Inspiration
the american benefits system has 80+ programs across 50 state rulebooks. the people who need it most - single parents, recently laid off workers, immigrants navigating the five-year bar - don't have a lawyer or a social worker on call. they have google and a stack of rejection letters they can't parse. we built benē because the gap between "you qualify" and "you know you qualify" is where billions in unclaimed aid disappears every year.
What it does
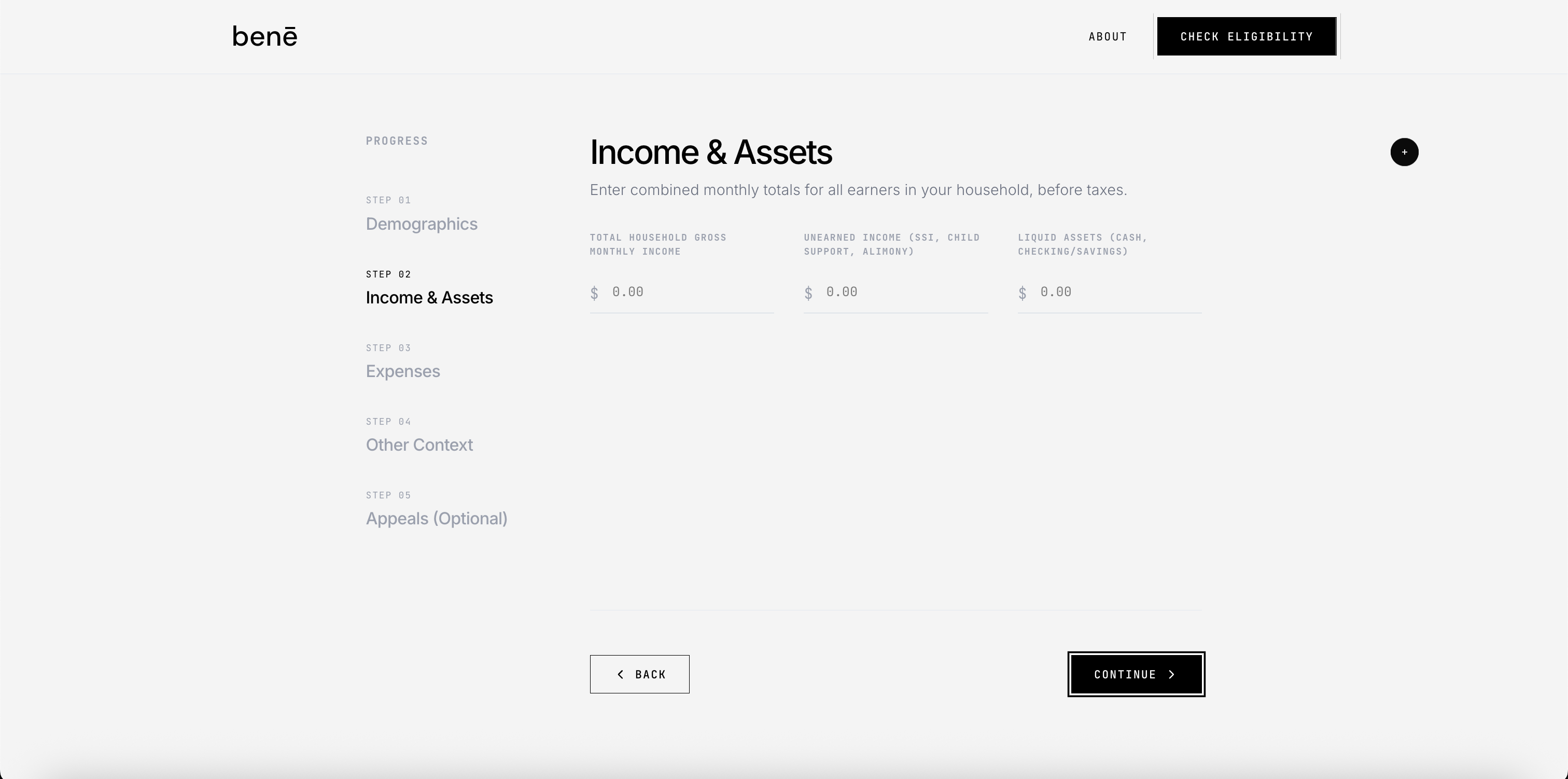
benē is an ai-powered benefits navigator. answer 5 questions: zip code, income, household size, a few status flags, and get a full eligibility breakdown in under 60 seconds.
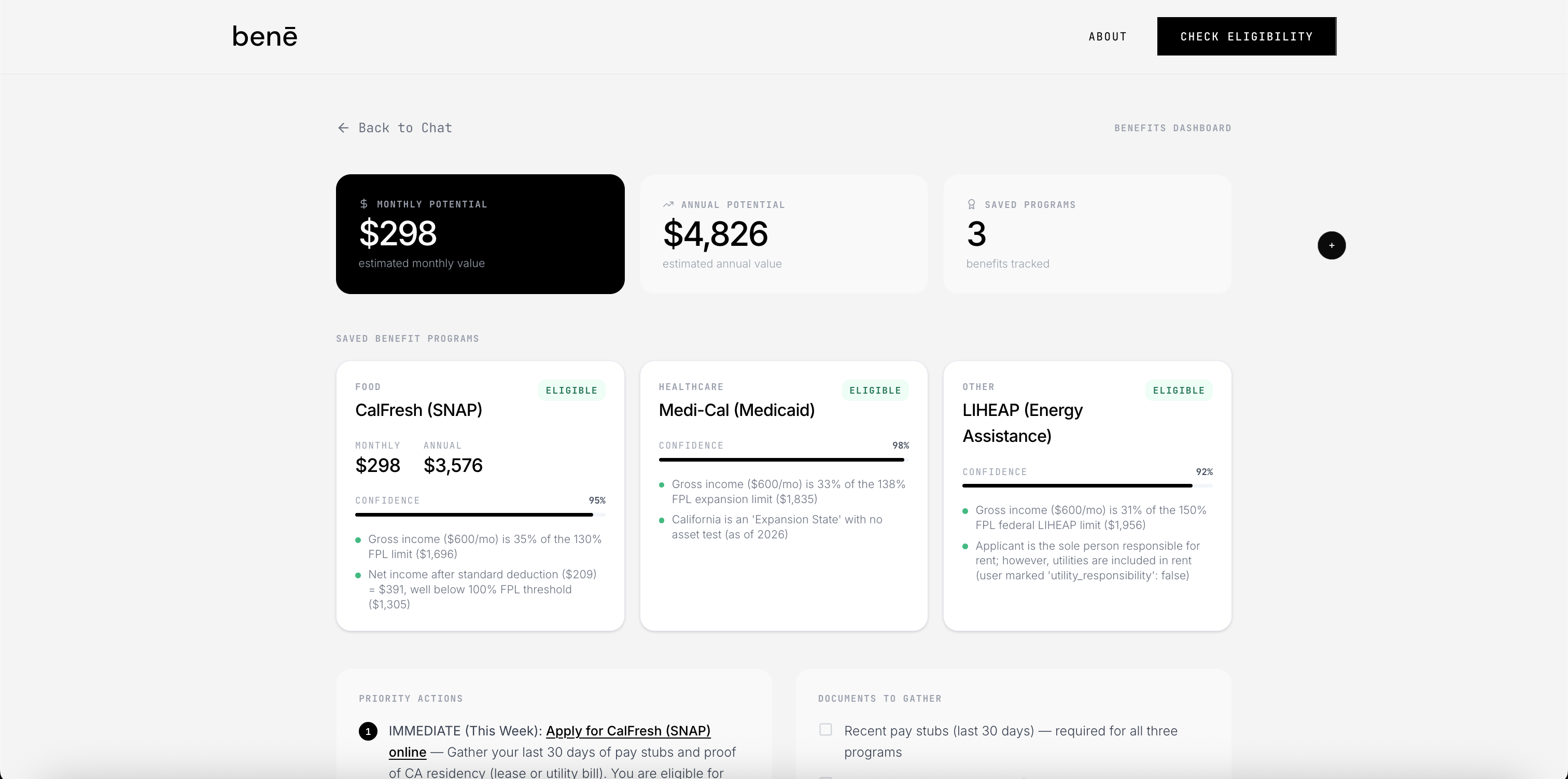
the output isn't a generic list. it's a personalized report with:
- programs ranked by likelihood (eligible → needs review → ineligible)
- estimated monthly and annual dollar value per program
- document checklist to get application-ready
- clickable priority actions with direct links to official portals (benefits.gov, healthcare.gov, studentaid.gov)
- a persistent dashboard where you save the benefits you want to track
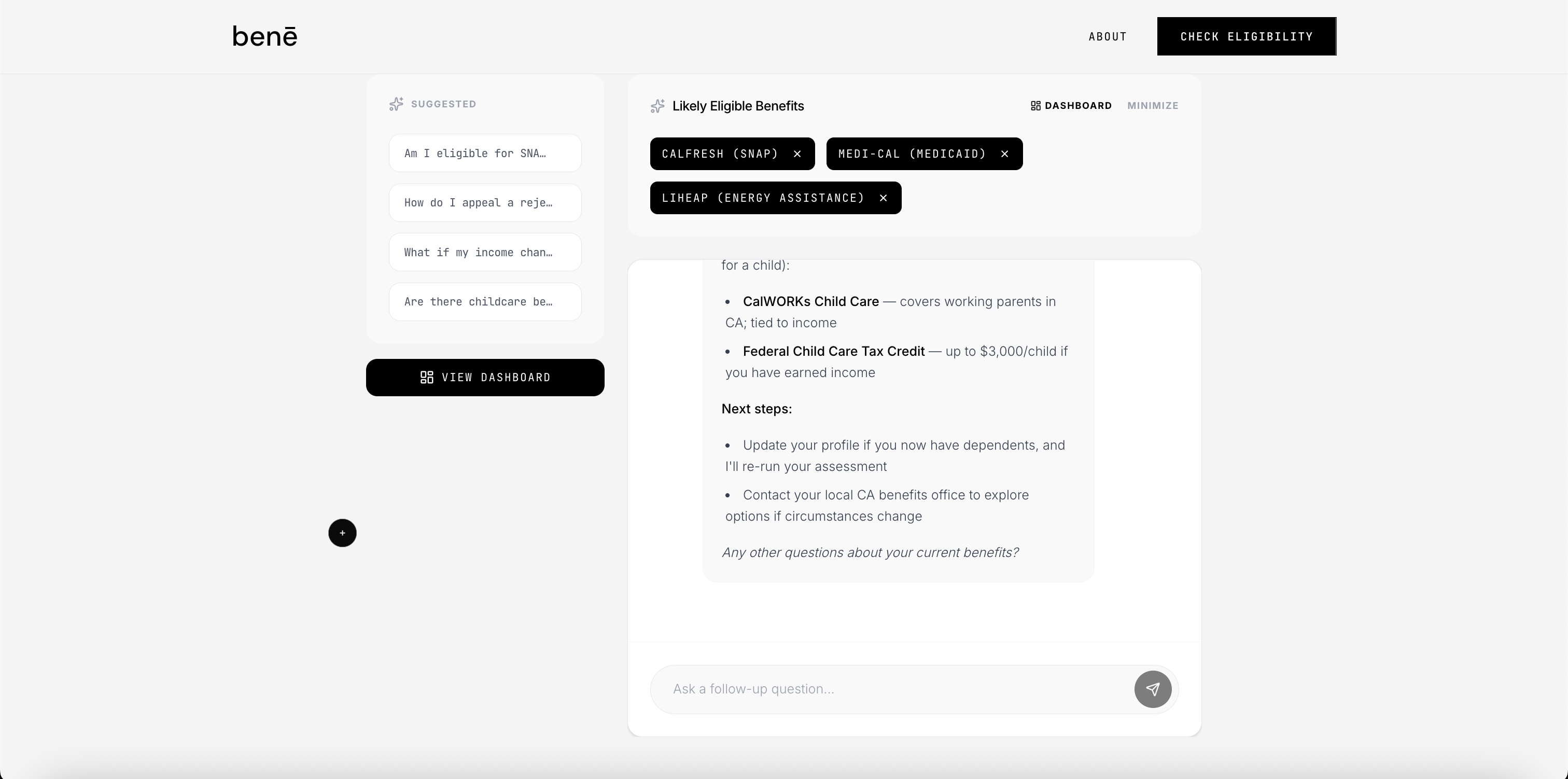
- after the initial evaluation, a follow-up chatbot answers questions about your specific situation and re-evaluates your eligibility in real time if you share new information (income changed, disability status, household size).
How we built it
knowledge base + RAG + LLM use
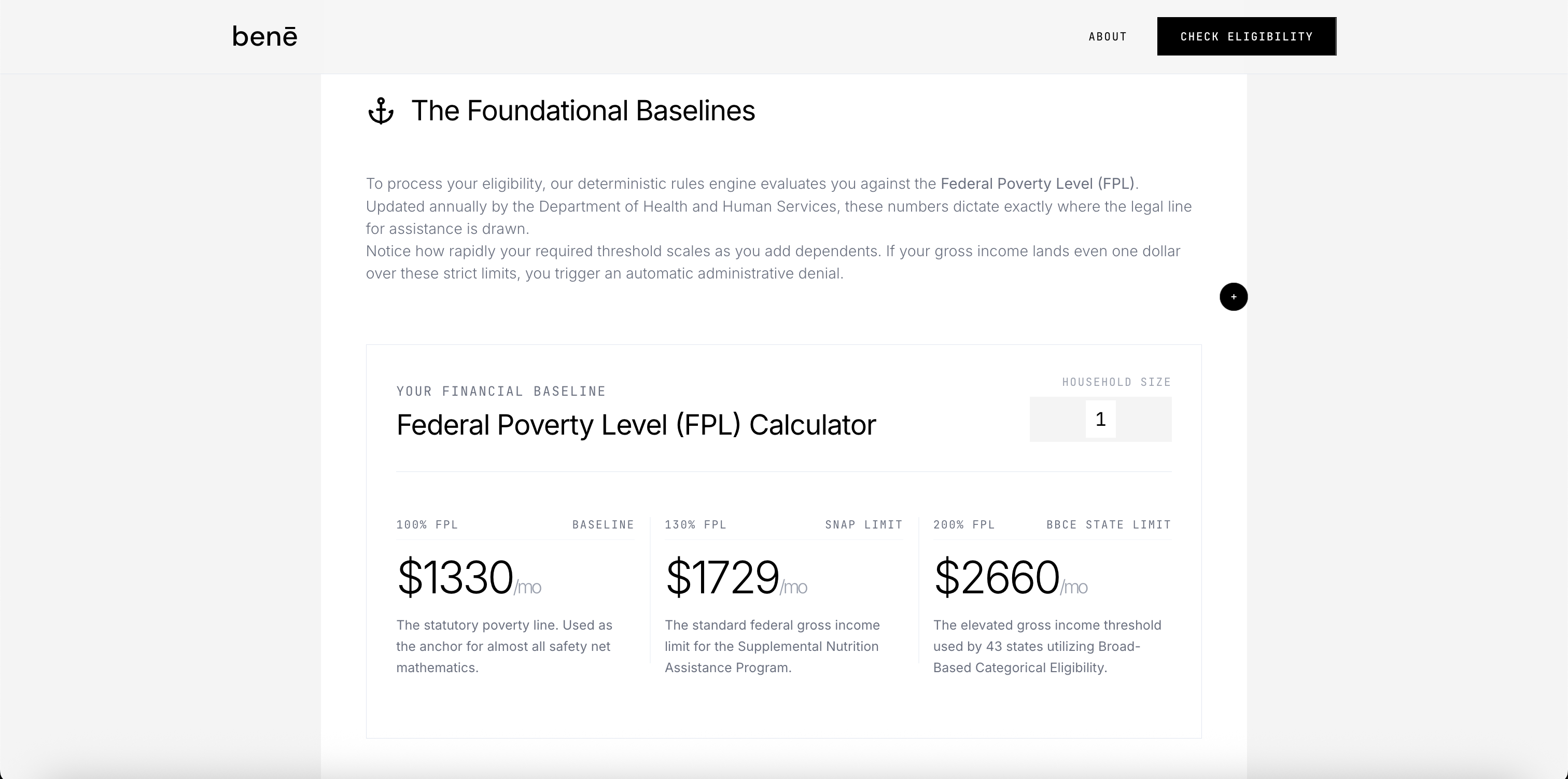
instead of relying on a model's training data (which goes stale), we built a curated knowledge base of 2026 federal benefit guidelines — four .txt files covering food assistance, healthcare, housing/energy, and cash aid (~40KB total). each evaluation injects the full knowledge base as context alongside the user's data. we also have a vector search layer (supabase pgvector + openai text-embedding-3-small) for semantic retrieval of policy chunks when users ask nuanced follow-up questions — so the model is always grounded in current, verified policy thresholds rather than hallucinating outdated limits.
state-specific augmentation sits on top: a zip code to state lookup injects relevant state program aliases (CalFresh, Apple Health, MassHealth) and medicaid expansion status directly into the context, so a user in Texas gets different thresholds than one in Massachusetts.
anthropic tool use
forced tool_choice: { type: "tool", name: "report_eligibility_analysis" } ensures every initial evaluation returns a structured JSON object — programs, confidence scores, monthly benefit estimates, priority actions with embedded hyperlinks, document checklists. this runs on claude haiku which fits within vercel's 60-second serverless timeout where sonnet couldn't.
session-based privacy
no database. all user data lives in sessionStorage and is gone when the tab closes. the anthropic API call is made directly from the next.js edge route — no persistent backend in the critical path.
Challenges we ran into
RAG context size vs. latency tradeoff — our first approach used semantic chunking and retrieved only the most relevant policy sections. the problem: benefits eligibility is deeply interconnected. a query about SNAP pulls in medicaid co-eligibility rules, utility deductions, and household composition edge cases you didn't ask about. we switched to full-context injection (load all 4 knowledge files every time) which trades token cost for correctness. with haiku, this stays within budget and within the timeout.
stale model knowledge — early versions without the knowledge base had claude confidently quoting 2023 SNAP limits. the 2026 thresholds are meaningfully different. embedding the knowledge base was non-negotiable; the model's internal training data isn't a reliable source for program-specific dollar amounts.
vercel 60-second timeout with 40KB of context — sonnet was too slow. switching to haiku solved it, but haiku with tool_choice: auto frequently chose not to call the structured output tool at all, returning plain text instead. we fixed this with forced tool invocation.
household income vs. individual income — the model kept applying single-person thresholds to multi-person households. a family of 4 earning $3,400/month combined IS snap-eligible, but the model kept flagging them ineligible. fixed by renaming the field household_gross_monthly_income (not just income) and embedding the full 2026 FPL table directly in the system prompt with an explicit instruction: "DO NOT use individual income limits when household_size > 1."
teammate pushed a rollback mid-hackathon — claude-3-haiku-20240307 no longer exists. claude-haiku-4-5-20251001 is the current one. every call was silently 404ing and returning "unable to process benefit evaluation." took us longer than we'd like to admit.
ai dumping internal reasoning into the summary field — without explicit schema descriptions, the model filled summary with its full chain-of-thought reasoning. fixed with field-level descriptions in the tool schema capping it to "1-2 sentence plain-language summary for the user."
Accomplishments that we're proud of
eligibility evaluation that accounts for state-specific medicaid expansion, household composition, and prior rejection history, not just income thresholds
zero stored data: genuinely private, not privacy-policy private
priority actions with embedded hyperlinks that render as clickable links in the dashboard
follow-up chat that silently re-evaluates and refreshes the dashboard when you share new information
What we learned
forced tool_use is the only reliable way to get structured json from a model when you need it every single time
haiku is fast enough for production eligibility screening if your context is tight — sonnet is overkill for structured extraction tasks
the hardest part of benefits navigation isn't the rules, it's household definition — SNAP and Medicaid define "household" completely differently, and one wrong assumption breaks the whole calculation
What's next for benē
appeal letter generator for rejection notices, using the rejection reason codes as input
document upload and OCR to auto-fill income verification from paystubs
spanish language support — the populations most likely to leave benefits unclaimed are least likely to be served by english-only tools
state-level waitlist tracking for Section 8 (current wait times by county)
Built With
- claude
- next.js
- python
- railway
- react
- tailwindcss
- typescript
- vercel

Log in or sign up for Devpost to join the conversation.