätzung für die Parameter des Modells sind zunächst aus Abschätzungen von COVID-19-Infektionsverläufen aus anderen Länder entnommen. Für jeden Landkreis und jede kreisfreie Städte simulieren wir das Modell mit hilfe der ersten Fallmeldungen des Landkreises bzw. der Stadt. Unser Modell nimmt “normales” Sozialverhalten an und berücksichtigt noch nicht die aktuellen Maßnahmen zum “social distancing”.(siehe What is next)
Challenges we ran into
Das vorliegende Modell profitiert von einer umfassenden Datenmenge. Allerdings sind verwertbare Daten nur begrenzt verfügbar. Lediglich die offiziell gemeldeten Zahlen des RKI können zur Betrachtung herangezogen werden. Deshalb haben wir uns die Frage gestellt, ob wir entweder ein Konzept entwickeln für Daten, die prospektiv in Zukunft von Apps oder erweiterter Erfassung durch Behörden erfasst werden oder ob wir ein vereinfachtes Modell zur Schätzung der Dunkelziffer heranziehen, welches erst einmal nur eine grobe Schätzung liefert, aber mit den vorliegenden Daten berechnet werden kann. Wir haben uns für die zweite Option entschieden mit der Aussicht, dass man aus den beim Hackathon entstandenen Apps in Zukunft Daten erfassen kann, mit denen unser Modell erweitert und die Schätzung verbessert werden kann.
Accomplishments that we are proud of
Dass wir zu 5 geschafft haben, innerhalb von 2 Tagen einen ersten Prototyp mit Output zu entwickeln.
What we learned
SVERWEIS in Excel zu benutzen (mal wieder) Teamwork Organisation inmitten 500 Tabs Motivation ist ansteckend :) ArcGIS
What's next for Schätzung der Dunkelziffer
Als ein mittelfristiges Ziel stellen wir uns vor, die Datenvorhersage zu präzisieren und dadurch nicht nur einen pädagogischen Zweck erfüllen zu können, sondern auch eine Informationsquelle und Unterstützung für die Planung im Gesundheitssektor oder für politische und wirtschaftliche Entscheidungen sein zu können. Diese Ziele wollen wir vor allem dadurch verbessern, indem wir unser einfaches epidemiologische SEIR- Modell durch mehr Komplexität realitätsgetreuer machen. Die Parameter für das Modell sind bisher aus wissenschaftlichen Publikationen zu COVID-19-Verläufen aus anderen Ländern entnommen. Erster Schritt wäre die Parametrisierung mit deutschen Daten. Des Weiteren können Präventionsmaßnahmen wie “social distancing” implementiert werden. Das bisherige Modell geht von normalen Sozialverhalten der Bürger aus. Weitere Daten, die bekannterweise einen Einfluss auf den COVID-19-Krankheitsverlauf, wie Altersverteilung, Geschlecht, aber auch Daten zur regionalen Gegebenheiten (städtisches oder ländliches Zusammenleben) können in das Modell aufgenommen werden, um eine präzisere Aussage machen zu können. Als langfristiges Ziel setzten wir uns nicht nur offiziell bestätigte Daten in ein Modell einzubauen, sondern auch durch die freiwillige Datenabgabe von Bürger*innen die Vorhersage des Modells zu verbessern. Dies wäre durch Kooperationen mit anderen Projekten möglich z. B. Symptom-Tagebuch von Bürger*innen.






Log in or sign up for Devpost to join the conversation.